One-Step Diffusion Policy: Fast Visuomotor Policies via Diffusion Distillation
作者: Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, Yu Zeng
分类: cs.RO, cs.LG
发布日期: 2024-10-28
💡 一句话要点
提出OneDP,通过扩散蒸馏加速视觉运动策略,实现机器人实时控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 知识蒸馏 机器人控制 行为克隆 单步策略 实时控制 视觉运动策略
📋 核心要点
- 扩散模型在机器人控制中表现优异,但其迭代推理过程限制了在实时性要求高的场景中的应用。
- OneDP通过扩散蒸馏将扩散模型的知识转移到单步动作生成器,显著提升了推理速度。
- 实验表明,OneDP在模拟和真实机器人任务中均实现了SOTA性能,并将推理速度提升了一个数量级。
📝 摘要(中文)
扩散模型在生成任务中表现出色,并越来越多地应用于机器人领域,在行为克隆方面表现出卓越的性能。然而,其迭代去噪步骤导致的缓慢生成过程对资源受限的机器人和动态变化环境中的实时应用提出了挑战。本文提出了一种新颖的单步扩散策略(OneDP),该方法将预训练扩散策略的知识提炼成单步动作生成器,从而显著加快了机器人控制任务的响应时间。通过最小化扩散链上的Kullback-Leibler (KL)散度,确保提炼后的生成器与原始策略分布紧密对齐,仅需额外2%-10%的预训练成本即可收敛。在6个具有挑战性的模拟任务以及使用Franka机器人的4个自行设计的真实世界任务中评估了OneDP。结果表明,OneDP不仅实现了最先进的成功率,而且还实现了推理速度的数量级提升,将动作预测频率从1.5 Hz提高到62 Hz,确立了其在动态和计算受限的机器人应用中的潜力。
🔬 方法详解
问题定义:现有的基于扩散模型的机器人控制方法,虽然在行为克隆任务中表现出色,但由于其迭代式的去噪过程,导致推理速度较慢,难以满足实时性要求高的机器人应用场景,例如动态环境下的快速响应和资源受限的嵌入式平台。
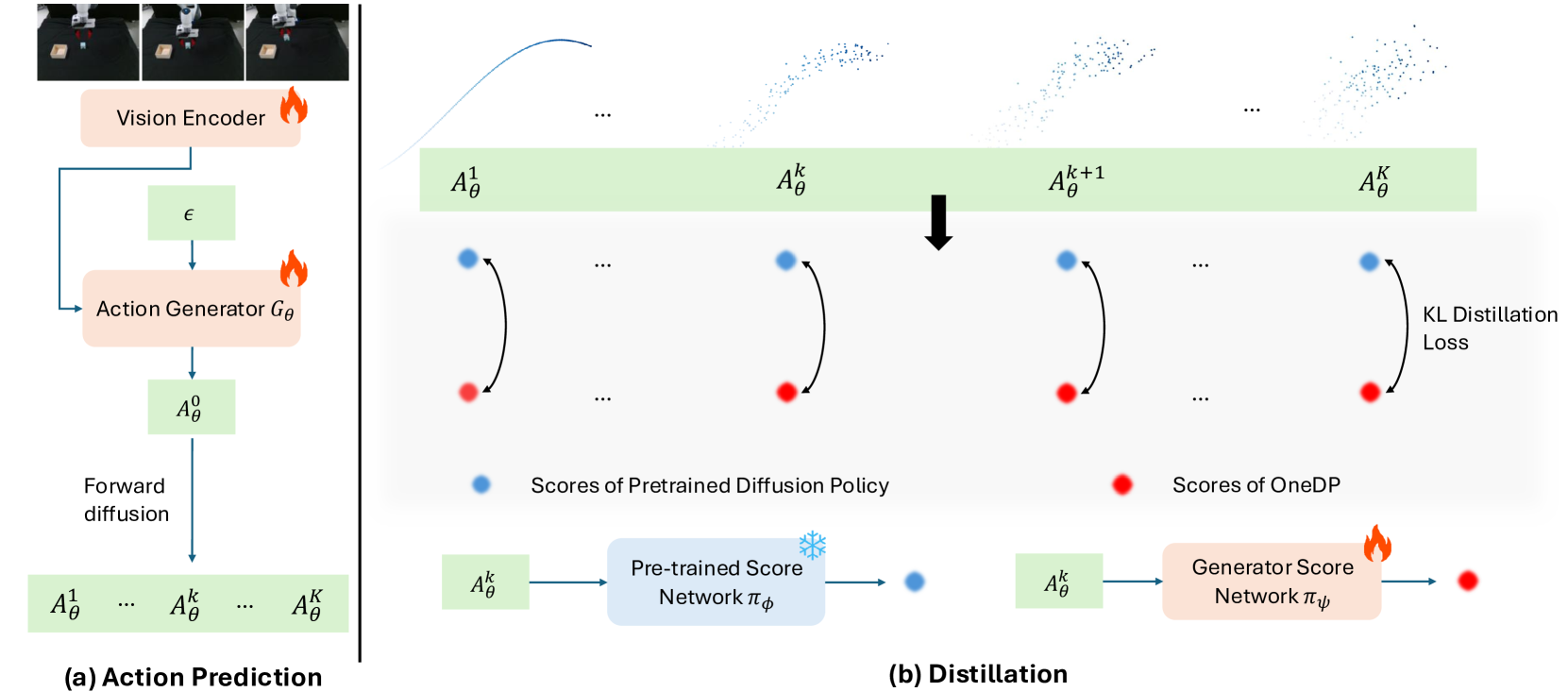
核心思路:OneDP的核心思路是通过知识蒸馏,将预训练的扩散策略(教师模型)的知识迁移到一个单步动作生成器(学生模型)中。这样,在推理阶段,学生模型可以直接一步生成动作,避免了扩散模型的迭代过程,从而显著提升推理速度。这种方法旨在保留原始扩散策略的性能,同时大幅降低计算成本。
技术框架:OneDP的技术框架主要包含两个阶段:1) 预训练扩散策略:使用标准的扩散模型进行行为克隆训练,得到一个高性能的策略模型。2) 扩散蒸馏:将预训练的扩散策略作为教师模型,训练一个单步动作生成器作为学生模型。在训练过程中,学生模型的目标是模仿教师模型在扩散过程中的行为,即在给定状态下,生成与教师模型相似的动作分布。
关键创新:OneDP最重要的技术创新点在于其扩散蒸馏方法,通过最小化扩散链上的KL散度,确保学生模型能够准确地学习到教师模型的策略分布。与传统的行为克隆方法相比,OneDP能够更好地保留原始扩散策略的性能,同时实现推理速度的显著提升。此外,OneDP只需要少量的额外预训练成本即可收敛。
关键设计:OneDP的关键设计包括:1) 损失函数:使用KL散度作为损失函数,衡量学生模型和教师模型在扩散过程中的动作分布差异。2) 网络结构:学生模型采用单步动作生成器,可以使用各种神经网络结构,例如MLP或Transformer。3) 训练策略:采用两阶段训练策略,首先预训练扩散策略,然后进行扩散蒸馏。4) 扩散链长度:选择合适的扩散链长度,以平衡性能和计算成本。
🖼️ 关键图片

📊 实验亮点
