VLA-3D: A Dataset for 3D Semantic Scene Understanding and Navigation
作者: Haochen Zhang, Nader Zantout, Pujith Kachana, Zongyuan Wu, Ji Zhang, Wenshan Wang
分类: cs.RO
发布日期: 2024-11-05
备注: Accepted and presented at the 1st Workshop on Semantic Reasoning and Goal Understanding in Robotics (SemRob), Robotics Science and Systems Conference (RSS 2024)
🔗 代码/项目: GITHUB
💡 一句话要点
VLA-3D:用于3D语义场景理解和导航的大规模数据集
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 机器人导航 视觉语言模型 语义关系 数据集 自然语言指令 具身智能
📋 核心要点
- 现有室内导航方法在复杂场景中,尤其是在需要细粒度语义理解和空间推理时,面临鲁棒性挑战。
- VLA-3D数据集通过提供大规模的真实世界3D场景、语义关系和指称语句,旨在提升模型的语义理解和导航能力。
- 该数据集包含丰富的3D点云、语义标注、场景图和自然语言描述,并提供了基准模型性能作为参考。
📝 摘要(中文)
随着大型语言模型(LLMs)、视觉-语言模型(VLMs)和其他通用基础模型的兴起,多模态、多任务具身智能体在仅以自然语言作为输入的情况下在不同环境中运行的潜力越来越大。其中一个应用领域是使用自然语言指令进行室内导航。然而,由于所需的空间推理和语义理解,尤其是在可能包含属于细粒度类别的许多对象的任意场景中,这个问题仍然具有挑战性。为了应对这一挑战,我们整理了最大的真实世界数据集,用于3D场景中的视觉和语言引导动作(VLA-3D),该数据集包含来自现有数据集的超过11.5K个扫描的3D室内房间、23.5M个启发式生成的对象之间的语义关系以及9.7M个合成生成的指称语句。我们的数据集包含经过处理的3D点云、语义对象和房间注释、场景图、可导航的自由空间注释以及专门关注于视角无关的空间关系以消除对象歧义的指称语言语句。这些功能的目的是帮助下游导航任务,尤其是在真实世界的系统中,在不断变化的场景和不完善的语言的开放世界中必须保证一定程度的鲁棒性。我们使用当前最先进的模型对我们的数据集进行基准测试以获得性能基线。生成和可视化数据集的所有代码已公开发布,请参阅https://github.com/HaochenZ11/VLA-3D。随着此数据集的发布,我们希望为语义3D场景理解的进步提供资源,该资源对变化具有鲁棒性,并将有助于交互式室内导航系统的开发。
🔬 方法详解
问题定义:论文旨在解决在复杂室内环境中,现有导航系统对自然语言指令理解不足,空间推理能力弱,以及对细粒度语义信息利用不充分的问题。现有方法难以处理真实世界场景中变化多样的物体和关系,导致导航性能下降。
