SplatR : Experience Goal Visual Rearrangement with 3D Gaussian Splatting and Dense Feature Matching
作者: Arjun P S, Andrew Melnik, Gora Chand Nandi
分类: cs.RO, cs.CV
发布日期: 2024-11-21 (更新: 2024-12-17)
💡 一句话要点
SplatR:利用3D高斯溅射和稠密特征匹配实现具身智能中的视觉重排列任务
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉重排列 3D高斯溅射 稠密特征匹配 场景重建 机器人操作 AI2-THOR
📋 核心要点
- 经验目标视觉重排列任务需要智能体准确理解目标状态,现有方法在构建鲁棒的世界模型方面存在不足。
- SplatR利用3D高斯溅射作为场景表示,提供高质量视角,并结合稠密特征匹配实现状态比较。
- 实验结果表明,SplatR在AI2-THOR重排列挑战基准上优于现有方法,提升了重排列任务的性能。
📝 摘要(中文)
具身智能中的经验目标视觉重排列任务是一个基础性挑战,它要求智能体构建一个能够准确捕捉目标状态的鲁棒世界模型。智能体利用该模型将一个被打乱的场景恢复到其原始配置,因此,对世界的精确表示对于成功完成任务至关重要。本文提出了一种新颖的框架,该框架利用3D高斯溅射作为3D场景表示,用于经验目标视觉重排列任务。3D高斯溅射等体渲染场景表示的最新进展,能够快速渲染高质量和照片般逼真的新视角。我们的方法使智能体能够获得重排列任务的当前状态和目标状态的一致视角,从而可以直接在图像空间中比较世界的当前状态和目标状态。为了比较这些视角,我们提出使用一种具有从基础模型中提取的视觉特征的稠密特征匹配方法,利用其更通用的特征表示的优势,从而提高鲁棒性和泛化能力。我们在AI2-THOR重排列挑战基准上验证了我们的方法,并证明了相对于当前最先进方法的改进。
🔬 方法详解
问题定义:经验目标视觉重排列任务旨在让智能体将一个被打乱的场景恢复到其原始状态。现有方法通常依赖于不完整的或低质量的场景表示,导致智能体难以准确理解和比较当前状态与目标状态,从而影响重排列的性能。此外,现有方法在特征提取方面可能缺乏鲁棒性和泛化能力,难以适应复杂和多变的场景。
核心思路:SplatR的核心思路是利用3D高斯溅射(3D Gaussian Splatting)来构建高质量、照片般逼真的3D场景表示。通过3D高斯溅射,智能体可以从任意视角渲染场景,获得一致的视角表示,从而方便比较当前状态和目标状态。此外,SplatR采用稠密特征匹配方法,并使用从预训练基础模型中提取的视觉特征,以提高特征的鲁棒性和泛化能力。
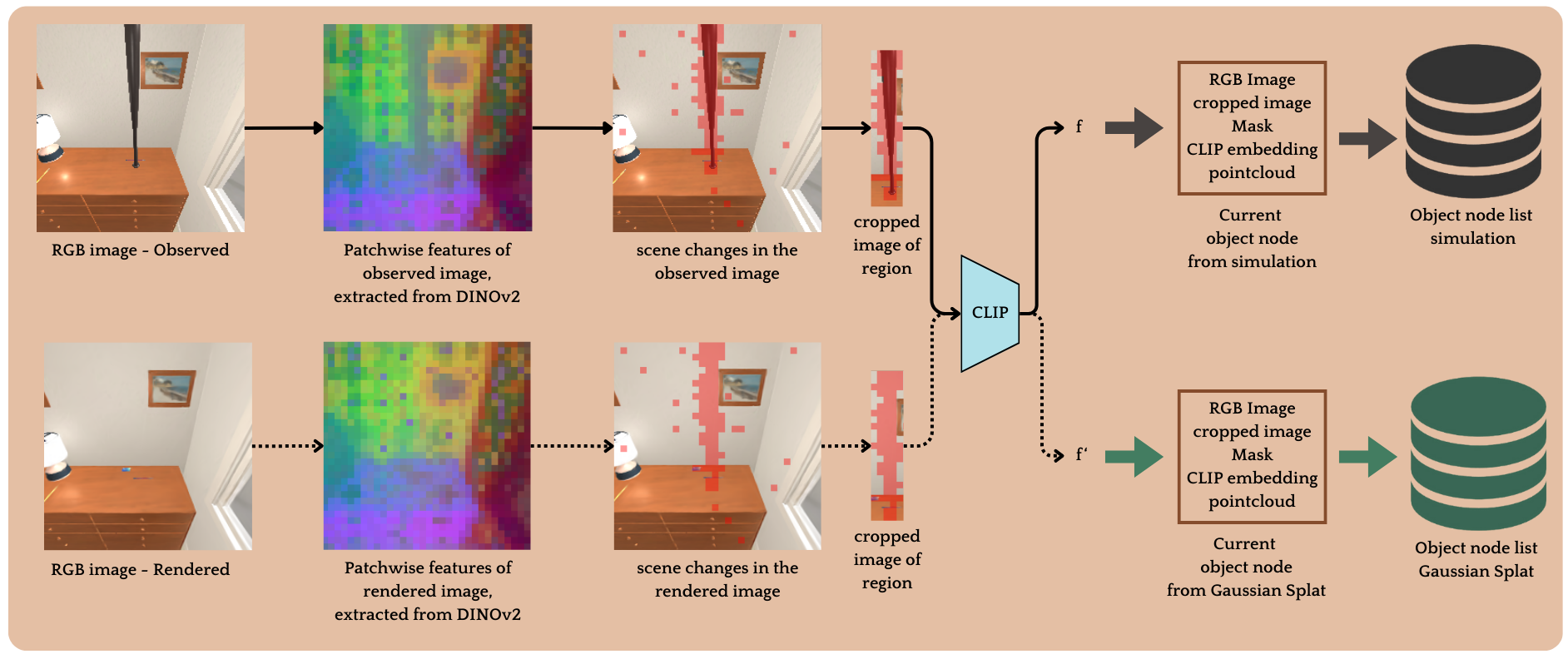
技术框架:SplatR框架主要包含以下几个阶段:1) 场景重建:使用3D高斯溅射对当前场景和目标场景进行重建,生成高质量的3D场景表示。2) 视角渲染:从一致的视角渲染当前场景和目标场景的图像。3) 特征提取:使用预训练的基础模型提取渲染图像的视觉特征。4) 稠密特征匹配:对当前场景和目标场景的特征进行稠密匹配,找到对应关系。5) 重排列动作规划:基于特征匹配结果,规划智能体的重排列动作,将当前场景恢复到目标状态。
关键创新:SplatR的关键创新在于将3D高斯溅射引入到经验目标视觉重排列任务中。与传统的场景表示方法相比,3D高斯溅射能够提供更高质量、更逼真的场景表示,从而提高智能体对场景的理解能力。此外,SplatR使用稠密特征匹配和预训练基础模型提取的视觉特征,增强了特征的鲁棒性和泛化能力。
