DynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
作者: Peiqi Liu, Zhanqiu Guo, Mohit Warke, Soumith Chintala, Chris Paxton, Nur Muhammad Mahi Shafiullah, Lerrel Pinto
分类: cs.RO, cs.LG
发布日期: 2024-11-07 (更新: 2025-05-29)
备注: Website: https://dynamem.github.io
💡 一句话要点
DynaMem:用于开放世界移动操作的在线动态时空语义记忆
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 开放世界 动态环境 时空语义记忆 视觉语言模型 机器人 点云地图 对象定位
📋 核心要点
- 现有开放词汇移动操作系统假设环境是静态的,这限制了它们在真实世界中的应用,因为真实环境会因人为干预或机器人自身行为而频繁变化。
- DynaMem通过构建动态时空语义记忆来解决这个问题,该记忆使用3D数据结构维护点云的动态信息,并能响应开放词汇对象定位查询。
- 实验表明,DynaMem在非静态对象上的抓取成功率达到70%,相比现有静态系统有显著提升,验证了其在动态环境中的有效性。
📝 摘要(中文)
本文提出DynaMem,一种用于开放世界移动操作的新方法,它使用动态时空语义记忆来表示机器人的环境。DynaMem构建了一个3D数据结构来维护点云的动态记忆,并使用多模态LLM或由最先进的视觉-语言模型生成的开放词汇特征来回答开放词汇对象定位查询。在DynaMem的支持下,我们的机器人可以探索新的环境,搜索内存中未找到的对象,并随着对象在场景中移动、出现或消失而不断更新内存。我们在三个真实场景和九个离线场景中的Stretch SE3机器人上进行了大量实验,在非静态对象上的平均抓取成功率为70%,比最先进的静态系统提高了2倍以上。我们的代码以及实验和部署视频已开源,可在我们的项目网站上找到。
🔬 方法详解
问题定义:现有开放词汇移动操作系统主要针对静态环境设计,无法有效处理真实世界中物体移动、出现或消失等动态变化。这限制了机器人在复杂、非结构化环境中的应用能力。现有方法难以持续更新环境信息,导致定位和操作失败。
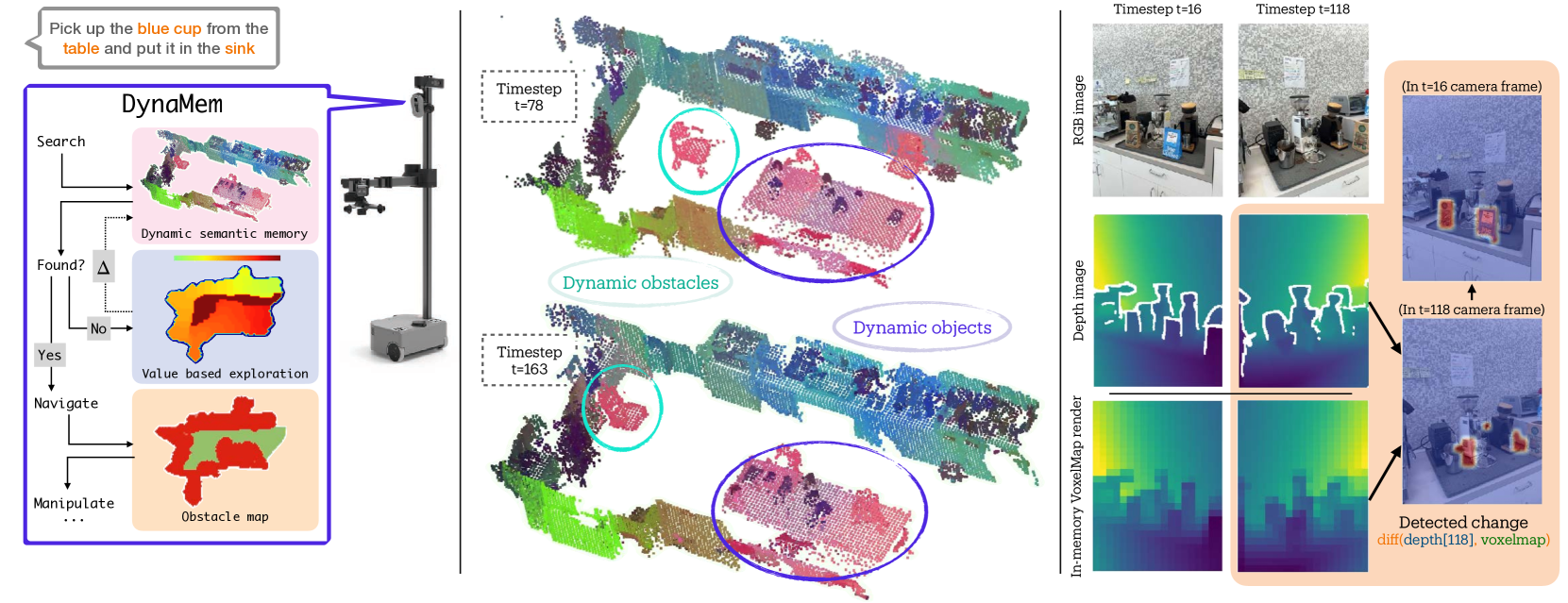
核心思路:DynaMem的核心思路是构建一个动态的时空语义记忆,用于实时记录和更新环境信息。通过维护一个3D点云数据结构,系统可以跟踪物体的位置和语义信息,并根据环境变化进行动态调整。这种动态记忆使得机器人能够适应环境变化,提高在开放世界中的操作能力。
