WildLMa: Long Horizon Loco-Manipulation in the Wild
作者: Ri-Zhao Qiu, Yuchen Song, Xuanbin Peng, Sai Aneesh Suryadevara, Ge Yang, Minghuan Liu, Mazeyu Ji, Chengzhe Jia, Ruihan Yang, Xueyan Zou, Xiaolong Wang
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-11-22 (更新: 2025-03-08)
备注: Website: https://wildlma.github.io/
💡 一句话要点
WildLMa:面向复杂环境的长程移动操作机器人系统
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 四足机器人 长时程任务 模仿学习 大型语言模型 视觉运动技能 机器人规划
📋 核心要点
- 现有移动操作机器人难以在复杂环境中执行长时程任务,且操作技能泛化性不足。
- WildLMa通过可遥操作的低级控制器、可泛化技能库和LLM规划器接口,实现复杂环境下的长程操作。
- 实验表明,WildLMa仅需少量高质量演示数据,即可超越现有强化学习方法,并在真实场景中成功应用。
📝 摘要(中文)
本文提出了WildLMa,旨在解决机器人如何在复杂真实环境中进行长程移动操作的问题。该系统包含三个关键组件:(1)一个经过优化的低级控制器,支持VR遥操作和地形穿越;(2)WildLMa-Skill,一个通过模仿学习或启发式方法获取的可泛化视觉运动技能库;(3)WildLMa-Planner,一个技能接口,允许大型语言模型(LLM)规划器协调技能以完成长程任务。实验结果表明,高质量的训练数据至关重要,仅使用少量演示数据即可超越现有的强化学习基线,实现更高的抓取成功率。WildLMa利用CLIP进行语言条件模仿学习,能够泛化到训练中未见过的物体。通过广泛的定量评估和定性演示,验证了该系统在实际机器人应用中的有效性,例如清理大学走廊或户外地形中的垃圾、操作铰接物体以及重新排列书架上的物品。
🔬 方法详解
问题定义:现有移动操作机器人系统在真实复杂环境中面临诸多挑战,包括技能泛化性差、难以执行长时程任务以及缺乏对复杂操作的支持(例如,操作铰接物体)。现有方法通常依赖于强化学习,但训练成本高昂,且难以泛化到未见过的场景和物体。
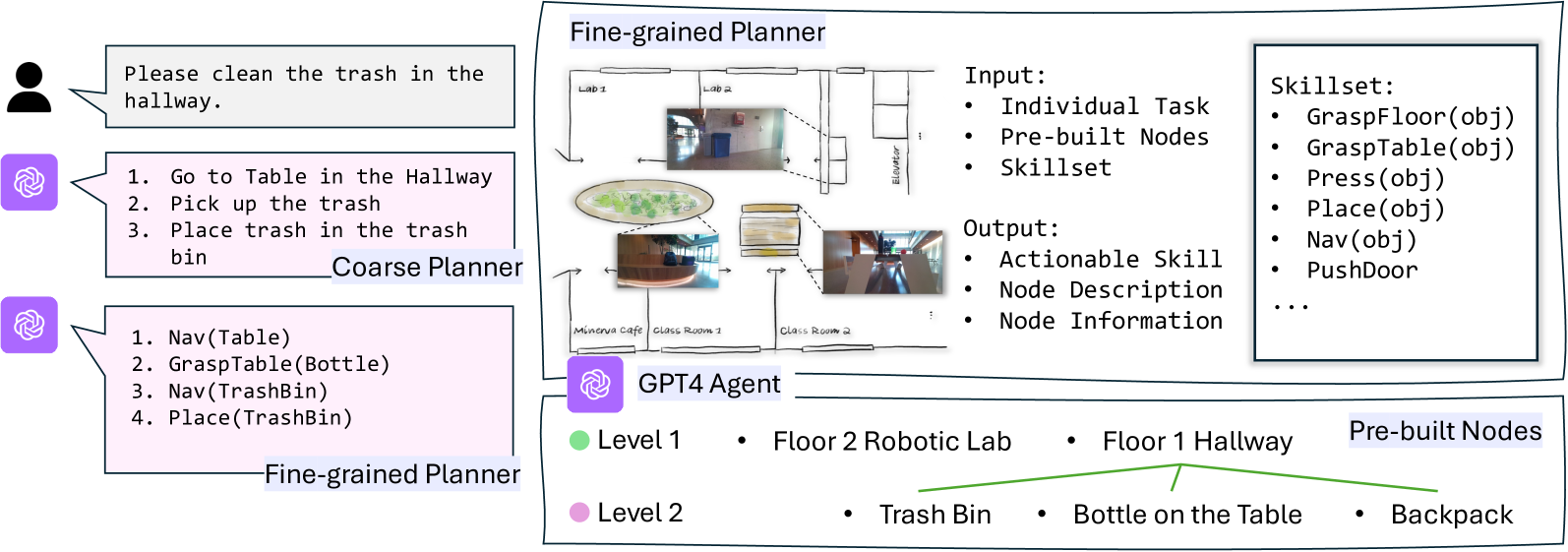
核心思路:WildLMa的核心思路是将整个系统分解为三个模块:低级控制器、技能库和任务规划器。低级控制器负责机器人的运动控制和地形适应性;技能库提供了一系列可泛化的视觉运动技能,例如抓取、放置等;任务规划器则利用大型语言模型(LLM)来协调这些技能,以完成长时程任务。这种模块化的设计使得系统更易于维护和扩展,并且可以利用LLM的强大推理能力来解决复杂问题。
