LEGATO: Cross-Embodiment Imitation Using a Grasping Tool
作者: Mingyo Seo, H. Andy Park, Shenli Yuan, Yuke Zhu, Luis Sentis
分类: cs.RO
发布日期: 2024-11-06 (更新: 2025-02-19)
备注: Published in RA-L
期刊: IEEE Robotics and Automation Letters vol. 10 no. 3 pp. 2854-2861 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
LEGATO:利用抓取工具实现跨具身模仿学习,提升机器人技能迁移能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 跨具身模仿学习 机器人技能迁移 视觉运动控制 手持夹爪 逆运动学
📋 核心要点
- 现有模仿学习方法难以在不同形态机器人间迁移技能,限制了大规模模仿学习的成本效益和可重用性。
- LEGATO框架通过引入手持夹爪统一动作和观察空间,并结合运动不变空间变换,实现跨具身技能迁移。
- 实验结果表明,LEGATO框架能够有效地学习和迁移视觉运动技能到各种机器人上,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为LEGATO的跨具身模仿学习框架,用于在不同运动学形态的机器人之间迁移视觉运动技能。该框架引入了一个手持式夹爪,统一了动作和观察空间,从而可以在不同机器人上一致地定义任务。通过模仿学习,我们使用该夹爪在任务演示上训练视觉运动策略,并应用变换到运动不变空间以计算训练损失。策略生成的夹爪运动通过逆运动学重定向为高自由度的全身运动,以便在各种机器人上部署。在仿真和真实机器人实验中的评估突出了该框架在学习和迁移各种机器人视觉运动技能方面的有效性。
🔬 方法详解
问题定义:现有的模仿学习方法通常针对特定机器人设计,难以直接迁移到具有不同运动学结构的机器人上。这限制了模仿学习的泛化能力和可重用性,使得为每种机器人单独训练策略的成本很高。因此,需要一种方法能够在不同机器人之间有效地迁移学习到的技能。
