Language-Driven Policy Distillation for Cooperative Driving in Multi-Agent Reinforcement Learning
作者: Jiaqi Liu, Chengkai Xu, Peng Hang, Jian Sun, Wei Zhan, Masayoshi Tomizuka, Mingyu Ding
分类: cs.RO
发布日期: 2024-10-31 (更新: 2025-08-09)
💡 一句话要点
提出LDPD:一种语言驱动的策略蒸馏方法,用于提升多智能体强化学习中的协同驾驶能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 协同驾驶 策略蒸馏 大型语言模型 知识迁移
📋 核心要点
- 现有MARL方法在协同驾驶中面临学习效率和性能方面的挑战,难以快速适应复杂环境。
- LDPD利用LLM作为教师,通过策略蒸馏将LLM的推理能力迁移到学生智能体,提升学习效率。
- 实验表明,LDPD方法能够使学生智能体快速提升性能,并最终超越教师智能体的表现。
📝 摘要(中文)
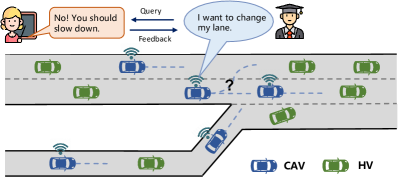
本文提出了一种语言驱动的策略蒸馏方法LDPD,旨在提升多智能体强化学习(MARL)在协同驾驶中的学习效率和性能。该方法利用大型语言模型(LLM)作为教师智能体,通过决策示范来指导较小的学生智能体进行协同决策。教师智能体增强了联网自动驾驶车辆(CAV)的观测信息,并利用LLM进行复杂的协同决策推理,同时借助精心设计的决策工具实现专家级的决策,从而提供高质量的教学经验。学生智能体通过梯度策略更新,将教师的先验知识提炼到自身模型中。实验结果表明,学生智能体可以在教师的少量指导下快速提升能力,并最终超越教师的性能。与基线方法相比,该方法在性能和学习效率方面均表现出更优越的性能。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习在协同驾驶场景中学习效率和性能不足的问题。现有的MARL方法通常需要大量的训练数据和时间才能达到理想的协同效果,并且难以泛化到新的场景。此外,如何有效地利用先验知识来指导智能体的学习也是一个挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,将其作为教师智能体,通过策略蒸馏的方式指导学生智能体的学习。LLM能够理解复杂的交通场景,并进行合理的协同决策,从而为学生智能体提供高质量的训练样本。
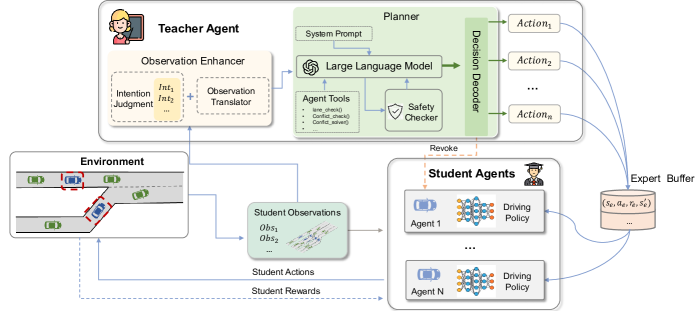
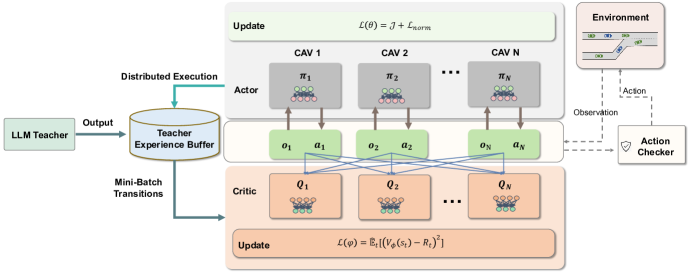
技术框架:LDPD框架包含两个主要部分:教师智能体和学生智能体。教师智能体首先增强CAV的观测信息,然后利用LLM进行协同决策推理,并使用决策工具生成专家级的决策。学生智能体则通过模仿教师智能体的行为,利用梯度策略更新来学习协同策略。整个过程类似于知识蒸馏,将LLM的知识迁移到学生智能体。
关键创新:该方法最重要的创新点在于将大型语言模型引入到多智能体强化学习中,利用LLM的推理能力来指导智能体的学习。与传统的MARL方法相比,LDPD能够更有效地利用先验知识,并显著提高学习效率。此外,通过策略蒸馏,可以将LLM的知识迁移到更小的学生智能体中,从而降低计算成本。
关键设计:教师智能体使用LLM进行决策推理,需要精心设计提示词(prompt)来引导LLM生成合理的行为。学生智能体使用梯度策略更新,损失函数包括行为克隆损失和强化学习损失。此外,论文还设计了决策工具,用于辅助教师智能体生成专家级的决策。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LDPD方法在协同驾驶任务中取得了显著的性能提升。学生智能体在少量教师指导下,能够快速提升性能,并最终超越教师智能体的表现。与基线方法相比,LDPD在学习效率和最终性能方面均表现出更优越的性能,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于智能交通系统、自动驾驶车辆编队控制、无人机协同作业等领域。通过利用LLM的推理能力,可以提升多智能体系统的协同效率和安全性,降低开发成本,加速智能交通技术的落地应用,并为未来的智能交通系统提供更强大的决策支持。
📄 摘要(原文)
The cooperative driving technology of Connected and Autonomous Vehicles (CAVs) is crucial for improving the efficiency and safety of transportation systems. Learning-based methods, such as Multi-Agent Reinforcement Learning (MARL), have demonstrated strong capabilities in cooperative decision-making tasks. However, existing MARL approaches still face challenges in terms of learning efficiency and performance. In recent years, Large Language Models (LLMs) have rapidly advanced and shown remarkable abilities in various sequential decision-making tasks. To enhance the learning capabilities of cooperative agents while ensuring decision-making efficiency and cost-effectiveness, we propose LDPD, a language-driven policy distillation method for guiding MARL exploration. In this framework, a teacher agent based on LLM trains smaller student agents to achieve cooperative decision-making through its own decision-making demonstrations. The teacher agent enhances the observation information of CAVs and utilizes LLMs to perform complex cooperative decision-making reasoning, which also leverages carefully designed decision-making tools to achieve expert-level decisions, providing high-quality teaching experiences. The student agent then refines the teacher's prior knowledge into its own model through gradient policy updates. The experiments demonstrate that the students can rapidly improve their capabilities with minimal guidance from the teacher and eventually surpass the teacher's performance. Extensive experiments show that our approach demonstrates better performance and learning efficiency compared to baseline methods.