Robots Pre-train Robots: Manipulation-Centric Robotic Representation from Large-Scale Robot Datasets
作者: Guangqi Jiang, Yifei Sun, Tao Huang, Huanyu Li, Yongyuan Liang, Huazhe Xu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-10-29 (更新: 2024-10-30)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出操纵中心表示MCR,利用大规模机器人数据集预训练提升机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 预训练 视觉表征 操纵中心表示 对比学习 行为克隆 机器人操作 动力学信息
📋 核心要点
- 现有方法依赖人类视频预训练机器人视觉表征,存在分布偏移和缺乏动力学信息的问题。
- 论文提出操纵中心表示(MCR),通过对比学习和行为克隆,融合视觉特征与机器人动力学信息。
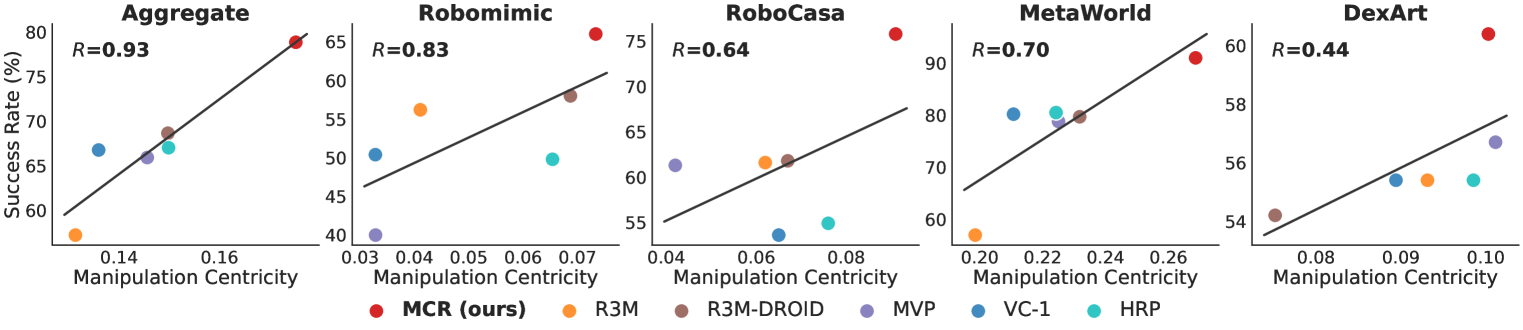
- 实验表明,MCR在模拟和真实环境中均显著提升了机器人操作任务的性能,最高提升76.9%。
📝 摘要(中文)
视觉表征的预训练提高了机器人学习的效率。由于缺乏大规模的领域内机器人数据集,先前的工作利用野外人类视频来预训练机器人视觉表征。尽管取得了有希望的结果,但来自人类视频的表征不可避免地会受到分布偏移的影响,并且缺乏对任务完成至关重要的动力学信息。我们首先评估了各种预训练表征与下游机器人操作任务的相关性(即操纵中心性)。有趣的是,我们发现“操纵中心性”是应用于下游任务时成功率的有力指标。基于这些发现,我们提出了操纵中心表示(MCR),这是一个基础表征学习框架,它捕获视觉特征以及操作任务的动作和本体感受等动力学信息,以提高操纵中心性。具体来说,我们在DROID机器人数据集上预训练视觉编码器,并利用运动相关数据,例如机器人本体感受状态和动作。我们引入了一种新颖的对比损失,该损失将视觉观察与机器人的本体感受状态-动作动力学对齐,结合类似行为克隆(BC)的actor损失来预测预训练期间的动作,以及时间对比损失。在具有20个任务的4个模拟域中的经验结果验证了MCR优于最强的基线方法14.8%。此外,MCR通过UR5e机械臂在3个真实世界任务上将数据高效学习的性能提高了76.9%。
🔬 方法详解
问题定义:现有机器人操作学习方法依赖于在人类视频上预训练的视觉表征,这导致了两个主要问题:一是人类视频与机器人操作任务之间存在分布偏移,二是人类视频缺乏机器人操作所需的关键动力学信息(如动作和本体感受)。因此,如何学习更适合机器人操作任务的视觉表征,并有效利用机器人自身的动力学信息,是本文要解决的核心问题。
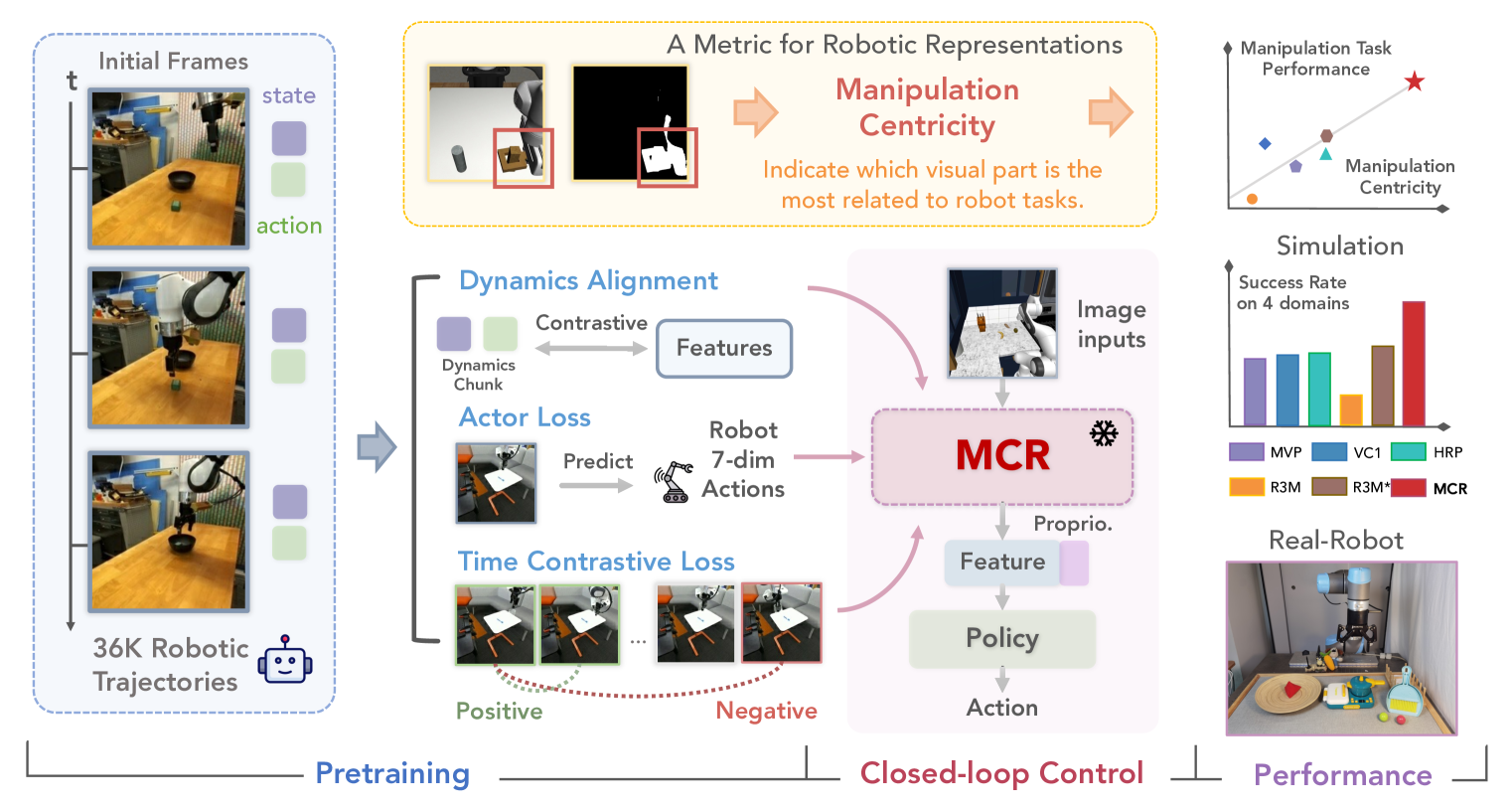
