Repairing Neural Networks for Safety in Robotic Systems using Predictive Models
作者: Keyvan Majd, Geoffrey Clark, Georgios Fainekos, Heni Ben Amor
分类: cs.RO
发布日期: 2024-11-07
备注: Accepted at the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024)
💡 一句话要点
提出基于预测模型的神经网络修复方法,提升机器人系统的安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 安全约束 神经网络修复 行为克隆 预测模型
📋 核心要点
- 现有机器人学习方法在安全性方面存在不足,难以保证机器人行为符合预定义的约束。
- 该方法通过结合行为克隆和神经网络修复,利用预测模型来强制执行安全约束,确保策略的安全性。
- 实验表明,该方法在移动机器人导航和下肢假肢控制中成功应用,并显著减少了学习过程中的交互时间。
📝 摘要(中文)
本文提出了一种新的安全感知机器人学习方法,重点在于使用预测模型修复策略。该方法结合了行为克隆和神经网络修复,采用两步监督学习框架。首先,从专家演示中学习策略,然后应用基于预测模型的修复来强制执行安全约束。预测模型可以涵盖与机器人学习应用相关的各个方面,例如本体感受状态和碰撞可能性。实验结果表明,所学习的策略成功地遵守了移动机器人导航和真实下肢假肢这两个应用中预定义的安全约束。此外,该方法有效地减少了与机器人的重复交互,从而在学习过程中节省了大量时间。
🔬 方法详解
问题定义:现有机器人学习方法,尤其是基于强化学习的方法,在实际部署中面临安全性挑战。直接从数据中学习的策略可能违反安全约束,导致机器人发生碰撞或其他危险行为。现有的安全强化学习方法通常需要大量的环境交互,学习成本高昂。
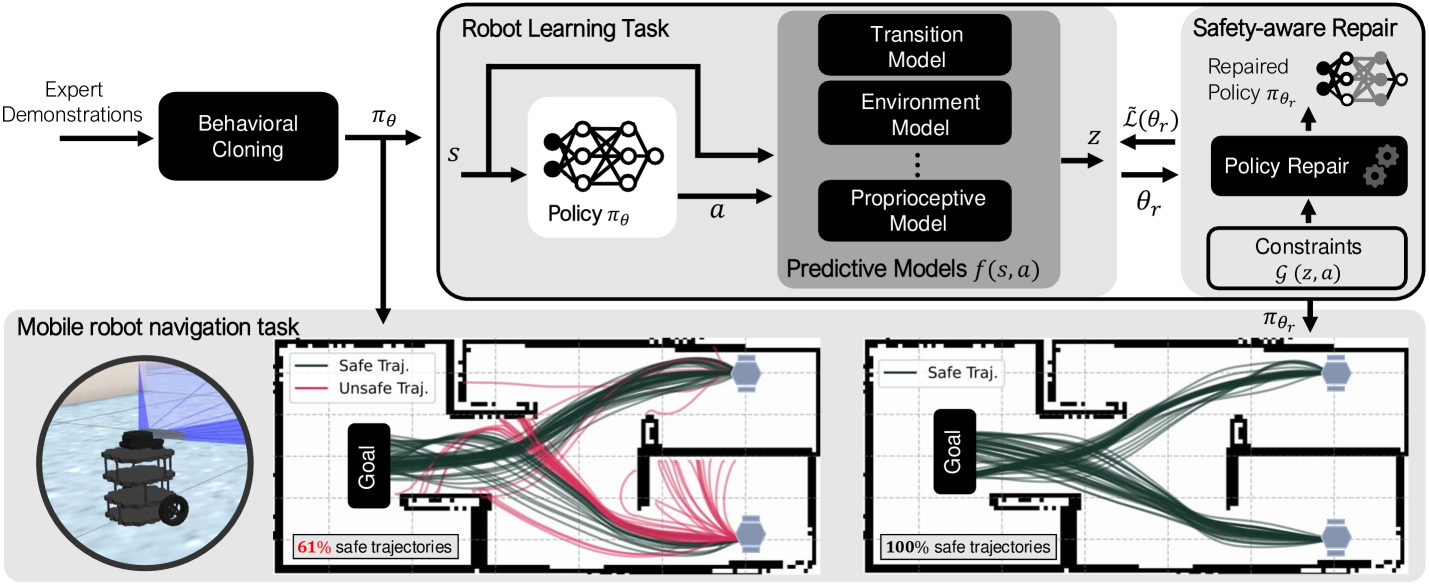
核心思路:本文的核心思路是利用预测模型来评估策略的安全性,并对不安全的策略进行修复。通过结合行为克隆(从专家演示中学习)和神经网络修复技术,可以在保证策略性能的同时,强制执行安全约束。这种方法避免了直接在真实环境中进行大量探索,降低了学习成本和风险。
技术框架:该方法包含两个主要阶段:1) 行为克隆阶段:使用专家演示数据训练一个初始策略网络。这个策略网络的目标是模仿专家的行为,提供一个良好的起点。2) 神经网络修复阶段:使用预测模型评估初始策略的安全性。如果策略违反了安全约束,则使用神经网络修复技术修改策略网络,使其满足安全约束。这个过程可以迭代进行,直到策略满足所有安全约束。
关键创新:该方法的关键创新在于将神经网络修复技术应用于机器人学习的安全问题。通过使用预测模型来指导策略的修复,可以在不牺牲策略性能的前提下,有效地提高策略的安全性。此外,该方法结合了行为克隆和神经网络修复,避免了直接在真实环境中进行大量探索,降低了学习成本和风险。
关键设计:预测模型可以是任何能够预测机器人状态或环境状态的模型,例如,预测碰撞概率的模型。神经网络修复阶段使用优化算法来修改策略网络的权重,目标是最小化策略与原始策略的差异,同时满足安全约束。安全约束可以表示为关于机器人状态或环境状态的函数,例如,避免碰撞的约束。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在移动机器人导航和下肢假肢控制两个应用中均取得了良好的效果。在移动机器人导航任务中,该方法能够使机器人成功避开障碍物,并安全到达目标位置。在下肢假肢控制任务中,该方法能够使假肢运动更加自然流畅,并避免了不安全的运动模式。此外,该方法还能够显著减少与机器人的重复交互,从而在学习过程中节省大量时间。具体数据未知。
🎯 应用场景
该研究成果可广泛应用于各种需要安全保障的机器人系统,例如自动驾驶、医疗机器人、工业机器人等。通过该方法,可以有效地提高机器人的安全性,降低事故发生的风险,从而促进机器人技术在实际场景中的应用。此外,该方法还可以应用于其他需要满足约束条件的机器学习问题。
📄 摘要(原文)
This paper introduces a new method for safety-aware robot learning, focusing on repairing policies using predictive models. Our method combines behavioral cloning with neural network repair in a two-step supervised learning framework. It first learns a policy from expert demonstrations and then applies repair subject to predictive models to enforce safety constraints. The predictive models can encompass various aspects relevant to robot learning applications, such as proprioceptive states and collision likelihood. Our experimental results demonstrate that the learned policy successfully adheres to a predefined set of safety constraints on two applications: mobile robot navigation, and real-world lower-leg prostheses. Additionally, we have shown that our method effectively reduces repeated interaction with the robot, leading to substantial time savings during the learning process.