AV-PedAware: Self-Supervised Audio-Visual Fusion for Dynamic Pedestrian Awareness
作者: Yizhuo Yang, Shenghai Yuan, Muqing Cao, Jianfei Yang, Lihua Xie
分类: cs.RO
发布日期: 2024-11-11 (更新: 2025-04-04)
备注: This work has been accepted for publication at the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Personal use is permitted. For other uses, permission from IEEE is required
DOI: 10.1109/IROS55552.2023.10342257
💡 一句话要点
AV-PedAware:提出一种自监督音视频融合的动态行人感知系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频融合 行人感知 自监督学习 机器人 3D检测 注意力机制 多模态学习
📋 核心要点
- 传统行人感知方法依赖昂贵的激光雷达和摄像头,易受环境因素影响,成本高且鲁棒性差。
- AV-PedAware利用低成本的音视频融合,模拟人类感知,通过自监督学习预测行人运动,降低成本并提高鲁棒性。
- 实验表明,AV-PedAware在极端视觉条件下也能提供可靠的3D行人检测结果,性能与激光雷达系统相当。
📝 摘要(中文)
本研究提出AV-PedAware,一个自监督音视频融合系统,旨在提升机器人应用中的动态行人感知能力。行人感知是许多机器人应用的关键需求。然而,依赖摄像头和激光雷达覆盖多视角的传统方法成本高昂,且易受光照变化、遮挡和天气条件等问题的影响。我们提出的解决方案通过低成本的音视频融合来复现人类对3D行人的感知。本研究首次尝试利用音视频融合来监测脚步声,从而预测附近行人的移动。该系统通过基于激光雷达生成标签的自监督学习进行训练,使其成为基于激光雷达的行人感知的经济高效的替代方案。AV-PedAware以较低的成本实现了与基于激光雷达的系统相当的结果。通过利用注意力机制,它可以处理动态光照和遮挡,克服了传统激光雷达和基于摄像头的系统的局限性。为了评估我们方法的有效性,我们收集了一个新的多模态行人检测数据集,并进行了实验,证明了该系统仅使用音频和视觉数据即可提供可靠的3D检测结果,即使在极端的视觉条件下也是如此。我们将在线提供我们收集的数据集和源代码,以鼓励该领域机器人感知系统的进一步发展。
🔬 方法详解
问题定义:论文旨在解决机器人应用中动态行人感知的问题。现有方法,如基于激光雷达和摄像头的系统,存在成本高昂、易受光照、遮挡和天气条件影响等痛点,限制了其在实际场景中的应用。
核心思路:论文的核心思路是利用低成本的音视频传感器,通过模仿人类的感知方式,实现对行人的3D感知和运动预测。通过融合音频(脚步声)和视觉信息,可以提高系统在复杂环境下的鲁棒性和准确性。
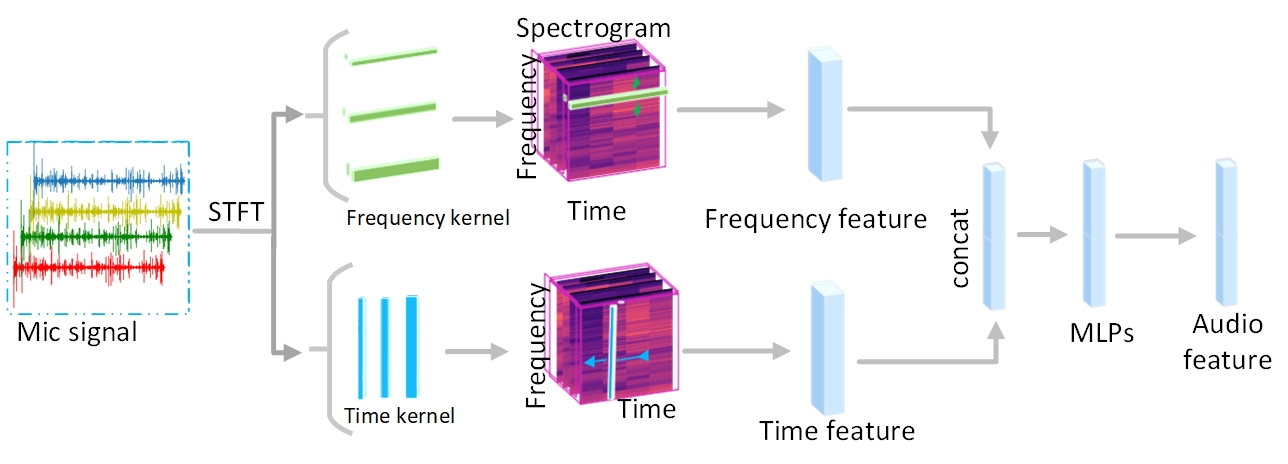
技术框架:AV-PedAware系统的整体框架包含以下几个主要模块:1) 音频特征提取模块,用于提取脚步声的特征;2) 视觉特征提取模块,用于提取图像中的视觉特征;3) 音视频融合模块,利用注意力机制将音频和视觉特征进行融合;4) 3D行人检测模块,基于融合后的特征进行3D行人检测和运动预测。系统采用自监督学习的方式进行训练,利用激光雷达生成的标签作为监督信号。
关键创新:该论文最重要的技术创新点在于首次将音视频融合应用于动态行人感知,并提出了一种基于自监督学习的训练方法。与传统的基于激光雷达或摄像头的系统相比,AV-PedAware具有成本更低、鲁棒性更强的优点。注意力机制的引入使得系统能够更好地处理动态光照和遮挡等问题。
关键设计:论文中使用了注意力机制来融合音频和视觉特征,具体来说,注意力机制用于学习音频和视觉特征之间的相关性,从而更好地利用这两种模态的信息。损失函数的设计也至关重要,论文中使用了基于激光雷达标签的自监督损失函数,用于训练音视频融合模型。具体的网络结构和参数设置在论文中有详细描述,但未在摘要中体现。
🖼️ 关键图片