技术框架:DynaMem的整体框架包含以下几个主要模块:1) 环境感知模块:利用传感器(如RGB-D相机)获取环境的点云数据。2) 语义理解模块:使用多模态LLM或视觉-语言模型提取场景中物体的语义信息。3) 动态记忆模块:构建并维护一个3D数据结构,用于存储点云和语义信息,并根据环境变化进行更新。4) 对象定位模块:根据用户输入的自然语言指令,在动态记忆中定位目标对象。5) 运动规划与控制模块:规划机器人的运动轨迹,并控制机器人执行抓取等操作。
关键创新:DynaMem的关键创新在于其动态时空语义记忆的构建和维护机制。与传统的静态地图相比,DynaMem能够实时更新环境信息,从而适应动态变化。此外,DynaMem还利用多模态LLM或视觉-语言模型进行开放词汇对象定位,使得机器人能够理解复杂的自然语言指令。
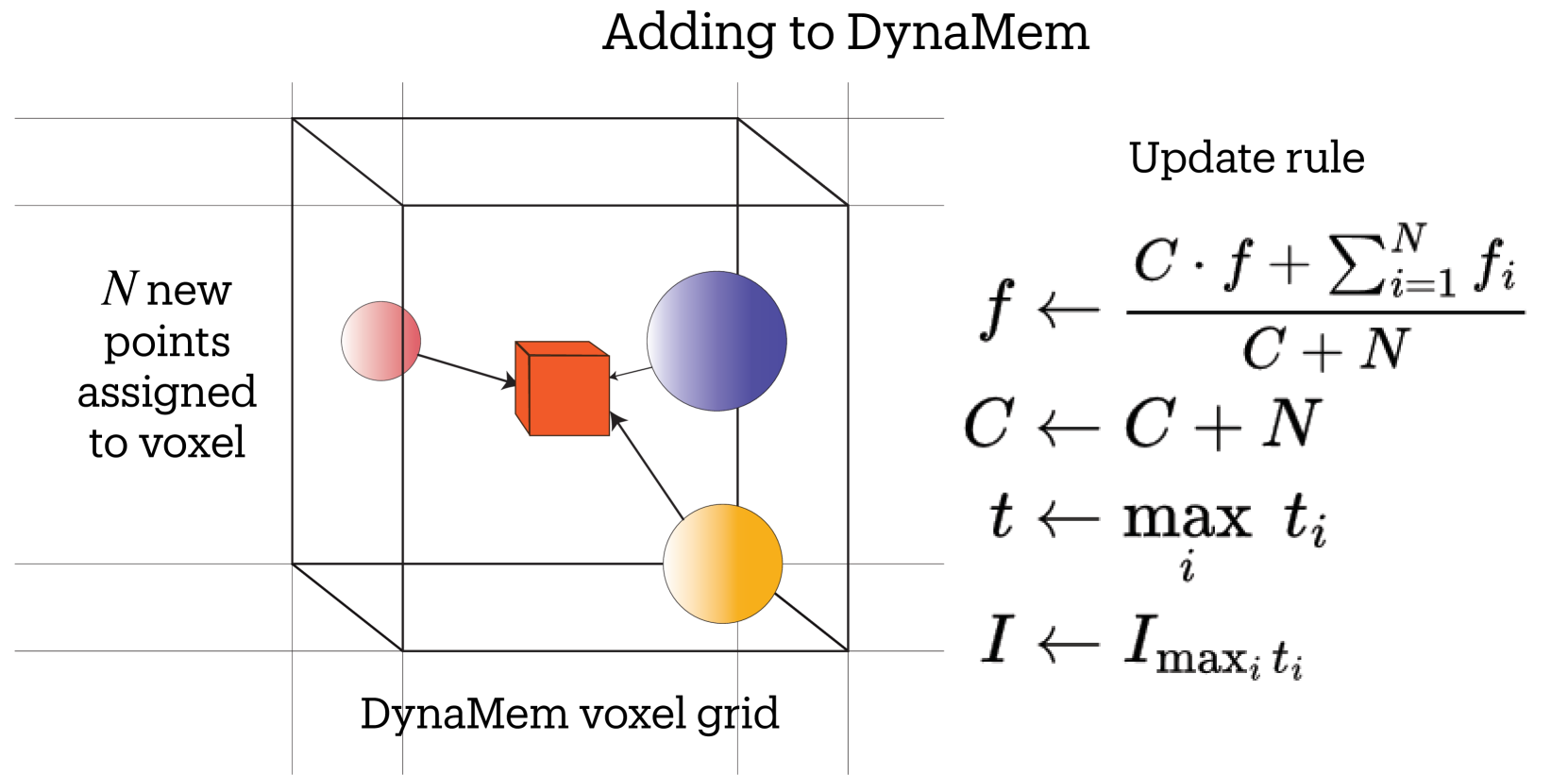
关键设计:DynaMem使用增量式点云地图构建方法,避免一次性处理所有数据,提高效率。动态记忆的更新策略包括:1) 基于时间戳的更新:定期更新点云和语义信息。2) 基于事件的更新:当检测到物体移动、出现或消失时,触发更新。损失函数的设计旨在优化点云的重建质量和语义信息的准确性。具体参数设置(如点云分辨率、更新频率等)需要根据具体应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DynaMem在非静态对象上的平均抓取成功率达到70%,相比于最先进的静态系统,性能提升超过2倍。此外,DynaMem在三个真实场景和九个离线场景中进行了广泛测试,验证了其在不同环境下的泛化能力。开源的代码和实验视频也为其他研究者提供了宝贵的资源。
🎯 应用场景
DynaMem技术可广泛应用于家庭服务机器人、仓储物流机器人、以及灾难救援机器人等领域。它使机器人能够在动态、非结构化的环境中执行复杂的任务,例如在家庭中整理物品、在仓库中拣选货物、或在灾难现场搜寻幸存者。该研究的实际价值在于提高了机器人在真实世界中的适应性和可靠性,为实现真正意义上的智能机器人奠定了基础。
📄 摘要(原文)
Significant progress has been made in open-vocabulary mobile manipulation, where the goal is for a robot to perform tasks in any environment given a natural language description. However, most current systems assume a static environment, which limits the system's applicability in real-world scenarios where environments frequently change due to human intervention or the robot's own actions. In this work, we present DynaMem, a new approach to open-world mobile manipulation that uses a dynamic spatio-semantic memory to represent a robot's environment. DynaMem constructs a 3D data structure to maintain a dynamic memory of point clouds, and answers open-vocabulary object localization queries using multimodal LLMs or open-vocabulary features generated by state-of-the-art vision-language models. Powered by DynaMem, our robots can explore novel environments, search for objects not found in memory, and continuously update the memory as objects move, appear, or disappear in the scene. We run extensive experiments on the Stretch SE3 robots in three real and nine offline scenes, and achieve an average pick-and-drop success rate of 70% on non-stationary objects, which is more than a 2x improvement over state-of-the-art static systems. Our code as well as our experiment and deployment videos are open sourced and can be found on our project website: https://dynamem.github.io/