Multi-Modal 3D Scene Graph Updater for Shared and Dynamic Environments
作者: Emilio Olivastri, Jonathan Francis, Alberto Pretto, Niko Sünderhauf, Krishan Rana
分类: cs.RO
发布日期: 2024-11-05
备注: This paper has been accepted at the Workshop on Lifelong Learning for Home Robots at the 8th Conference on Robot Learning (CoRL 2024), Munich, Germany
💡 一句话要点
提出多模态3D场景图更新器,用于共享动态环境下的机器人应用
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 3D场景图 动态环境 机器人感知 语义地图
📋 核心要点
- 现有3D场景图通常假设环境是静态的,无法应对真实世界中动态变化带来的挑战,影响机器人任务的执行。
- 该论文提出一个多模态框架,利用人类交互、机器人感知、时间信息和机器人动作等多源信息,实时更新3D场景图。
- 论文展示了初步实验结果,验证了所提框架在动态环境下维护场景图一致性的有效性,并为未来研究指明了方向。
📝 摘要(中文)
通用大语言模型(LLMs)和大型视觉模型(VLMs)的出现简化了语义增强地图的构建,使机器人能够将高层次的推理和规划融入到它们的表示中。3D场景图是最广泛使用的语义地图格式之一,它同时捕获了度量(低级)和语义(高级)信息。然而,这些地图通常假设一个静态的世界,而真实的家庭和办公室等环境是动态的。即使这些空间中的微小变化也会显著影响任务性能。为了将机器人集成到动态环境中,它们必须检测变化并实时更新场景图。这个更新过程本质上是多模态的,需要来自各种来源的输入,例如人类代理、机器人自身的感知系统、时间和它的动作。本文提出了一个框架,该框架利用这些多模态输入来保持实时操作期间场景图的一致性,展示了有希望的初步结果,并概述了未来研究的路线图。
🔬 方法详解
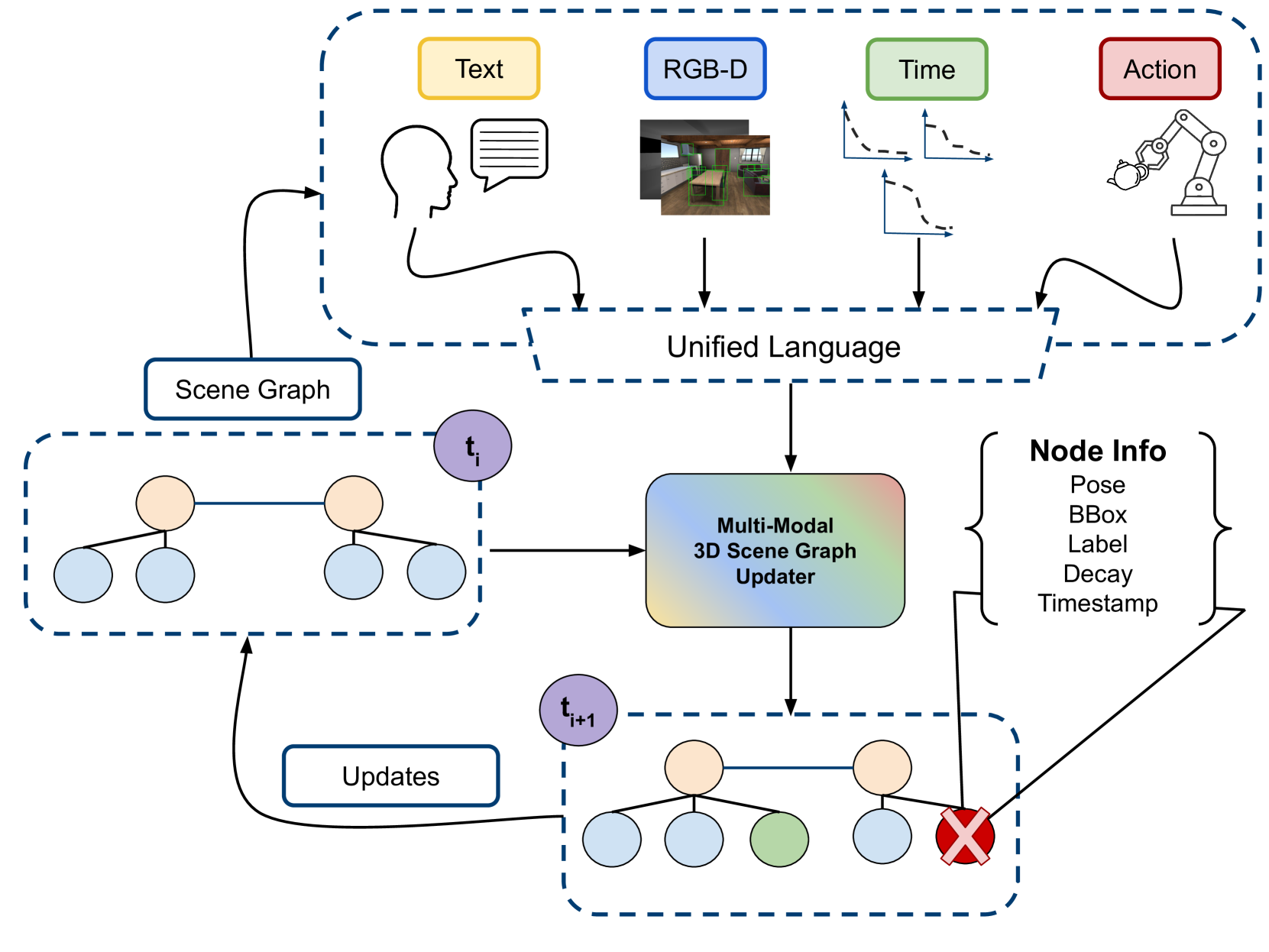
问题定义:论文旨在解决机器人如何在动态环境中维护3D场景图一致性的问题。现有的场景图构建方法大多假设环境是静态的,无法处理真实世界中物体移动、状态改变等动态情况。这导致机器人无法准确理解环境,进而影响其导航、操作等任务的性能。
核心思路:论文的核心思路是利用多模态信息融合来检测和更新场景图。通过整合来自人类指令、机器人自身的视觉和触觉感知、时间信息以及机器人执行的动作等多种模态的数据,可以更全面地了解环境的变化,从而更准确地更新场景图。这种多模态融合的方法能够克服单一模态信息的局限性,提高场景图更新的鲁棒性和准确性。
技术框架:该框架包含以下主要模块:1) 多模态数据采集模块,负责收集来自各种来源的数据,包括摄像头图像、深度信息、人类语音指令、机器人关节角度等。2) 特征提取模块,用于从不同模态的数据中提取有用的特征表示。例如,可以使用视觉模型提取图像中的物体类别和位置信息,使用语音识别模型提取人类指令中的语义信息。3) 场景图更新模块,该模块根据提取的特征和时间信息,判断场景中是否发生了变化,并相应地更新场景图。更新操作包括添加新的节点和边,修改现有节点和边的属性等。4) 一致性维护模块,用于确保更新后的场景图在语义和几何上保持一致性。
关键创新:该论文的关键创新在于提出了一个多模态融合的场景图更新框架,能够有效地处理动态环境中的变化。与传统的静态场景图构建方法相比,该框架能够实时地检测和更新场景图,从而使机器人能够更好地适应动态环境。此外,该框架还考虑了人类交互的作用,使机器人能够根据人类的指令来更新场景图。
