Learning Two-agent Motion Planning Strategies from Generalized Nash Equilibrium for Model Predictive Control
作者: Hansung Kim, Edward L. Zhu, Chang Seok Lim, Francesco Borrelli
分类: cs.MA, cs.RO, eess.SY
发布日期: 2024-11-21 (更新: 2025-06-05)
备注: Accepted Proceeding at 2025 Learning for Dynamics and Control Conference (L4DC)
期刊: 283:112-123, 2025
💡 一句话要点
提出IGT-MPC算法,通过学习广义纳什均衡策略解决多智能体运动规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 多智能体系统 运动规划 模型预测控制 博弈论 广义纳什均衡 机器学习 价值函数学习 分散式控制
📋 核心要点
- 传统多智能体运动规划方法难以有效处理智能体间的复杂交互,尤其是在竞争或合作场景下。
- IGT-MPC通过学习广义纳什均衡下的价值函数,使智能体在MPC中能隐式考虑其他智能体的行为,从而优化自身策略。
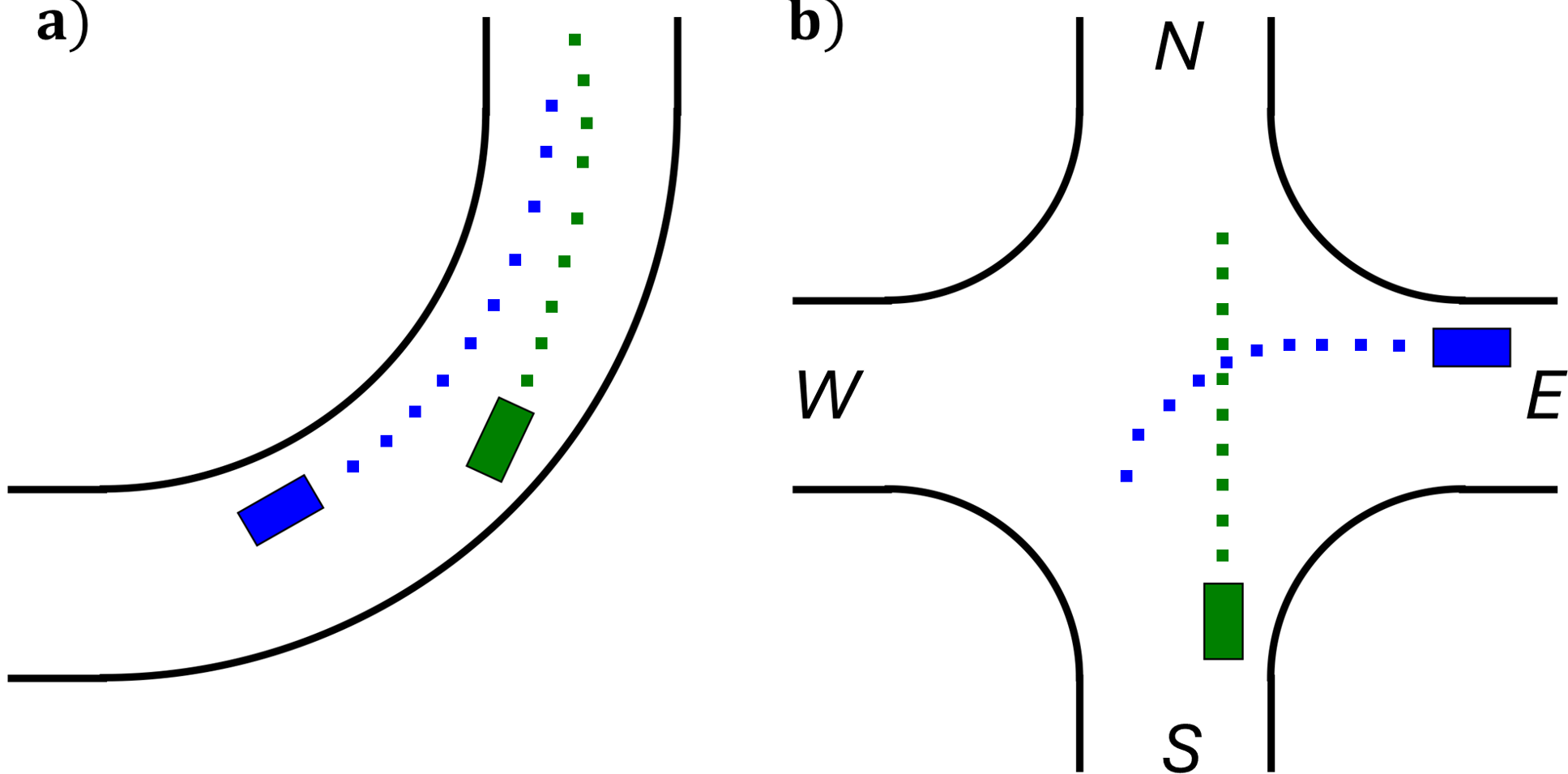
- 实验表明,IGT-MPC在车辆竞赛和交叉口导航等场景中,能涌现出竞争和协作行为,验证了其有效性。
📝 摘要(中文)
本文提出了一种隐式博弈论模型预测控制(IGT-MPC)算法,用于分散式双智能体运动规划。该算法使用学习到的价值函数预测博弈论交互结果,并将其作为模型预测控制(MPC)框架中的终端代价函数,引导智能体隐式地考虑与其他智能体的交互,从而最大化其奖励。该方法适用于竞争性和合作性多智能体运动规划问题,这些问题被建模为约束动态博弈。给定一个约束动态博弈,我们随机采样初始条件并求解广义纳什均衡(GNE),以生成GNE解的数据集,并从GNE计算每个博弈论交互的奖励结果。该数据用于训练一个简单的神经网络来预测奖励结果,我们将其用作MPC方案中的终端代价函数。我们在诸如双车头对头竞赛和无信号交叉口导航等场景中,展示了使用IGT-MPC涌现的竞争和协调行为。IGT-MPC提供了一种将机器学习和博弈论推理集成到基于模型的分散式多智能体运动规划中的新方法。
🔬 方法详解
问题定义:论文旨在解决多智能体运动规划问题,尤其是在存在竞争或合作关系时,如何让智能体有效地规划自己的运动轨迹。现有方法,如传统MPC,难以直接处理智能体间的复杂交互,需要显式地建模其他智能体的行为,计算复杂度高,且难以保证纳什均衡。
核心思路:核心思路是利用机器学习来预测博弈论交互的结果,并将其作为MPC的终端代价函数。通过学习广义纳什均衡(GNE)下的价值函数,智能体可以在规划过程中隐式地考虑其他智能体的行为,从而避免了显式建模和复杂计算。
技术框架:IGT-MPC算法的整体框架如下:1. 数据生成:针对给定的约束动态博弈,随机采样初始条件,求解广义纳什均衡(GNE),得到GNE解的数据集。2. 价值函数学习:利用GNE解的数据集训练一个神经网络,用于预测博弈论交互的奖励结果。3. MPC规划:在MPC框架中,使用学习到的价值函数作为终端代价函数,引导智能体进行运动规划。
关键创新:最重要的创新点是将机器学习和博弈论推理集成到模型预测控制中。通过学习GNE下的价值函数,智能体可以在MPC中隐式地考虑其他智能体的行为,从而实现分散式的多智能体运动规划。与传统方法相比,IGT-MPC避免了显式建模其他智能体的行为,降低了计算复杂度,并能更好地处理智能体间的复杂交互。
