RT-Affordance: Affordances are Versatile Intermediate Representations for Robot Manipulation
作者: Soroush Nasiriany, Sean Kirmani, Tianli Ding, Laura Smith, Yuke Zhu, Danny Driess, Dorsa Sadigh, Ted Xiao
分类: cs.RO, cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2024-11-05
💡 一句话要点
RT-Affordance:利用可供性作为机器人操作的通用中间表示
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 可供性 中间表示 分层模型 泛化能力
📋 核心要点
- 现有机器人操作方法依赖的中间表示(如语言、目标图像)存在上下文信息不足或过度指定的问题,导致泛化能力受限。
- RT-Affordance提出利用“可供性”作为中间表示,捕捉机器人关键姿态,实现表达性与轻量级的平衡,并易于用户指定。
- 实验表明,RT-Affordance在多种新任务上超越现有方法50%以上,并展现出对新环境的鲁棒性,验证了可供性作为中间表示的有效性。
📝 摘要(中文)
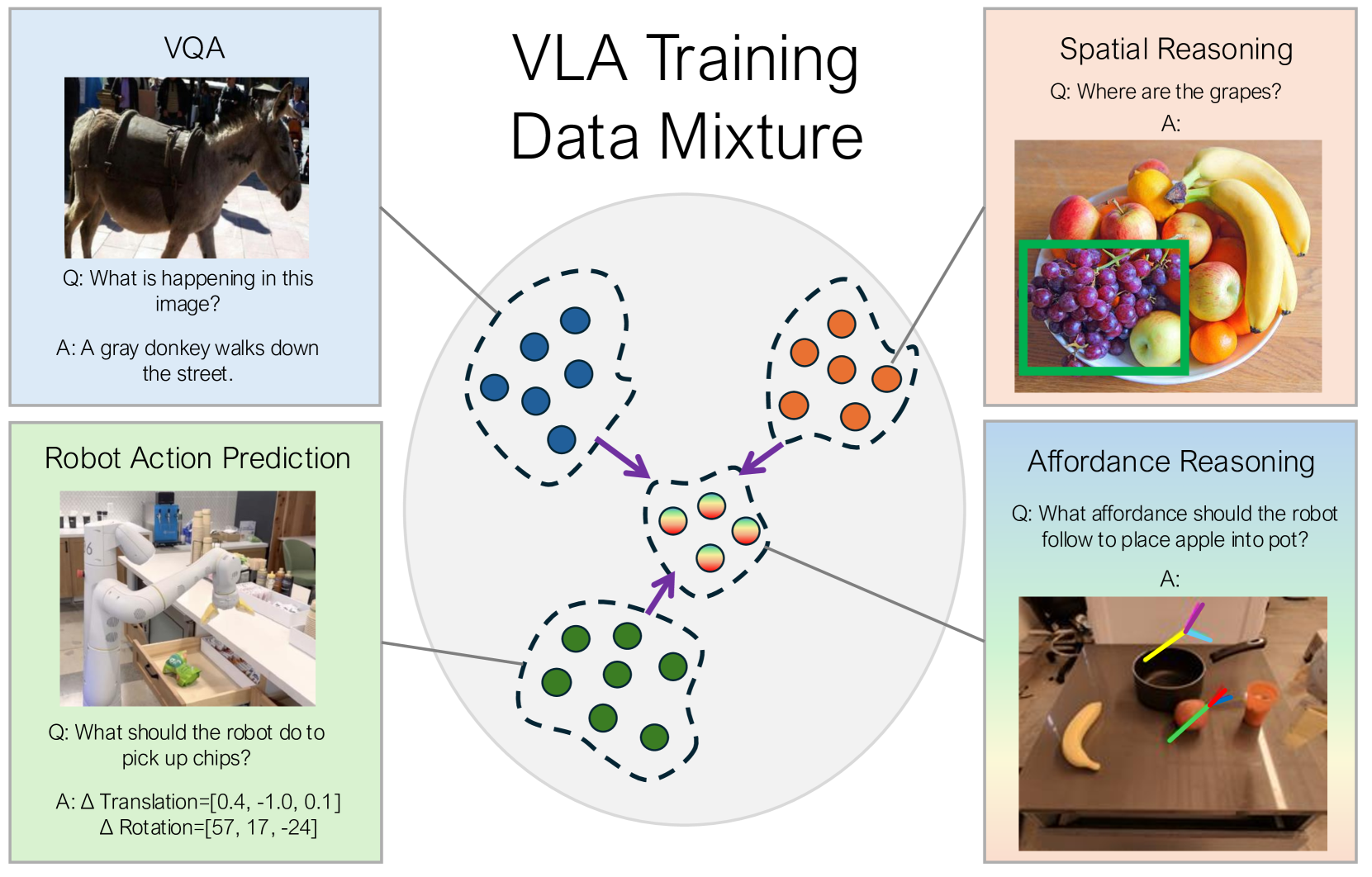
本文探讨了中间策略表示如何通过提供操作任务执行指导来促进泛化。现有的表示方法,如语言、目标图像和轨迹草图,已被证明是有帮助的,但这些表示要么没有提供足够的上下文信息,要么提供了过度指定的上下文,从而导致策略的鲁棒性降低。我们提出以可供性(affordances)为条件来制定策略,可供性捕捉了机器人在任务关键阶段的姿态。可供性提供了富有表现力且轻量级的抽象,用户易于指定,并通过从大型互联网数据集迁移知识来促进高效学习。我们的方法RT-Affordance是一个分层模型,它首先根据任务语言提出一个可供性计划,然后以该可供性计划为条件来执行操作。我们的模型可以灵活地桥接异构的监督来源,包括大型网络数据集和机器人轨迹。此外,我们还在易于收集的领域内可供性图像上训练我们的模型,从而允许我们在不收集任何额外昂贵的机器人轨迹的情况下学习新任务。在一组不同的新任务上,我们展示了RT-Affordance如何超过现有方法50%以上的性能,并且我们通过实验证明了可供性对于新环境的鲁棒性。
🔬 方法详解
问题定义:现有机器人操作任务的策略学习方法,依赖于语言、目标图像等中间表示,但这些表示要么缺乏足够的上下文信息,要么提供了过多的约束,限制了策略的泛化能力和鲁棒性。例如,直接使用语言指令可能过于抽象,而目标图像则可能对环境变化过于敏感。因此,需要一种更有效、更灵活的中间表示,能够更好地指导机器人完成操作任务。
核心思路:RT-Affordance的核心思路是利用“可供性”(Affordance)作为机器人操作任务的中间表示。可供性是指环境或物体为智能体提供的操作可能性,例如,一个把手“可供”抓握。通过将任务分解为一系列关键的可供性姿态,可以更清晰地指导机器人完成任务,同时保持一定的灵活性,从而提高泛化能力。这种方法借鉴了人类通过分解任务步骤来解决复杂问题的思路。
技术框架:RT-Affordance采用分层模型结构。第一层是可供性规划器(Affordance Planner),它接收任务语言指令作为输入,并生成一个可供性计划,即一系列关键的可供性姿态。第二层是策略执行器(Policy Executor),它以可供性计划为条件,控制机器人执行操作。整个流程可以概括为:语言指令 -> 可供性计划 -> 机器人动作。该框架允许模型利用来自不同来源的监督信息,包括大型网络数据集和机器人轨迹数据。
关键创新:RT-Affordance的关键创新在于将可供性作为机器人操作任务的中间表示。与传统的语言或目标图像相比,可供性提供了更具表达力且更轻量级的抽象。它既能提供足够的上下文信息来指导机器人操作,又不会过度约束策略,从而提高了泛化能力。此外,RT-Affordance还能够灵活地利用来自不同来源的监督信息,包括大型网络数据集和机器人轨迹数据,从而提高了学习效率。
