SceneComplete: Open-World 3D Scene Completion in Cluttered Real World Environments for Robot Manipulation
作者: Aditya Agarwal, Gaurav Singh, Bipasha Sen, Tomás Lozano-Pérez, Leslie Pack Kaelbling
分类: cs.RO
发布日期: 2024-10-31 (更新: 2025-11-07)
💡 一句话要点
SceneComplete:面向机器人操作的杂乱真实环境三维场景补全
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 三维场景补全 机器人操作 RGB-D图像 预训练模型 场景理解 抓取建议 视觉-语言模型
📋 核心要点
- 现有方法难以从单视角RGB-D图像中准确重建完整的三维场景,尤其是在杂乱环境中,这限制了机器人操作的可靠性。
- SceneComplete通过组合多个预训练的通用感知模块,构建了一个新颖的流程,实现从单视角RGB-D图像到完整三维场景模型的重建。
- 实验表明,SceneComplete在大型基准数据集上实现了高精度的三维场景重建,并能够生成鲁棒的抓取建议,提升了机器人操作性能。
📝 摘要(中文)
为了在日常杂乱环境中进行精确的机器人操作,需要对三维场景有准确的理解,以便稳定可靠地抓取和放置物体,并避免与其他物体发生碰撞。通常,我们必须基于有限的输入(例如,单个RGB-D图像)来构建复杂场景的三维解释。本文介绍SceneComplete,一个从单视角构建完整、分割的三维场景模型的系统。SceneComplete是一个新颖的流程,它组合了通用的预训练感知模块(视觉-语言、分割、图像修复、图像到三维、视觉描述符和姿态估计),以获得高度准确的结果。我们在大型基准数据集上,通过与ground-truth模型对比,展示了其准确性和有效性,并表明其准确的完整物体重建能够实现鲁棒的抓取建议生成,包括对于灵巧手。
🔬 方法详解
问题定义:论文旨在解决在杂乱的真实世界环境中,如何从单个RGB-D图像中构建完整、分割的3D场景模型的问题。现有方法通常难以处理遮挡、噪声和不完整数据,导致重建的3D模型不准确,影响机器人操作的可靠性。
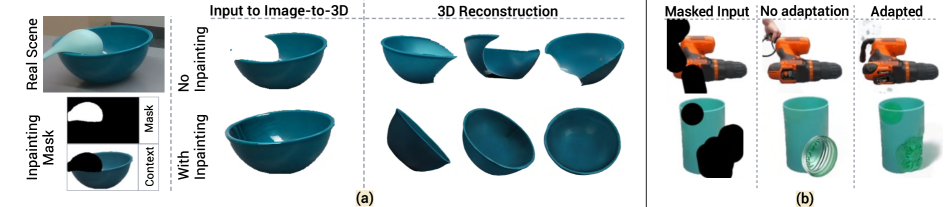
核心思路:论文的核心思路是利用预训练的通用感知模块,通过组合视觉-语言模型、分割模型、图像修复模型、图像到3D模型、视觉描述符和姿态估计等模块,构建一个完整的pipeline。这种方法能够充分利用现有模型的知识,提高3D场景重建的准确性和鲁棒性。
技术框架:SceneComplete的整体架构包含以下几个主要阶段:1) 输入RGB-D图像;2) 使用预训练的分割模型分割图像;3) 使用视觉-语言模型理解场景内容;4) 使用图像修复模型补全被遮挡的区域;5) 使用图像到3D模型生成初始的3D场景;6) 使用视觉描述符和姿态估计模块优化3D场景模型,使其更加准确和完整。
关键创新:SceneComplete的关键创新在于其pipeline的设计,它巧妙地组合了多个预训练的通用感知模块,避免了从头训练模型的复杂性,并充分利用了现有模型的知识。此外,SceneComplete还针对3D场景重建问题,对各个模块进行了优化和调整,使其能够更好地适应杂乱的真实世界环境。与现有方法相比,SceneComplete能够更准确地重建3D场景,并生成更鲁棒的抓取建议。
关键设计:论文中没有明确给出关键参数设置、损失函数和网络结构的具体细节。这些细节可能依赖于所使用的预训练模型。然而,pipeline的设计和模块之间的协同工作是关键。例如,视觉-语言模型用于指导图像修复模块,使其能够更准确地补全被遮挡的区域。图像到3D模型生成的初始3D场景,为后续的优化提供了基础。
🖼️ 关键图片


📊 实验亮点
论文在大型基准数据集上评估了SceneComplete的性能,并与ground-truth模型进行了比较。实验结果表明,SceneComplete能够准确地重建3D场景,并生成鲁棒的抓取建议。具体性能数据未知,但论文强调了其在完整物体重建方面的准确性,这使得它能够为灵巧手生成有效的抓取方案。
🎯 应用场景
SceneComplete在机器人操作领域具有广泛的应用前景,例如家庭服务机器人、工业机器人和自动驾驶汽车。它可以帮助机器人更好地理解周围环境,从而实现更安全、更可靠的物体抓取、放置和导航。此外,该技术还可以应用于虚拟现实、增强现实和三维建模等领域。
📄 摘要(原文)
Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image. We describe SceneComplete, a system for constructing a complete, segmented, 3D model of a scene from a single view. SceneComplete is a novel pipeline for composing general-purpose pretrained perception modules (vision-language, segmentation, image-inpainting, image-to-3D, visual-descriptors and pose-estimation) to obtain highly accurate results. We demonstrate its accuracy and effectiveness with respect to ground-truth models in a large benchmark dataset and show that its accurate whole-object reconstruction enables robust grasp proposal generation, including for a dexterous hand. We release the code and additional results on our website.