Zero-shot Object-Centric Instruction Following: Integrating Foundation Models with Traditional Navigation
作者: Sonia Raychaudhuri, Duy Ta, Katrina Ashton, Angel X. Chang, Jiuguang Wang, Bernadette Bucher
分类: cs.RO, cs.CV
发布日期: 2024-11-12 (更新: 2025-05-07)
💡 一句话要点
提出LIFGIF,实现零样本的、以物体为中心的指令跟随导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 指令跟随 视觉语言导航 因子图优化 机器人导航
📋 核心要点
- 现有方法难以将自然语言指令与机器人构建的三维环境地图有效关联,阻碍了机器人理解和执行复杂导航任务。
- LIFGIF通过语言推断因子图,将自然语言指令中的物体信息融入到机器人构建的环境地图中,实现指令与地图的有效对齐。
- 在OC-VLN数据集上,LIFGIF超越了现有零样本基线,并在真实机器人上成功验证了其在物体中心指令跟随任务中的有效性。
📝 摘要(中文)
本文提出了一种名为Language-Inferred Factor Graph for Instruction Following (LIFGIF)的零样本方法,用于在三维地标图上定位自然语言指令。该地标图通过因子图联合估计机器人姿态生成,常用于无人机和扫地机器人等商业机器人。LIFGIF还包含一个策略,用于在地图构建的同时,在新的环境中遵循自然语言导航指令,从而在物理世界中实现鲁棒的导航性能。为了评估LIFGIF,我们提出了一个新的数据集Object-Centric VLN (OC-VLN),用于评估以物体为中心的自然语言导航指令的定位。