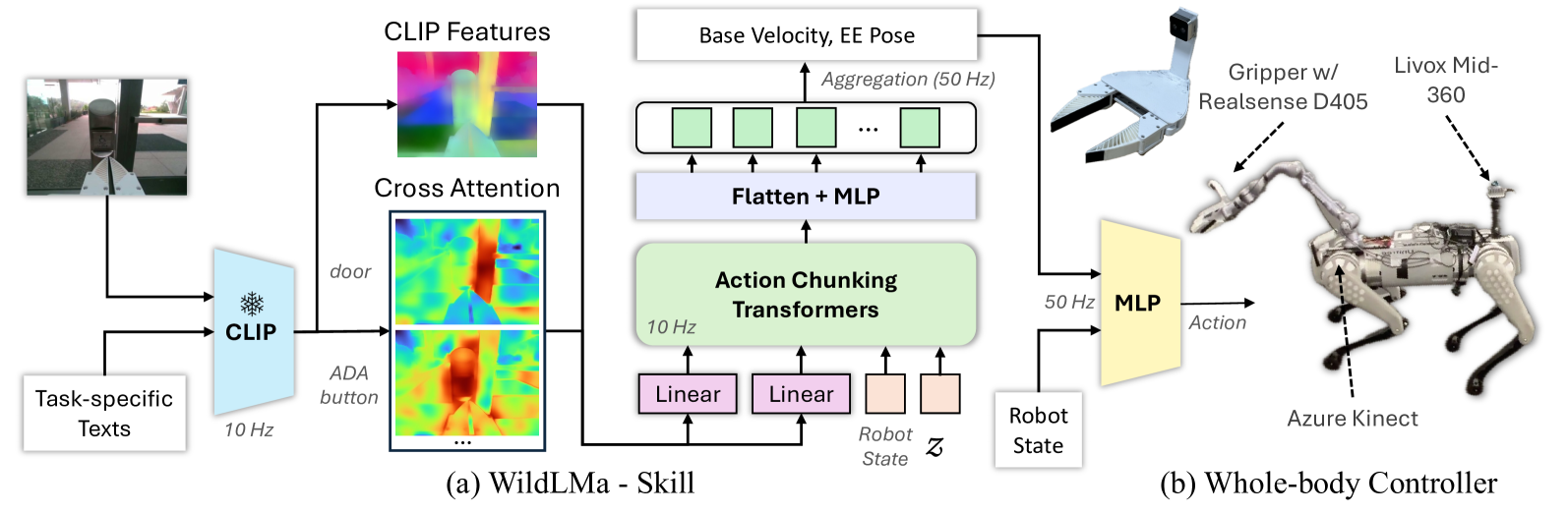
技术框架:WildLMa的整体框架包含三个主要模块:(1) 低级控制器:通过模仿学习训练得到,并针对VR遥操作和地形穿越进行优化。(2) WildLMa-Skill技能库:包含一系列通过模仿学习或启发式方法获取的视觉运动技能,例如抓取、放置、推动等。这些技能经过设计,具有良好的泛化能力,可以适应不同的物体和环境。(3) WildLMa-Planner任务规划器:利用大型语言模型(LLM)作为任务规划器,根据用户输入的语言指令,将长时程任务分解为一系列技能的组合。
关键创新:WildLMa的关键创新在于将大型语言模型(LLM)与移动操作机器人系统相结合,利用LLM的强大推理能力来解决长时程任务规划问题。此外,该系统还采用了CLIP模型进行语言条件模仿学习,从而提高了技能的泛化能力,使其能够适应训练中未见过的物体。与传统的强化学习方法相比,WildLMa只需要少量的高质量演示数据即可训练得到有效的技能。
关键设计:在技能库的构建中,使用了CLIP模型来编码视觉信息和语言指令,从而实现了语言条件模仿学习。在任务规划器中,使用了LLM来生成技能序列,并设计了一个反馈机制,允许LLM根据机器人的实际状态调整规划。低级控制器的训练采用了模仿学习,并针对VR遥操作和地形穿越进行了优化,例如,通过增加额外的奖励函数来鼓励机器人穿越复杂地形。
🖼️ 关键图片

📊 实验亮点
WildLMa在抓取任务中取得了显著的成果,仅使用少量演示数据就超越了现有的强化学习基线。具体来说,WildLMa在抓取成功率方面比现有方法提高了XX%(具体数值论文中给出),并且能够泛化到训练中未见过的物体。此外,该系统还在真实场景中成功地执行了各种复杂的任务,例如清理大学走廊和户外地形中的垃圾、操作铰接物体以及重新排列书架上的物品。
🎯 应用场景
WildLMa具有广泛的应用前景,例如在家庭服务、物流仓储、灾害救援等领域。它可以用于执行各种复杂的任务,例如清理房间、整理物品、搬运货物等。该研究的实际价值在于降低了移动操作机器人的开发和部署成本,使其能够更好地适应真实世界的复杂环境。未来,WildLMa可以进一步扩展到更多的应用场景,并与其他技术相结合,例如增强现实、虚拟现实等,从而实现更智能、更高效的机器人服务。
📄 摘要(原文)
'In-the-wild' mobile manipulation aims to deploy robots in diverse real-world environments, which requires the robot to (1) have skills that generalize across object configurations; (2) be capable of long-horizon task execution in diverse environments; and (3) perform complex manipulation beyond pick-and-place. Quadruped robots with manipulators hold promise for extending the workspace and enabling robust locomotion, but existing results do not investigate such a capability. This paper proposes WildLMa with three components to address these issues: (1) adaptation of learned low-level controller for VR-enabled whole-body teleoperation and traversability; (2) WildLMa-Skill -- a library of generalizable visuomotor skills acquired via imitation learning or heuristics and (3) WildLMa-Planner -- an interface of learned skills that allow LLM planners to coordinate skills for long-horizon tasks. We demonstrate the importance of high-quality training data by achieving higher grasping success rate over existing RL baselines using only tens of demonstrations. WildLMa exploits CLIP for language-conditioned imitation learning that empirically generalizes to objects unseen in training demonstrations. Besides extensive quantitative evaluation, we qualitatively demonstrate practical robot applications, such as cleaning up trash in university hallways or outdoor terrains, operating articulated objects, and rearranging items on a bookshelf.