核心思路:论文的核心思路是学习一种“操纵中心”的表征,即该表征能够更好地反映机器人操作任务的本质特征,并包含足够的动力学信息。为了实现这一目标,论文提出了一种新的预训练框架,该框架利用大规模机器人数据集,通过对比学习和行为克隆等技术,将视觉信息与机器人的动作和本体感受信息相结合,从而学习到更有效的机器人操作表征。
技术框架:MCR框架主要包含以下几个模块:1) 视觉编码器:用于提取视觉特征;2) 对比学习模块:通过对比视觉观察和机器人本体感受状态-动作动力学,学习视觉表征与动力学信息之间的对应关系;3) 行为克隆模块:通过预测机器人的动作,学习视觉表征与动作之间的关系;4) 时间对比损失:增强表征的时间一致性。整体流程是,首先利用DROID数据集对视觉编码器进行预训练,然后利用对比学习和行为克隆模块对预训练的视觉编码器进行微调,最终得到操纵中心表示MCR。
关键创新:论文的关键创新在于提出了操纵中心表示(MCR)的概念,并设计了一种新的预训练框架来实现该目标。与现有方法相比,MCR更加关注机器人操作任务的本质特征,并有效利用了机器人自身的动力学信息。此外,论文还提出了一种新的对比损失,该损失能够更好地将视觉观察与机器人的本体感受状态-动作动力学对齐。
关键设计:在对比学习模块中,论文使用了一种InfoNCE损失函数,该函数旨在最大化正样本(即同一时刻的视觉观察和机器人状态-动作)之间的互信息,同时最小化负样本(即不同时刻的视觉观察和机器人状态-动作)之间的互信息。在行为克隆模块中,论文使用了一种交叉熵损失函数,该函数旨在最小化预测动作与真实动作之间的差异。时间对比损失使用了类似的InfoNCE损失,鼓励相邻时间步的表征相似。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MCR在4个模拟域的20个任务中,性能优于最强的基线方法14.8%。在3个真实世界任务中,MCR将数据高效学习的性能提高了76.9%。这些结果充分验证了MCR的有效性和优越性,表明其能够显著提升机器人操作任务的性能。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务中,例如物体抓取、装配、导航等。通过预训练的操纵中心表示,可以显著提高机器人学习的效率和性能,降低对大量人工标注数据的依赖。未来,该方法有望应用于更复杂的机器人任务,例如人机协作、自主探索等,推动机器人技术的进一步发展。
📄 摘要(原文)
The pre-training of visual representations has enhanced the efficiency of robot learning. Due to the lack of large-scale in-domain robotic datasets, prior works utilize in-the-wild human videos to pre-train robotic visual representation. Despite their promising results, representations from human videos are inevitably subject to distribution shifts and lack the dynamics information crucial for task completion. We first evaluate various pre-trained representations in terms of their correlation to the downstream robotic manipulation tasks (i.e., manipulation centricity). Interestingly, we find that the "manipulation centricity" is a strong indicator of success rates when applied to downstream tasks. Drawing from these findings, we propose Manipulation Centric Representation (MCR), a foundation representation learning framework capturing both visual features and the dynamics information such as actions and proprioceptions of manipulation tasks to improve manipulation centricity. Specifically, we pre-train a visual encoder on the DROID robotic dataset and leverage motion-relevant data such as robot proprioceptive states and actions. We introduce a novel contrastive loss that aligns visual observations with the robot's proprioceptive state-action dynamics, combined with a behavior cloning (BC)-like actor loss to predict actions during pre-training, along with a time contrastive loss. Empirical results across 4 simulation domains with 20 tasks verify that MCR outperforms the strongest baseline method by 14.8%. Moreover, MCR boosts the performance of data-efficient learning with a UR5e arm on 3 real-world tasks by 76.9%. Project website: https://robots-pretrain-robots.github.io/.