关键设计:论文中未明确说明关键参数设置、损失函数、网络结构等技术细节。这些细节可能在后续的论文中进一步阐述。但是,多模态特征的有效融合以及场景图更新策略的设计是至关重要的。例如,可以使用注意力机制来融合不同模态的特征,并使用图神经网络来推理场景图中节点之间的关系。
🖼️ 关键图片
📊 实验亮点
摘要中提到“展示了有希望的初步结果”,但没有提供具体的性能数据或对比基线。因此,实验亮点部分信息未知。未来的研究可以关注在真实场景中进行更全面的实验评估,并与其他场景图构建和更新方法进行比较,以验证该框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于家庭服务机器人、仓储物流机器人、自动驾驶等领域。通过实时更新场景图,机器人可以更好地理解周围环境,从而更安全、更高效地完成任务。例如,家庭服务机器人可以根据场景图的变化来调整清洁路线,仓储物流机器人可以根据场景图的变化来重新规划路径,自动驾驶汽车可以根据场景图的变化来预测行人的行为。
📄 摘要(原文)
The advent of generalist Large Language Models (LLMs) and Large Vision Models (VLMs) have streamlined the construction of semantically enriched maps that can enable robots to ground high-level reasoning and planning into their representations. One of the most widely used semantic map formats is the 3D Scene Graph, which captures both metric (low-level) and semantic (high-level) information. However, these maps often assume a static world, while real environments, like homes and offices, are dynamic. Even small changes in these spaces can significantly impact task performance. To integrate robots into dynamic environments, they must detect changes and update the scene graph in real-time. This update process is inherently multimodal, requiring input from various sources, such as human agents, the robot's own perception system, time, and its actions. This work proposes a framework that leverages these multimodal inputs to maintain the consistency of scene graphs during real-time operation, presenting promising initial results and outlining a roadmap for future research.