OneDP在多个模拟和真实机器人任务中取得了显著的成果。在模拟任务中,OneDP达到了与原始扩散策略相当的成功率,并在真实机器人任务中实现了最先进的性能。更重要的是,OneDP将动作预测频率从1.5 Hz提高到62 Hz,实现了数量级的推理速度提升,证明了其在实时机器人控制中的潜力。
🎯 应用场景
OneDP具有广泛的应用前景,尤其适用于需要实时控制和计算资源受限的机器人应用,例如无人机、自动驾驶、移动机器人等。该方法可以显著提升机器人在动态环境中的响应速度和适应能力,使其能够更好地完成各种复杂任务。此外,OneDP还可以应用于其他需要快速推理的生成任务,例如图像生成、语音合成等。
📄 摘要(原文)
Diffusion models, praised for their success in generative tasks, are increasingly being applied to robotics, demonstrating exceptional performance in behavior cloning. However, their slow generation process stemming from iterative denoising steps poses a challenge for real-time applications in resource-constrained robotics setups and dynamically changing environments. In this paper, we introduce the One-Step Diffusion Policy (OneDP), a novel approach that distills knowledge from pre-trained diffusion policies into a single-step action generator, significantly accelerating response times for robotic control tasks. We ensure the distilled generator closely aligns with the original policy distribution by minimizing the Kullback-Leibler (KL) divergence along the diffusion chain, requiring only $2\%$-$10\%$ additional pre-training cost for convergence. We evaluated OneDP on 6 challenging simulation tasks as well as 4 self-designed real-world tasks using the Franka robot. The results demonstrate that OneDP not only achieves state-of-the-art success rates but also delivers an order-of-magnitude improvement in inference speed, boosting action prediction frequency from 1.5 Hz to 62 Hz, establishing its potential for dynamic and computationally constrained robotic applications. We share the project page at https://research.nvidia.com/labs/dir/onedp/.