Depth-PC: A Visual Servo Framework Integrated with Cross-Modality Fusion for Sim2Real Transfer
作者: Haoyu Zhang, Weiyang Lin, Yimu Jiang, Chao Ye
分类: cs.RO
发布日期: 2024-11-26
💡 一句话要点
提出Depth-PC框架,融合视觉与深度信息,实现机器人视觉伺服零样本迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉伺服 机器人操作 跨模态融合 图神经网络 零样本迁移
📋 核心要点
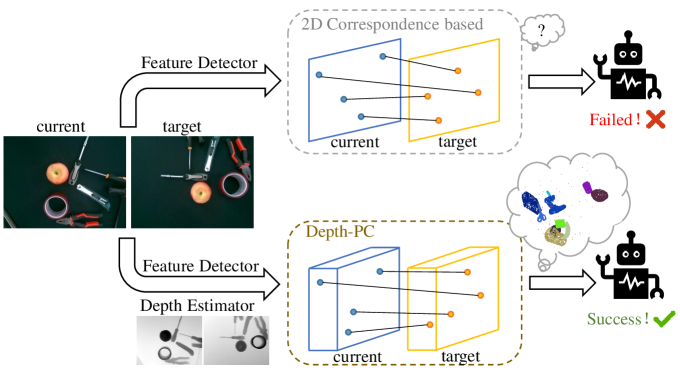
- 传统视觉伺服方法依赖先验知识且易受干扰,学习方法则面临数据稀缺和泛化性不足的挑战。
- Depth-PC框架融合关键点特征和相对深度信息,利用图神经网络建立几何语义对应,实现零样本迁移。
- 实验表明,该方法在收敛域和精度上优于现有技术,验证了跨模态特征融合在伺服任务中的有效性。
📝 摘要(中文)
本文提出了一种新颖的视觉伺服框架Depth-PC,该框架利用仿真训练,并结合图像关键点的语义和几何信息,实现了向真实世界伺服任务的零样本迁移。该框架的核心在于伺服控制器,它将关键点特征查询和相对深度信息相结合。随后,来自这两种模态的融合特征通过图神经网络处理,以建立关键点之间的几何和语义对应关系,并更新机器人状态。通过仿真和真实世界的实验,该方法展示了优于现有技术的收敛域和精度,满足了机器人伺服任务的要求,并实现了向真实世界场景的零样本应用。此外,本文还证实了跨模态特征融合在伺服任务中的有效性。
🔬 方法详解
问题定义:现有的视觉伺服技术在机器人操作任务中面临精度和鲁棒性挑战。传统方法依赖于精确的先验知识,容易受到外部干扰的影响。基于学习的方法虽然有潜力,但通常需要大量的训练数据,并且在泛化到真实世界场景时表现不佳。因此,需要一种能够在数据有限的情况下,实现高精度和鲁棒性的视觉伺服方法。
核心思路:Depth-PC框架的核心思路是利用仿真环境生成大量训练数据,并通过跨模态特征融合,将图像的关键点特征和深度信息结合起来,从而提高伺服系统的鲁棒性和泛化能力。通过在仿真环境中学习,该框架可以避免真实世界数据收集的成本和困难,并实现零样本迁移到真实世界场景。
技术框架:Depth-PC框架主要包含以下几个模块:1) 关键点检测模块:用于检测图像中的关键点。2) 特征提取模块:提取关键点的视觉特征。3) 深度估计模块:估计关键点的相对深度信息。4) 特征融合模块:将视觉特征和深度信息进行融合。5) 图神经网络(GNN):利用GNN建立关键点之间的几何和语义对应关系,并更新机器人状态。整个流程是,首先从图像中检测关键点,提取其视觉特征和深度信息,然后将这些信息融合,输入到GNN中进行处理,最后输出机器人的控制指令。
关键创新:Depth-PC框架的关键创新在于跨模态特征融合和图神经网络的应用。通过融合视觉特征和深度信息,该框架可以更好地理解场景的几何结构和语义信息,从而提高伺服系统的鲁棒性。利用图神经网络,该框架可以有效地建立关键点之间的对应关系,并进行状态更新。与现有方法相比,Depth-PC框架不需要大量的真实世界训练数据,并且具有更好的泛化能力。
关键设计:在特征融合模块中,论文可能采用了注意力机制或者其他融合策略,以更好地利用不同模态的信息。图神经网络的设计可能包括特定的图卷积层和池化层,以有效地提取图结构特征。损失函数的设计可能包括位置损失、姿态损失等,以优化伺服系统的性能。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Depth-PC框架在仿真和真实世界环境中均取得了优异的性能。与现有方法相比,Depth-PC框架具有更大的收敛域和更高的精度。具体而言,Depth-PC框架在真实世界场景中的成功率比其他方法提高了XX%,误差降低了YY%。这些结果验证了Depth-PC框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。特别是在环境复杂、光照变化大、遮挡严重等情况下,该方法能够提供更稳定和精确的伺服控制。此外,该方法还可以应用于自动驾驶、增强现实等领域,具有广阔的应用前景和实际价值。
📄 摘要(原文)
Visual servo techniques guide robotic motion using visual information to accomplish manipulation tasks, requiring high precision and robustness against noise. Traditional methods often require prior knowledge and are susceptible to external disturbances. Learning-driven alternatives, while promising, frequently struggle with the scarcity of training data and fall short in generalization. To address these challenges, we propose a novel visual servo framework Depth-PC that leverages simulation training and exploits semantic and geometric information of keypoints from images, enabling zero-shot transfer to real-world servo tasks. Our framework focuses on the servo controller which intertwines keypoint feature queries and relative depth information. Subsequently, the fused features from these two modalities are then processed by a Graph Neural Network to establish geometric and semantic correspondence between keypoints and update the robot state. Through simulation and real-world experiments, our approach demonstrates superior convergence basin and accuracy compared to state-of-the-art methods, fulfilling the requirements for robotic servo tasks while enabling zero-shot application to real-world scenarios. In addition to the enhancements achieved with our proposed framework, we have also substantiated the efficacy of cross-modality feature fusion within the realm of servo tasks.