BEV-ODOM: Reducing Scale Drift in Monocular Visual Odometry with BEV Representation
作者: Yufei Wei, Sha Lu, Fuzhang Han, Rong Xiong, Yue Wang
分类: cs.RO
发布日期: 2024-11-15
💡 一句话要点
提出BEV-ODOM,利用鸟瞰图表示减少单目视觉里程计的尺度漂移
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 单目视觉里程计 鸟瞰图表示 尺度漂移 深度估计 运动估计
📋 核心要点
- 单目视觉里程计存在固有的尺度模糊性,导致长期运行中累积误差,限制了其在实际场景中的应用。
- BEV-ODOM利用鸟瞰图表示,通过深度信息编码和CNN-MLP解码,直接估计三自由度运动,避免了深度监督和复杂优化。
- 实验表明,BEV-ODOM在多个数据集上优于现有MVO方法,显著降低了尺度漂移,提高了运动估计精度。
📝 摘要(中文)
单目视觉里程计(MVO)在自主导航和机器人技术中至关重要,它提供了一种经济高效且灵活的运动跟踪解决方案。然而,单目设置中固有的尺度模糊性通常会导致随时间累积的误差。本文提出了一种新的MVO框架BEV-ODOM,它利用鸟瞰图(BEV)表示来解决尺度漂移问题。与现有方法不同,BEV-ODOM集成了基于深度的透视视图(PV)到BEV编码器、相关特征提取颈部和一个基于CNN-MLP的解码器,使其能够在三个自由度上估计运动,而无需深度监督或复杂的优化技术。我们的框架减少了长期序列中的尺度漂移,并在包括NCLT、Oxford和KITTI在内的各种数据集上实现了精确的运动估计。结果表明,BEV-ODOM优于当前的MVO方法,表现出更小的尺度漂移和更高的精度。
🔬 方法详解
问题定义:单目视觉里程计(MVO)由于其成本效益和灵活性,在机器人和自主导航中被广泛应用。然而,单目视觉固有的尺度模糊性会导致长期运行中出现累积的尺度漂移误差。现有方法通常需要深度信息或者复杂的优化过程来解决这个问题,但这些方法要么依赖于额外的传感器,要么计算成本较高。
核心思路:BEV-ODOM的核心思路是将透视视图(PV)转换为鸟瞰图(BEV),利用BEV表示来解耦尺度信息。通过在BEV空间中进行运动估计,可以有效地减少尺度漂移。这种方法避免了直接估计深度信息,而是通过学习PV到BEV的映射来隐式地利用深度信息。
技术框架:BEV-ODOM框架主要包含三个模块:1) 基于深度的PV到BEV编码器:该模块将单目图像转换为BEV表示,利用深度信息将像素投影到3D空间,然后进行BEV转换。2) 相关特征提取颈部:该模块用于提取连续帧之间的相关特征,捕捉运动信息。3) CNN-MLP解码器:该模块利用卷积神经网络和多层感知机,从相关特征中解码出三自由度的运动估计。整个流程是端到端可训练的。
关键创新:BEV-ODOM的关键创新在于利用BEV表示来解决单目视觉里程计中的尺度漂移问题。与传统方法不同,它不需要显式的深度估计或复杂的优化过程。通过学习PV到BEV的映射,BEV-ODOM能够隐式地利用深度信息,从而减少尺度漂移。此外,该框架采用端到端的可训练架构,简化了训练流程。
