Guide-LLM: An Embodied LLM Agent and Text-Based Topological Map for Robotic Guidance of People with Visual Impairments
作者: Sangmim Song, Sarath Kodagoda, Amal Gunatilake, Marc G. Carmichael, Karthick Thiyagarajan, Jodi Martin
分类: cs.RO, cs.AI, cs.CL
发布日期: 2024-10-28 (更新: 2025-03-11)
💡 一句话要点
Guide-LLM:基于具身LLM和文本拓扑地图的视障人士机器人引导系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 大语言模型 机器人导航 视障辅助 文本拓扑地图
📋 核心要点
- 视障人士在导航方面面临巨大挑战,传统辅助工具在提供详细空间信息和精确引导方面存在不足。
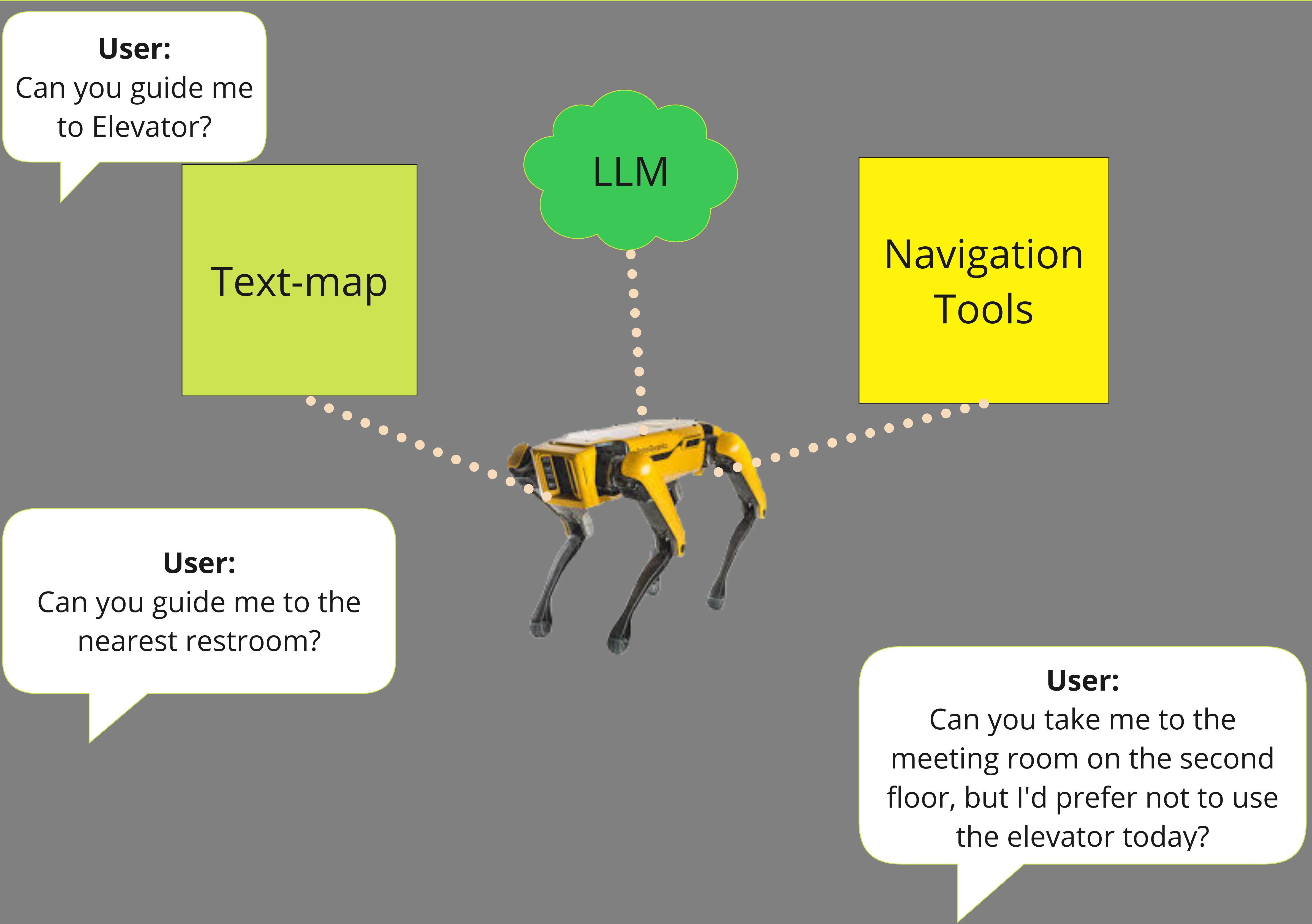
- Guide-LLM利用文本拓扑地图简化环境表示,结合LLM进行全局路径规划、危险检测和个性化路径规划。
- 模拟实验验证了Guide-LLM在引导视障人士方面的有效性,展示了其在辅助导航领域的潜力。
📝 摘要(中文)
本文提出Guide-LLM,一个基于具身大语言模型(LLM)的智能体,旨在辅助视障人士(PVI)在大型室内环境中导航。该方法采用一种新颖的基于文本的拓扑地图,使LLM能够利用简化的环境表示进行全局路径规划,重点关注直线路径和直角转弯,以方便导航。此外,该系统还利用LLM的常识推理能力进行危险检测,并根据用户偏好进行个性化路径规划。模拟实验表明,该系统在引导视障人士方面具有有效性,突显了其作为辅助技术重大进步的潜力。实验结果表明,Guide-LLM能够提供高效、自适应和个性化的导航辅助,预示着该领域有希望的进展。
🔬 方法详解
问题定义:视障人士在复杂室内环境中的导航是一个长期存在的难题。传统的辅助工具,如盲杖和导盲犬,虽然有用,但无法提供足够详细的空间信息和精确的导航指引,尤其是在大型、动态变化的环境中。现有的基于视觉的机器人导航方法,对于视障人士而言,缺乏有效的交互方式和个性化定制能力。
