Offline Adaptation of Quadruped Locomotion using Diffusion Models
作者: Reece O'Mahoney, Alexander L. Mitchell, Wanming Yu, Ingmar Posner, Ioannis Havoutis
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-11-13 (更新: 2025-06-03)
💡 一句话要点
提出基于扩散模型的四足机器人离线步态自适应方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 四足机器人 运动控制 扩散模型 离线学习 步态自适应
📋 核心要点
- 现有四足机器人运动方法难以兼顾多技能学习和训练后的离线步态自适应。
- 利用无分类器引导扩散模型,从无标签数据集中提取目标条件行为,实现步态自适应。
- 该方法与多技能策略兼容,计算开销小,可在机器人板载CPU上运行,并在ANYmal机器人上验证。
📝 摘要(中文)
本文提出了一种基于扩散模型的四足机器人运动方法,该方法同时解决了学习和插值多个技能以及在训练后离线适应新的运动行为的局限性。这是第一个将无分类器引导扩散应用于四足机器人运动的框架,并通过从最初未标记的数据集中提取目标条件行为来证明其有效性。我们表明,这些能力与多技能策略兼容,并且只需进行少量修改和最小的计算开销即可应用,即完全在机器人的板载CPU上运行。我们通过在ANYmal四足机器人平台上进行的硬件实验验证了我们方法的有效性。
🔬 方法详解
问题定义:现有的四足机器人运动控制方法通常需要在多个预定义的技能之间进行插值,或者难以在训练完成后适应新的运动行为。这限制了机器人在复杂和变化环境中的应用,痛点在于缺乏一种能够灵活学习和适应新步态的离线方法。
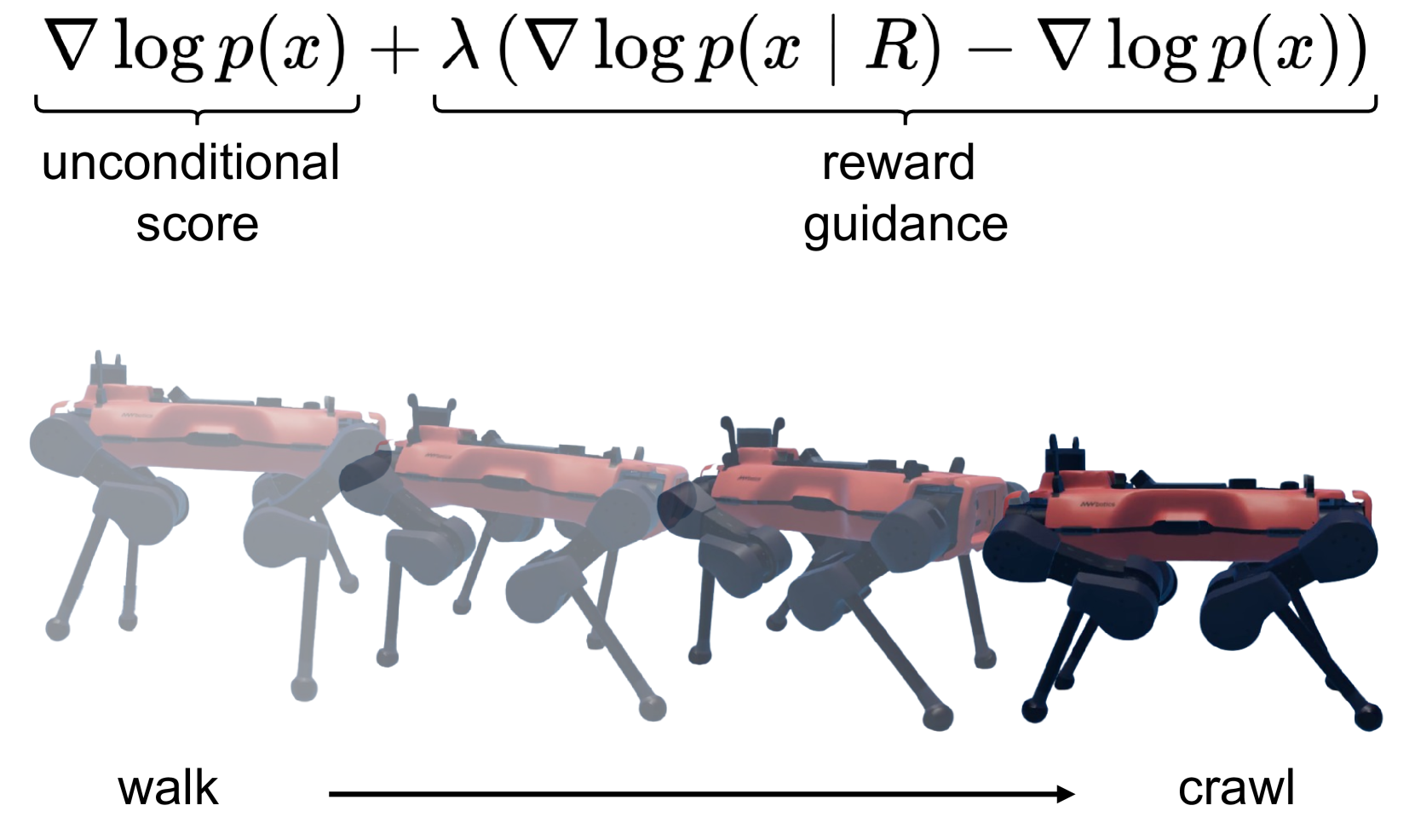
核心思路:本文的核心思路是利用扩散模型强大的生成能力,从无标签的运动数据中学习潜在的运动模式,并通过无分类器引导的方式,根据目标条件(例如速度、方向)生成相应的运动轨迹。这种方法允许机器人在训练后,仅通过调整目标条件,即可适应新的运动需求。
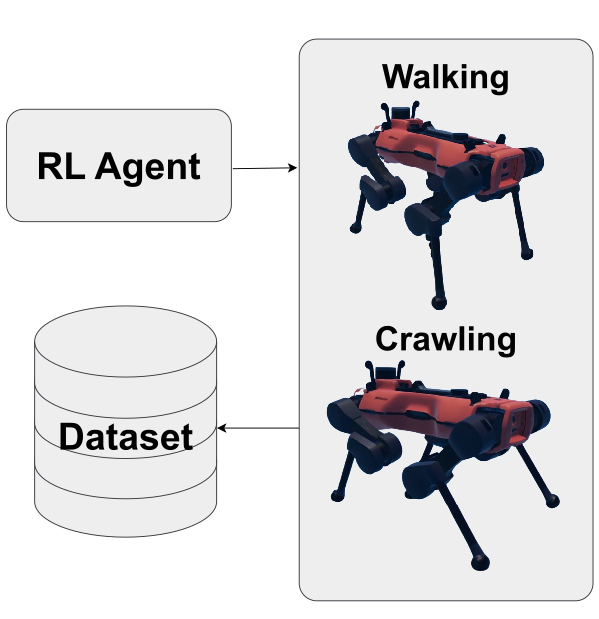
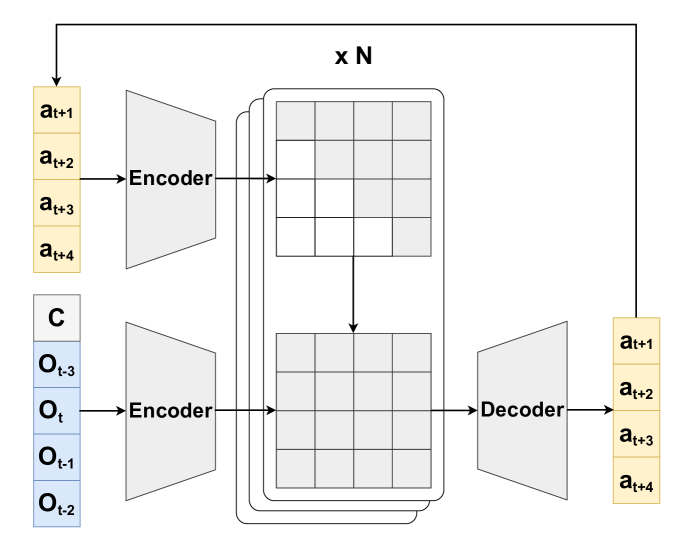
技术框架:该框架主要包含以下几个阶段:1) 数据收集:收集四足机器人在各种运动状态下的运动数据,无需进行标签标注。2) 扩散模型训练:使用收集到的数据训练一个扩散模型,该模型能够学习运动数据的分布。3) 无分类器引导:在推理阶段,使用无分类器引导的方式,根据目标条件(例如速度、方向)引导扩散模型生成相应的运动轨迹。4) 运动控制:将生成的运动轨迹转化为机器人的控制指令,驱动机器人运动。