关键设计:价值函数采用简单的神经网络结构,输入是智能体的状态,输出是预测的奖励结果。损失函数采用均方误差损失函数,用于衡量预测奖励与实际奖励之间的差距。MPC的控制周期和预测步长需要根据具体场景进行调整,以保证规划的实时性和有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IGT-MPC算法在双车头对头竞赛和无信号交叉口导航等场景中,能够涌现出竞争和协作行为。例如,在双车头对头竞赛中,智能体能够学习到避免碰撞并尽可能快地到达终点的策略。在无信号交叉口导航中,智能体能够学习到相互协调,安全通过交叉口的策略。这些结果验证了IGT-MPC算法在多智能体运动规划中的有效性。
🎯 应用场景
IGT-MPC算法可应用于各种多智能体运动规划场景,如自动驾驶车辆的协同驾驶、无人机的编队飞行、机器人的协作任务等。该方法能够提高多智能体系统的效率和安全性,并为实现更智能、更自主的多智能体系统提供技术支持。未来,该方法有望应用于更复杂的动态博弈场景,例如交通流量优化、资源分配等。
📄 摘要(原文)
We introduce an Implicit Game-Theoretic MPC (IGT-MPC), a decentralized algorithm for two-agent motion planning that uses a learned value function that predicts the game-theoretic interaction outcomes as the terminal cost-to-go function in a model predictive control (MPC) framework, guiding agents to implicitly account for interactions with other agents and maximize their reward. This approach applies to competitive and cooperative multi-agent motion planning problems which we formulate as constrained dynamic games. Given a constrained dynamic game, we randomly sample initial conditions and solve for the generalized Nash equilibrium (GNE) to generate a dataset of GNE solutions, computing the reward outcome of each game-theoretic interaction from the GNE. The data is used to train a simple neural network to predict the reward outcome, which we use as the terminal cost-to-go function in an MPC scheme. We showcase emerging competitive and coordinated behaviors using IGT-MPC in scenarios such as two-vehicle head-to-head racing and un-signalized intersection navigation. IGT-MPC offers a novel method integrating machine learning and game-theoretic reasoning into model-based decentralized multi-agent motion planning.