核心思路:LEGATO的核心思路是引入一个通用的手持夹爪作为中间媒介,统一不同机器人的动作和观察空间。通过在夹爪的运动空间中进行模仿学习,可以将学习到的技能迁移到具有不同运动学结构的机器人上。此外,利用运动不变空间变换,进一步增强了策略的泛化能力。
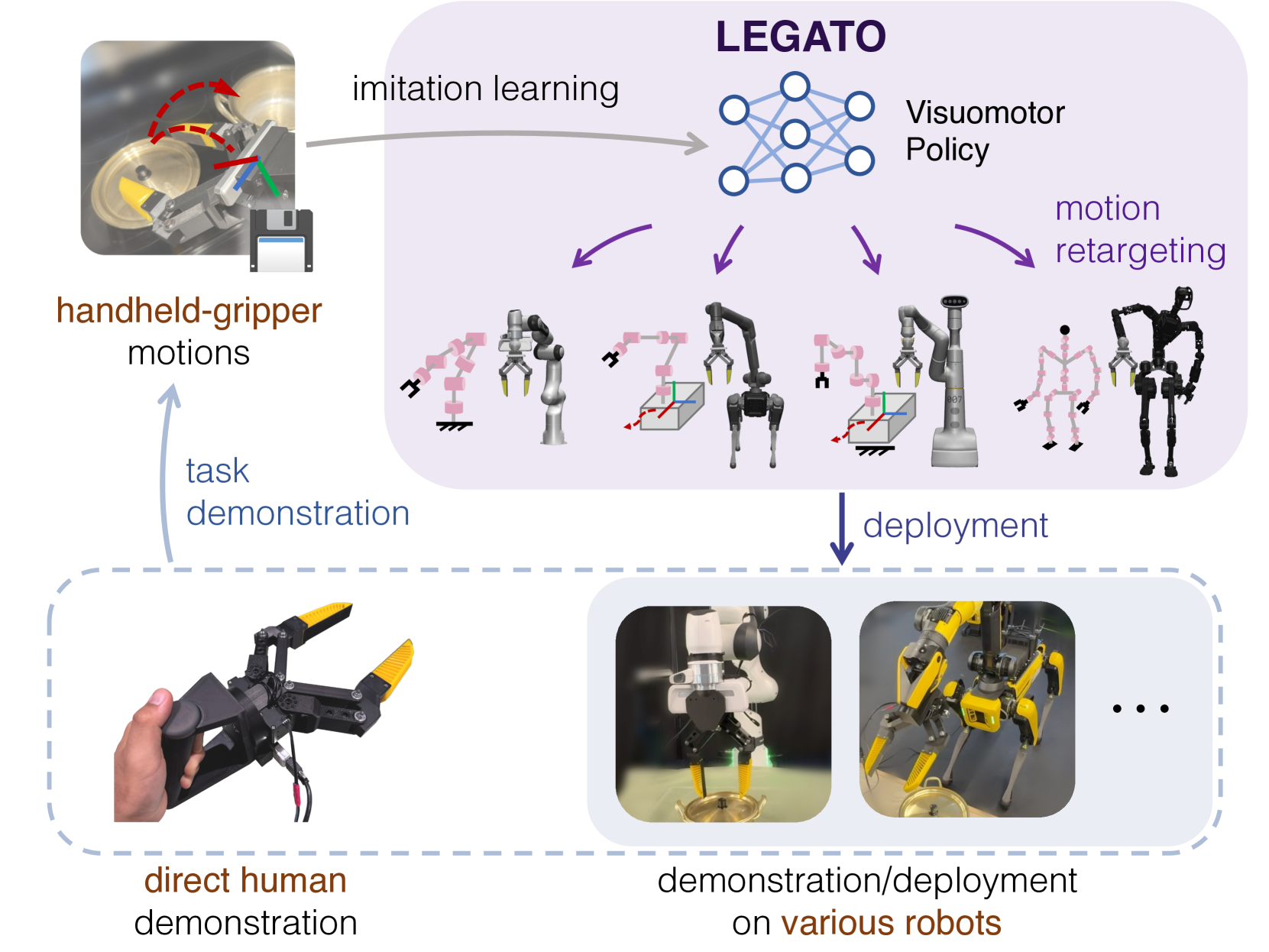
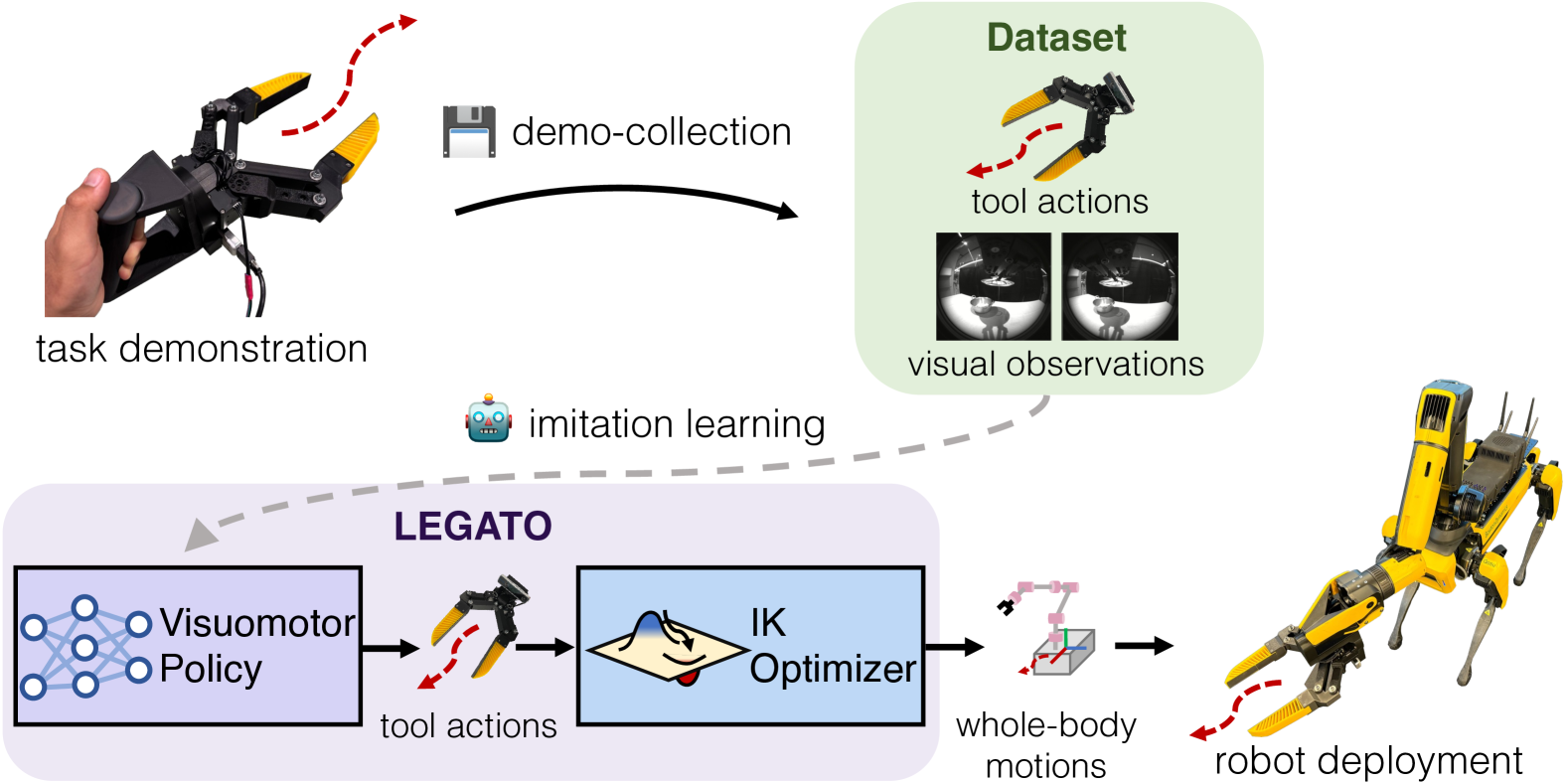
技术框架:LEGATO框架主要包含以下几个阶段:1) 使用手持夹爪进行任务演示,记录夹爪的运动轨迹和视觉信息。2) 在夹爪的运动空间中,使用模仿学习训练视觉运动策略。3) 将策略生成的夹爪运动通过逆运动学重定向为目标机器人的全身运动。4) 在真实机器人或仿真环境中部署学习到的策略。
关键创新:LEGATO的关键创新在于使用手持夹爪统一了不同机器人的动作和观察空间,从而实现了跨具身模仿学习。与传统的直接在机器人关节空间进行模仿学习的方法相比,LEGATO能够更好地泛化到具有不同运动学结构的机器人上。此外,运动不变空间变换进一步提高了策略的鲁棒性。
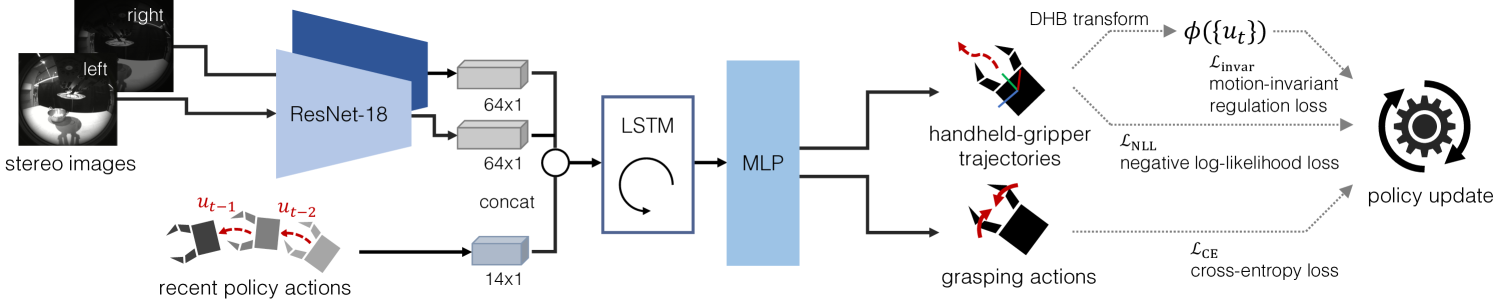
关键设计:LEGATO框架的关键设计包括:1) 手持夹爪的设计,需要能够执行各种抓取任务,并提供丰富的视觉信息。2) 运动不变空间变换的设计,需要能够消除不同机器人运动学结构的差异。3) 逆运动学重定向算法的设计,需要能够将夹爪运动转化为目标机器人的全身运动。损失函数的设计也至关重要,需要考虑夹爪运动的平滑性和准确性。具体的网络结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
该论文在仿真和真实机器人实验中验证了LEGATO框架的有效性。实验结果表明,LEGATO能够成功地将学习到的视觉运动技能迁移到具有不同运动学结构的机器人上。具体的性能数据和对比基线在摘要中未提及,属于未知信息。但整体而言,该框架在跨具身模仿学习方面取得了显著进展。
🎯 应用场景
LEGATO框架可应用于各种需要跨机器人技能迁移的场景,例如:自动化装配、物流分拣、家庭服务等。通过降低为不同机器人定制策略的成本,可以加速机器人技术的普及和应用。该研究为实现通用机器人和大规模模仿学习奠定了基础。
📄 摘要(原文)
Cross-embodiment imitation learning enables policies trained on specific embodiments to transfer across different robots, unlocking the potential for large-scale imitation learning that is both cost-effective and highly reusable. This paper presents LEGATO, a cross-embodiment imitation learning framework for visuomotor skill transfer across varied kinematic morphologies. We introduce a handheld gripper that unifies action and observation spaces, allowing tasks to be defined consistently across robots. We train visuomotor policies on task demonstrations using this gripper through imitation learning, applying transformation to a motion-invariant space for computing the training loss. Gripper motions generated by the policies are retargeted into high-degree-of-freedom whole-body motions using inverse kinematics for deployment across diverse embodiments. Our evaluations in simulation and real-robot experiments highlight the framework's effectiveness in learning and transferring visuomotor skills across various robots. More information can be found on the project page: https://ut-hcrl.github.io/LEGATO.