关键创新:最重要的技术创新点在于将无分类器引导扩散模型应用于四足机器人的离线步态自适应。与传统的运动规划方法相比,该方法能够从无标签数据中学习复杂的运动模式,并根据目标条件生成相应的运动轨迹,无需手动设计复杂的运动控制器。
关键设计:该论文的关键设计包括:1) 使用扩散模型学习运动数据的分布;2) 使用无分类器引导的方式,根据目标条件引导扩散模型生成运动轨迹;3) 设计合适的损失函数,以保证生成的运动轨迹的质量和可行性。具体的参数设置和网络结构在论文中进行了详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
该论文首次将无分类器引导扩散模型应用于四足机器人运动控制,并成功地在ANYmal四足机器人平台上进行了硬件实验验证。实验结果表明,该方法能够有效地从无标签数据中学习运动模式,并根据目标条件生成相应的运动轨迹,实现了离线步态自适应。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于各种需要四足机器人进行复杂运动的场景,例如搜救、巡检、物流等。通过离线学习和自适应,机器人能够更好地适应不同的地形和任务需求,提高其在实际应用中的可靠性和效率。未来,该方法有望推广到其他类型的机器人,例如人形机器人和轮式机器人。
📄 摘要(原文)
We present a diffusion-based approach to quadrupedal locomotion that simultaneously addresses the limitations of learning and interpolating between multiple skills and of (modes) offline adapting to new locomotion behaviours after training. This is the first framework to apply classifier-free guided diffusion to quadruped locomotion and demonstrate its efficacy by extracting goal-conditioned behaviour from an originally unlabelled dataset. We show that these capabilities are compatible with a multi-skill policy and can be applied with little modification and minimal compute overhead, i.e., running entirely on the robots onboard CPU. We verify the validity of our approach with hardware experiments on the ANYmal quadruped platform.