关键设计:RT-Affordance模型的具体实现细节包括:使用Transformer网络进行可供性规划,将任务语言映射到可供性姿态序列;使用行为克隆(Behavior Cloning)或强化学习训练策略执行器,使其能够根据可供性计划生成机器人动作;利用领域自适应技术,将在大型网络数据集上预训练的模型迁移到机器人操作任务中。此外,论文还强调了收集廉价的领域内可供性图像的重要性,这有助于模型在不收集额外机器人轨迹的情况下学习新任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RT-Affordance在多个新颖的机器人操作任务上显著优于现有方法,性能提升超过50%。此外,实验还验证了可供性作为中间表示的鲁棒性,即使在新的环境中,RT-Affordance也能保持良好的性能。这些结果表明,RT-Affordance是一种有效且通用的机器人操作方法。
🎯 应用场景
RT-Affordance具有广泛的应用前景,可用于各种机器人操作任务,如家庭服务机器人、工业机器人、医疗机器人等。该方法能够提高机器人在复杂环境中的操作能力和泛化能力,使其能够更好地适应不同的任务需求。未来,RT-Affordance有望成为机器人操作领域的重要技术,推动机器人智能化发展。
📄 摘要(原文)
We explore how intermediate policy representations can facilitate generalization by providing guidance on how to perform manipulation tasks. Existing representations such as language, goal images, and trajectory sketches have been shown to be helpful, but these representations either do not provide enough context or provide over-specified context that yields less robust policies. We propose conditioning policies on affordances, which capture the pose of the robot at key stages of the task. Affordances offer expressive yet lightweight abstractions, are easy for users to specify, and facilitate efficient learning by transferring knowledge from large internet datasets. Our method, RT-Affordance, is a hierarchical model that first proposes an affordance plan given the task language, and then conditions the policy on this affordance plan to perform manipulation. Our model can flexibly bridge heterogeneous sources of supervision including large web datasets and robot trajectories. We additionally train our model on cheap-to-collect in-domain affordance images, allowing us to learn new tasks without collecting any additional costly robot trajectories. We show on a diverse set of novel tasks how RT-Affordance exceeds the performance of existing methods by over 50%, and we empirically demonstrate that affordances are robust to novel settings. Videos available at https://snasiriany.me/rt-affordance