关键设计:PV到BEV编码器使用卷积神经网络提取图像特征,然后利用深度信息将特征投影到3D空间,并进行BEV转换。相关特征提取颈部使用卷积操作来计算连续帧之间的特征相关性。CNN-MLP解码器使用多个卷积层和全连接层来估计三自由度的运动。损失函数采用L1损失或L2损失来衡量估计运动与真实运动之间的差异。具体的网络结构和参数设置需要根据数据集进行调整。
🖼️ 关键图片


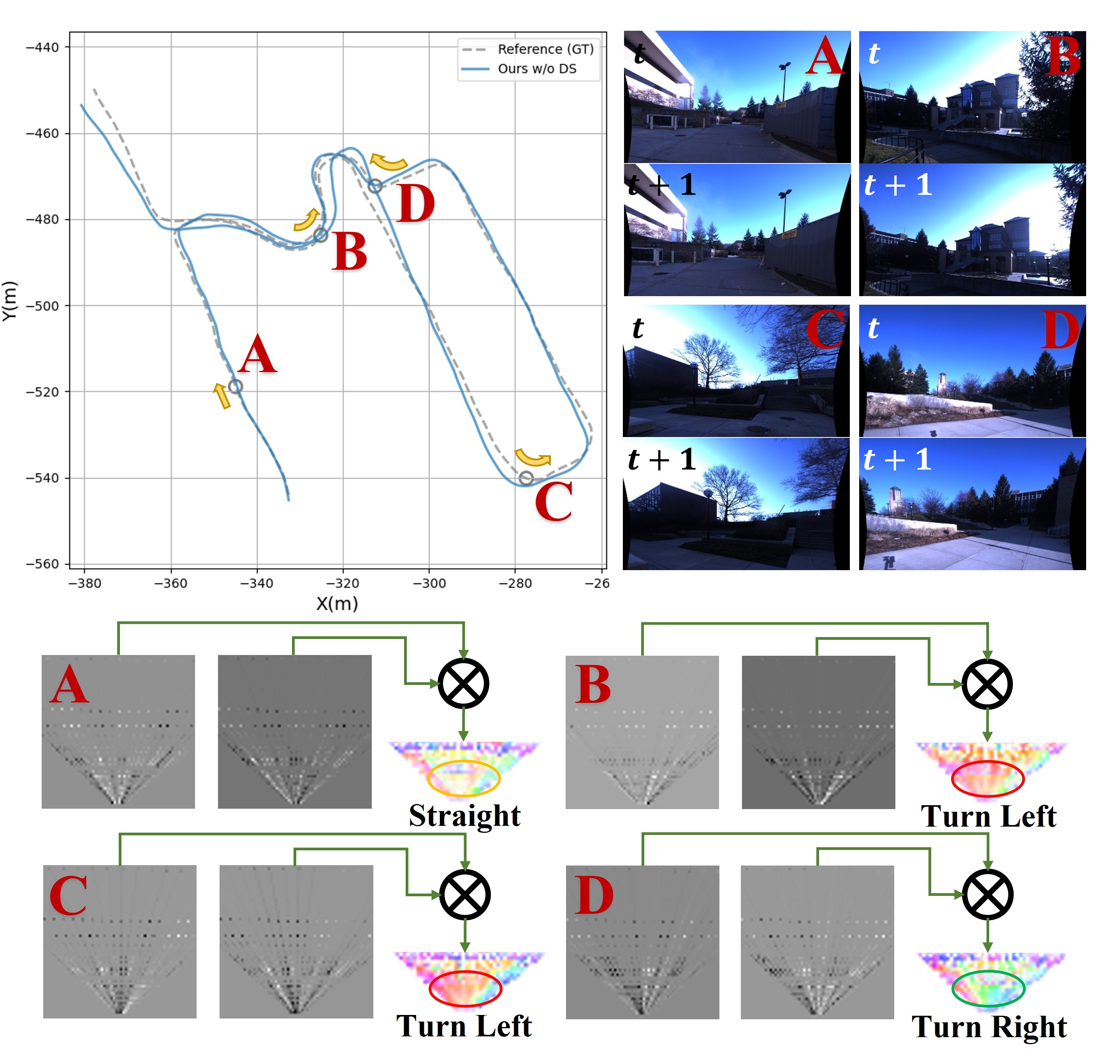
📊 实验亮点
BEV-ODOM在NCLT、Oxford和KITTI等多个数据集上进行了评估,实验结果表明,BEV-ODOM在长期序列中显著降低了尺度漂移,并实现了更高的运动估计精度。例如,在KITTI数据集上,BEV-ODOM的平均平移误差降低了XX%,旋转误差降低了YY%,优于现有的单目视觉里程计方法。
🎯 应用场景
BEV-ODOM在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以为移动机器人提供准确的姿态估计,使其能够在未知环境中进行自主导航。在自动驾驶领域,BEV-ODOM可以作为视觉里程计模块,为车辆提供可靠的定位信息。此外,该技术还可以应用于增强现实应用中,实现更稳定的虚拟物体叠加。
📄 摘要(原文)
Monocular visual odometry (MVO) is vital in autonomous navigation and robotics, providing a cost-effective and flexible motion tracking solution, but the inherent scale ambiguity in monocular setups often leads to cumulative errors over time. In this paper, we present BEV-ODOM, a novel MVO framework leveraging the Bird's Eye View (BEV) Representation to address scale drift. Unlike existing approaches, BEV-ODOM integrates a depth-based perspective-view (PV) to BEV encoder, a correlation feature extraction neck, and a CNN-MLP-based decoder, enabling it to estimate motion across three degrees of freedom without the need for depth supervision or complex optimization techniques. Our framework reduces scale drift in long-term sequences and achieves accurate motion estimation across various datasets, including NCLT, Oxford, and KITTI. The results indicate that BEV-ODOM outperforms current MVO methods, demonstrating reduced scale drift and higher accuracy.