核心思路:论文的核心思路是构建一个大规模、高质量的3D语义场景数据集,该数据集不仅包含丰富的3D几何信息,还包含详细的语义标注、对象关系以及自然语言描述。通过提供这些信息,可以训练更强大的视觉-语言模型,从而提升导航系统对场景的理解和推理能力。
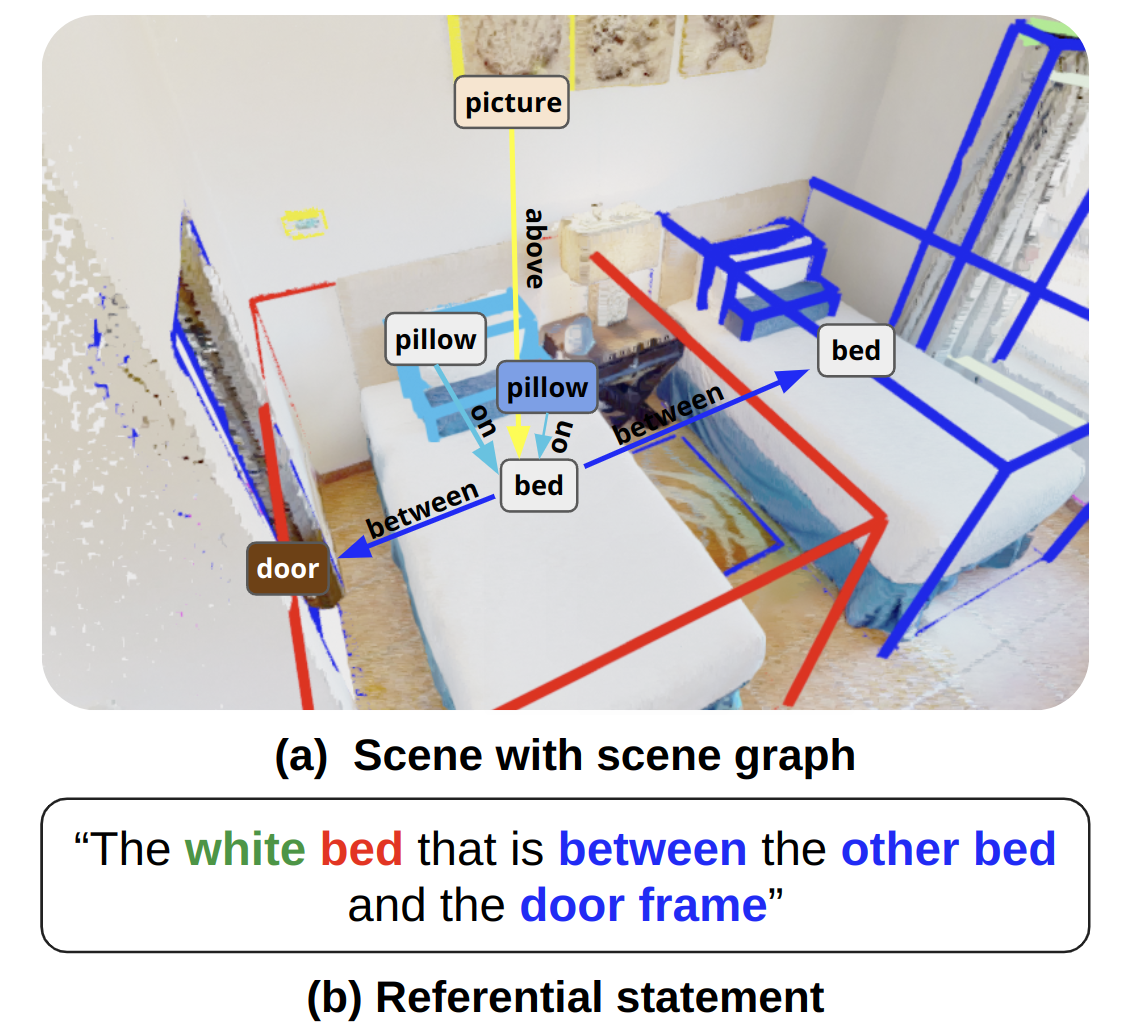
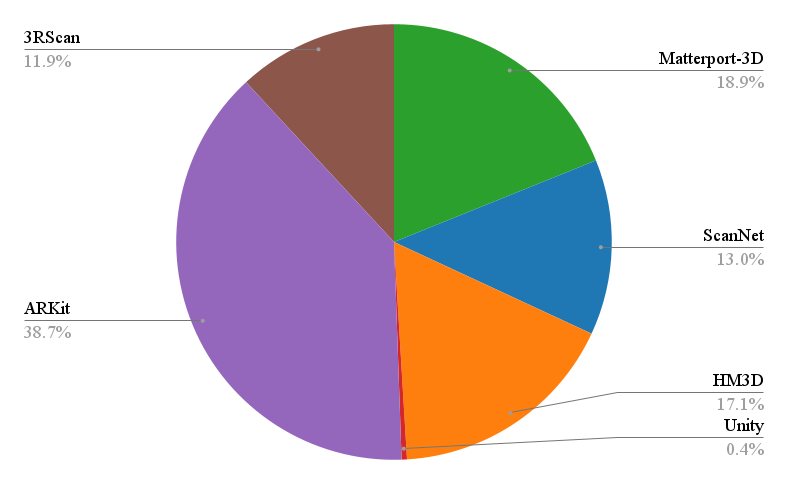
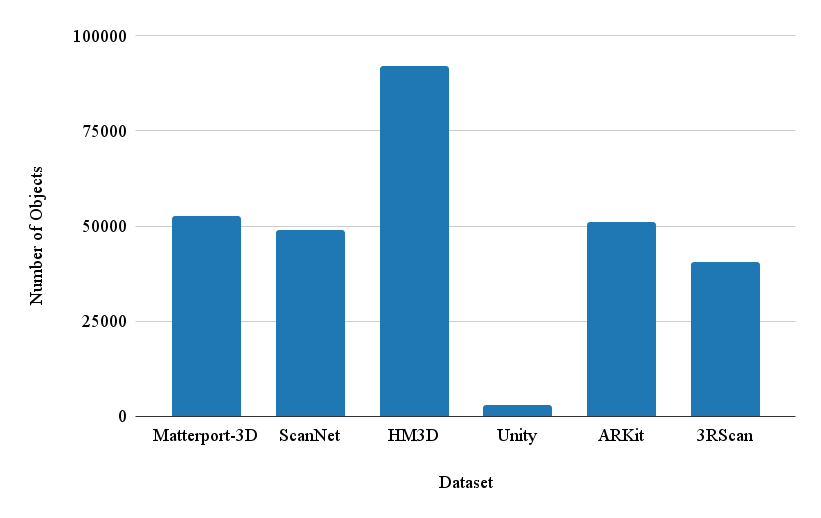
技术框架:VLA-3D数据集的构建流程主要包括以下几个阶段:1) 数据收集:从现有的3D室内场景数据集中收集超过11.5K个扫描的3D室内房间。2) 语义标注:对场景中的对象和房间进行语义标注。3) 关系生成:启发式地生成对象之间的语义关系,例如“在...旁边”、“在...上面”等,共计23.5M个。4) 语句生成:合成生成指称语句,用于描述场景中的对象和关系,共计9.7M个。5) 数据处理:对3D点云进行处理,生成可导航的自由空间标注。
关键创新:VLA-3D数据集的关键创新在于其规模和丰富性。它是目前最大的真实世界3D语义场景数据集之一,包含了大量的3D场景、语义标注、对象关系和自然语言描述。此外,该数据集还特别关注视角无关的空间关系,这有助于模型更好地理解场景中的对象和关系。与现有数据集相比,VLA-3D更侧重于真实场景的复杂性和多样性,更贴近实际应用需求。
关键设计:在数据生成方面,论文采用了启发式方法生成对象之间的语义关系,并使用合成方法生成指称语句。为了保证数据的质量,论文对生成的数据进行了筛选和过滤。此外,论文还提供了用于生成和可视化数据集的代码,方便研究人员使用和扩展。
🖼️ 关键图片
📊 实验亮点
论文构建了包含超过11.5K个3D室内房间、23.5M个语义关系和9.7M个指称语句的大规模VLA-3D数据集。通过在数据集上进行基准测试,论文为未来的研究提供了性能基线。公开的代码和数据集将促进3D语义场景理解和导航领域的发展。
🎯 应用场景
VLA-3D数据集可广泛应用于机器人导航、虚拟现实、增强现实、智能家居等领域。它能够帮助机器人更好地理解人类指令,在复杂环境中自主导航。同时,该数据集也为开发更智能、更自然的交互式应用提供了基础,例如,用户可以通过自然语言与虚拟环境进行交互。
📄 摘要(原文)
With the recent rise of Large Language Models (LLMs), Vision-Language Models (VLMs), and other general foundation models, there is growing potential for multimodal, multi-task embodied agents that can operate in diverse environments given only natural language as input. One such application area is indoor navigation using natural language instructions. However, despite recent progress, this problem remains challenging due to the spatial reasoning and semantic understanding required, particularly in arbitrary scenes that may contain many objects belonging to fine-grained classes. To address this challenge, we curate the largest real-world dataset for Vision and Language-guided Action in 3D Scenes (VLA-3D), consisting of over 11.5K scanned 3D indoor rooms from existing datasets, 23.5M heuristically generated semantic relations between objects, and 9.7M synthetically generated referential statements. Our dataset consists of processed 3D point clouds, semantic object and room annotations, scene graphs, navigable free space annotations, and referential language statements that specifically focus on view-independent spatial relations for disambiguating objects. The goal of these features is to aid the downstream task of navigation, especially on real-world systems where some level of robustness must be guaranteed in an open world of changing scenes and imperfect language. We benchmark our dataset with current state-of-the-art models to obtain a performance baseline. All code to generate and visualize the dataset is publicly released, see https://github.com/HaochenZ11/VLA-3D. With the release of this dataset, we hope to provide a resource for progress in semantic 3D scene understanding that is robust to changes and one which will aid the development of interactive indoor navigation systems.