我们与来自相关任务(Object Goal Navigation和Vision Language Navigation)的两个最先进的零样本基线进行比较,结果表明LIFGIF在OC-VLN上的所有评估指标上都优于它们。最后,我们成功地在Boston Dynamics Spot机器人上演示了LIFGIF在现实世界中执行零样本的、以物体为中心的指令跟随的有效性。
🔬 方法详解
问题定义:现有方法在处理自然语言导航指令时,难以有效地将指令中的物体信息与机器人构建的环境地图进行关联。这导致机器人难以理解和执行复杂的、以物体为中心的导航任务,尤其是在零样本场景下,缺乏训练数据支持。
核心思路:LIFGIF的核心思路是将自然语言指令中的物体信息融入到机器人构建的环境地图中,从而实现指令与地图的有效对齐。通过语言模型推断物体之间的关系,并将其整合到因子图中,从而实现对指令的理解和执行。
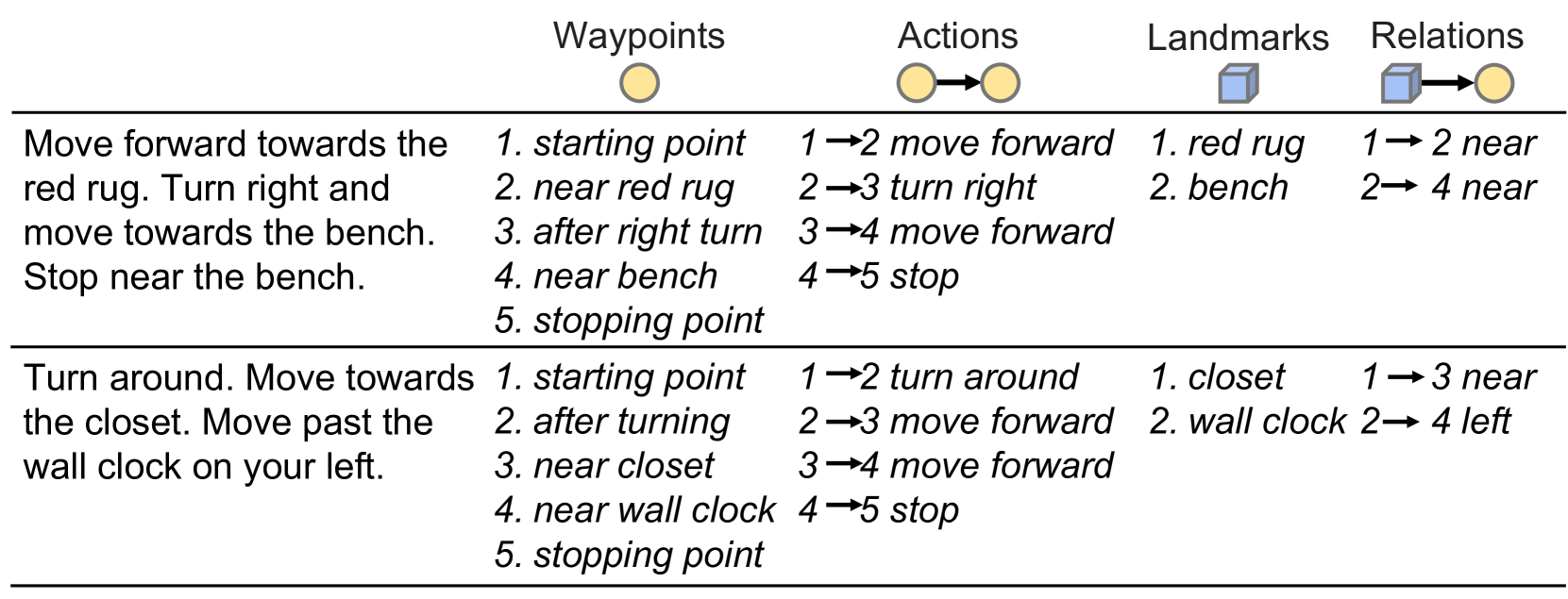
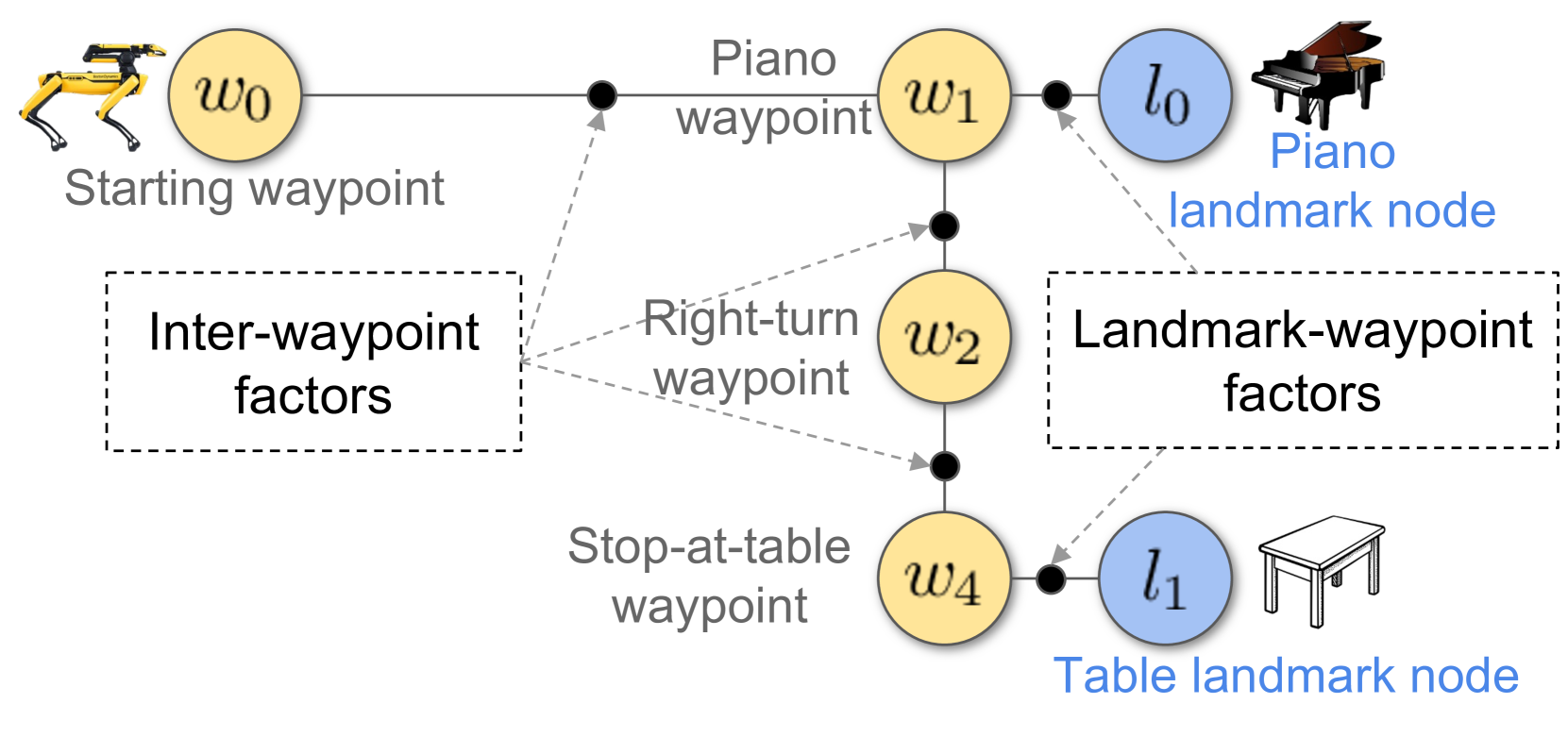
技术框架:LIFGIF的整体框架包括以下几个主要模块:1) 环境地图构建模块:使用因子图联合估计机器人姿态和地标位置,构建三维环境地图。2) 语言理解模块:利用预训练的语言模型解析自然语言指令,提取物体信息和导航目标。3) 指令定位模块:将提取的物体信息与环境地图中的地标进行匹配,并在因子图中添加相应的约束。4) 导航策略模块:根据更新后的因子图,规划机器人的导航路径,并控制机器人执行导航任务。
关键创新:LIFGIF的关键创新在于将语言信息融入到因子图中,从而实现了自然语言指令与环境地图的有效融合。这种方法允许机器人利用语言信息来指导导航,即使在没有训练数据的情况下也能实现良好的性能。