📊 实验亮点
该研究收集了一个新的多模态行人检测数据集,并进行了实验验证。实验结果表明,AV-PedAware仅使用音频和视觉数据即可提供可靠的3D检测结果,即使在极端的视觉条件下也能达到与激光雷达系统相当的性能。这表明该系统具有很强的鲁棒性和实用性,为低成本行人感知提供了一种新的解决方案。
🎯 应用场景
AV-PedAware具有广泛的应用前景,可用于自动驾驶、机器人导航、智能监控等领域。该系统能够以较低的成本提供可靠的行人感知能力,有助于提高机器人在复杂环境中的安全性和自主性。未来,该技术有望应用于智能家居、智慧城市等领域,为人们的生活带来便利。
📄 摘要(原文)
In this study, we introduce AV-PedAware, a self-supervised audio-visual fusion system designed to improve dynamic pedestrian awareness for robotics applications. Pedestrian awareness is a critical requirement in many robotics applications. However, traditional approaches that rely on cameras and LIDARs to cover multiple views can be expensive and susceptible to issues such as changes in illumination, occlusion, and weather conditions. Our proposed solution replicates human perception for 3D pedestrian detection using low-cost audio and visual fusion. This study represents the first attempt to employ audio-visual fusion to monitor footstep sounds for the purpose of predicting the movements of pedestrians in the vicinity. The system is trained through self-supervised learning based on LIDAR-generated labels, making it a cost-effective alternative to LIDAR-based pedestrian awareness. AV-PedAware achieves comparable results to LIDAR-based systems at a fraction of the cost. By utilizing an attention mechanism, it can handle dynamic lighting and occlusions, overcoming the limitations of traditional LIDAR and camera-based systems. To evaluate our approach's effectiveness, we collected a new multimodal pedestrian detection dataset and conducted experiments that demonstrate the system's ability to provide reliable 3D detection results using only audio and visual data, even in extreme visual conditions. We will make our collected dataset and source code available online for the community to encourage further development in the field of robotics perception systems.