关键设计:SplatR的关键设计包括:1) 使用高质量的3D高斯溅射进行场景重建,保证场景表示的准确性和逼真度。2) 采用稠密特征匹配方法,能够更精确地找到当前场景和目标场景之间的对应关系。3) 利用预训练的基础模型提取视觉特征,提高特征的鲁棒性和泛化能力。具体的损失函数和网络结构等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文在AI2-THOR重排列挑战基准上验证了SplatR的有效性,实验结果表明,SplatR优于当前最先进的方法。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。但可以确定的是,SplatR在重排列任务的性能上取得了显著的提升。
🎯 应用场景
SplatR在机器人操作、虚拟现实、增强现实等领域具有广泛的应用前景。例如,可以应用于家庭服务机器人,帮助机器人整理房间、摆放物品;也可以应用于虚拟现实游戏中,提供更逼真的场景交互体验。此外,该研究还可以促进具身智能领域的发展,为构建更智能、更自主的机器人系统奠定基础。
📄 摘要(原文)
Experience Goal Visual Rearrangement task stands as a foundational challenge within Embodied AI, requiring an agent to construct a robust world model that accurately captures the goal state. The agent uses this world model to restore a shuffled scene to its original configuration, making an accurate representation of the world essential for successfully completing the task. In this work, we present a novel framework that leverages on 3D Gaussian Splatting as a 3D scene representation for experience goal visual rearrangement task. Recent advances in volumetric scene representation like 3D Gaussian Splatting, offer fast rendering of high quality and photo-realistic novel views. Our approach enables the agent to have consistent views of the current and the goal setting of the rearrangement task, which enables the agent to directly compare the goal state and the shuffled state of the world in image space. To compare these views, we propose to use a dense feature matching method with visual features extracted from a foundation model, leveraging its advantages of a more universal feature representation, which facilitates robustness, and generalization. We validate our approach on the AI2-THOR rearrangement challenge benchmark and demonstrate improvements over the current state of the art methods