关键设计:LIFGIF的关键设计包括:1) 使用预训练的语言模型(如BERT或CLIP)提取物体信息。2) 设计合适的因子图结构,将语言信息作为约束添加到因子图中。3) 使用优化算法(如Levenberg-Marquardt算法)求解因子图,得到最优的机器人姿态和地标位置。4) 设计鲁棒的导航策略,以应对环境中的不确定性。
🖼️ 关键图片
📊 实验亮点
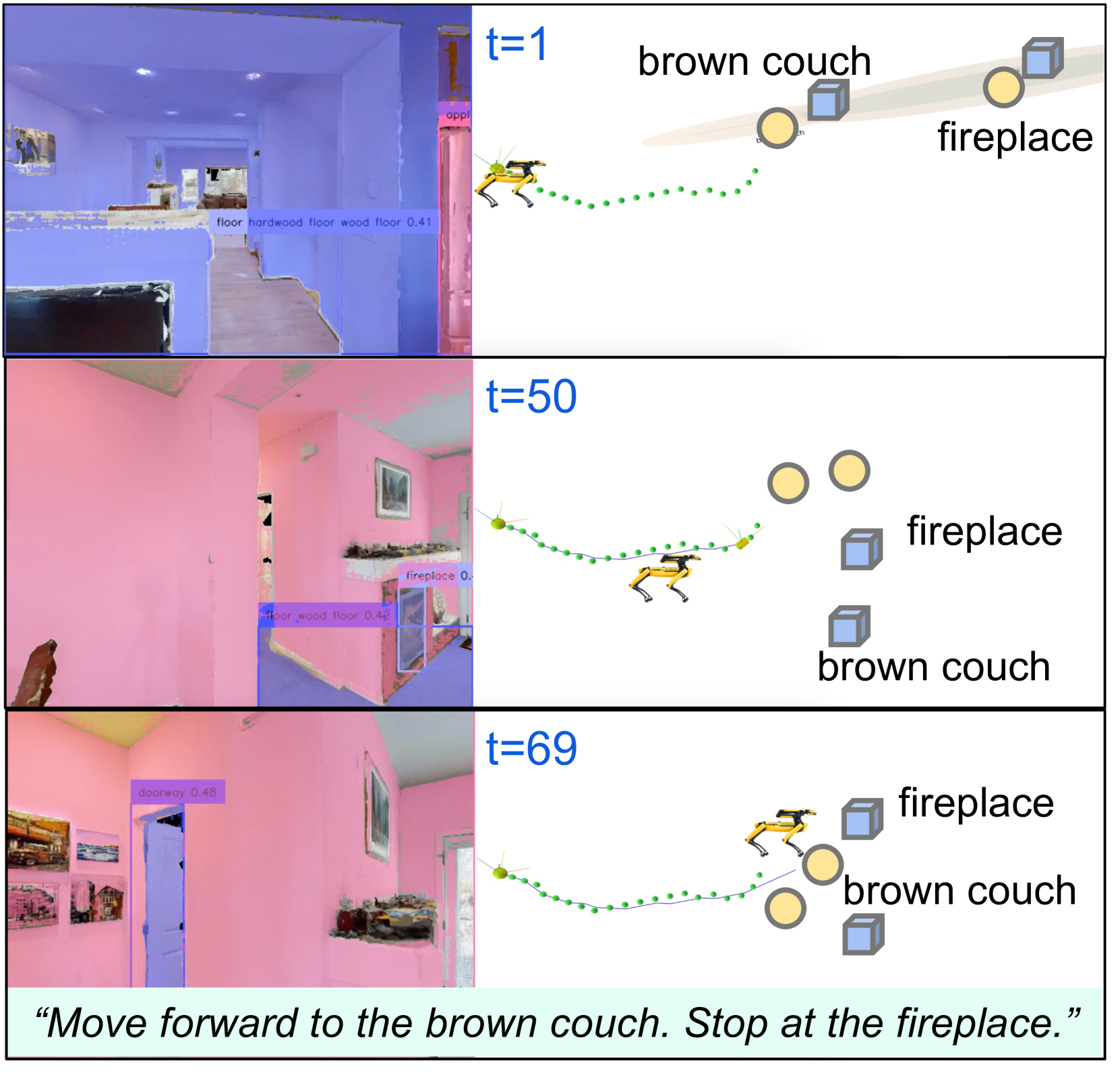
LIFGIF在OC-VLN数据集上显著优于现有的零样本基线方法,在所有评估指标上均取得了最佳性能。此外,该方法还在真实的Boston Dynamics Spot机器人上进行了验证,成功实现了零样本的、以物体为中心的指令跟随导航。实验结果表明,LIFGIF具有良好的泛化能力和鲁棒性,能够在真实环境中有效工作。
🎯 应用场景
该研究成果可应用于家庭服务机器人、仓储物流机器人、安防巡检机器人等领域。通过理解自然语言指令,机器人可以更智能地执行导航任务,例如“去厨房拿苹果”、“去卧室关灯”等。该技术有望提升机器人的自主性和人机交互能力,使其更好地服务于人类生活。
📄 摘要(原文)
Large scale scenes such as multifloor homes can be robustly and efficiently mapped with a 3D graph of landmarks estimated jointly with robot poses in a factor graph, a technique commonly used in commercial robots such as drones and robot vacuums. In this work, we propose Language-Inferred Factor Graph for Instruction Following (LIFGIF), a zero-shot method to ground natural language instructions in such a map. LIFGIF also includes a policy for following natural language navigation instructions in a novel environment while the map is constructed, enabling robust navigation performance in the physical world. To evaluate LIFGIF, we present a new dataset, Object-Centric VLN (OC-VLN), in order to evaluate grounding of object-centric natural language navigation instructions. We compare to two state-of-the-art zero-shot baselines from related tasks, Object Goal Navigation and Vision Language Navigation, to demonstrate that LIFGIF outperforms them across all our evaluation metrics on OCVLN. Finally, we successfully demonstrate the effectiveness of LIFGIF for performing zero-shot object-centric instruction following in the real world on a Boston Dynamics Spot robot.