核心思路:Guide-LLM的核心思路是利用大语言模型(LLM)的强大推理和规划能力,结合简化的环境表示(文本拓扑地图),为视障人士提供个性化、安全的导航辅助。通过将复杂的环境信息抽象成易于理解和处理的文本形式,LLM可以更好地进行路径规划和决策。
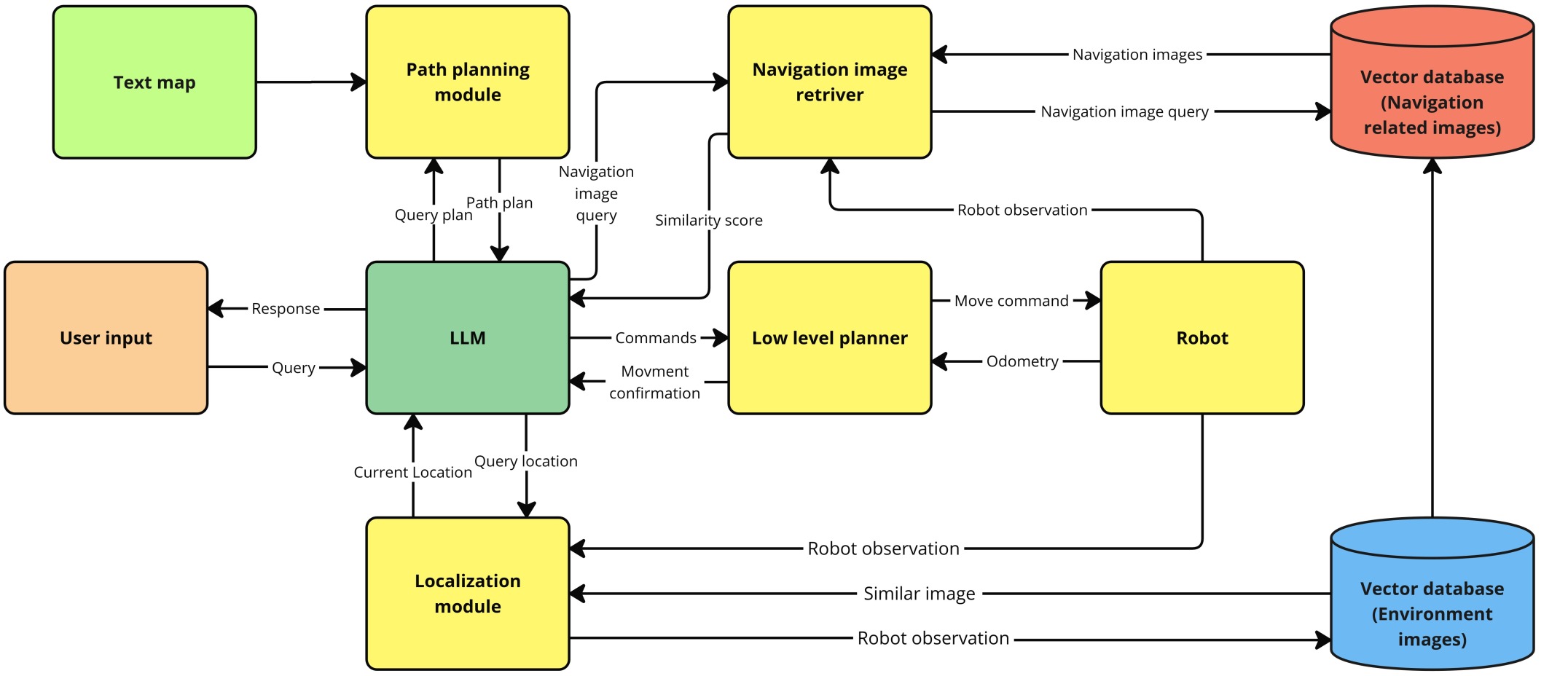
技术框架:Guide-LLM的整体架构包含以下几个主要模块:1) 环境感知模块:利用视觉-语言模型(VLM)将环境信息转换为文本描述,并构建文本拓扑地图,该地图由一系列节点(代表关键位置)和边(代表节点间的路径)组成。2) LLM规划模块:接收用户目标位置和当前位置信息,利用文本拓扑地图进行全局路径规划,生成一系列导航指令(如“直走”、“右转”)。3) 危险检测模块:利用LLM的常识推理能力,结合环境描述,识别潜在的危险因素(如障碍物、湿滑地面)。4) 语音交互模块:将导航指令和危险提示转换为语音输出,引导用户安全到达目的地。
关键创新:Guide-LLM的关键创新在于:1) 文本拓扑地图:将复杂的环境信息简化为易于LLM处理的文本形式,降低了计算复杂度,提高了导航效率。2) LLM驱动的导航:利用LLM的常识推理和规划能力,实现了个性化、自适应的导航辅助。3) 具身智能体:将LLM集成到机器人平台,实现了与环境的实时交互和感知。
关键设计:文本拓扑地图的关键设计在于节点的选择和边的构建。节点通常选择关键的转弯点、路口或地标性建筑。边则表示节点间的直线路径,并附带路径长度和方向信息。LLM的prompt设计至关重要,需要包含清晰的任务描述、环境信息、用户偏好等。危险检测模块利用LLM对环境描述进行分析,判断是否存在潜在的危险因素,并生成相应的提示信息。
🖼️ 关键图片

📊 实验亮点
论文通过模拟实验验证了Guide-LLM的有效性。实验结果表明,Guide-LLM能够成功引导视障人士到达目标位置,并能有效识别和规避潜在的危险因素。虽然论文中没有提供具体的性能数据和对比基线,但实验结果表明,Guide-LLM在导航效率、安全性和个性化方面具有显著优势。
🎯 应用场景
Guide-LLM具有广泛的应用前景,可用于辅助视障人士在各种室内环境中导航,如商场、医院、博物馆等。该技术还可以扩展到其他需要个性化导航服务的场景,如老年人辅助、儿童安全监护等。未来,结合更先进的传感器和更强大的LLM,Guide-LLM有望成为一种普及的智能辅助工具,显著提升弱势群体的生活质量。
📄 摘要(原文)
Navigation presents a significant challenge for persons with visual impairments (PVI). While traditional aids such as white canes and guide dogs are invaluable, they fall short in delivering detailed spatial information and precise guidance to desired locations. Recent developments in large language models (LLMs) and vision-language models (VLMs) offer new avenues for enhancing assistive navigation. In this paper, we introduce Guide-LLM, an embodied LLM-based agent designed to assist PVI in navigating large indoor environments. Our approach features a novel text-based topological map that enables the LLM to plan global paths using a simplified environmental representation, focusing on straight paths and right-angle turns to facilitate navigation. Additionally, we utilize the LLM's commonsense reasoning for hazard detection and personalized path planning based on user preferences. Simulated experiments demonstrate the system's efficacy in guiding PVI, underscoring its potential as a significant advancement in assistive technology. The results highlight Guide-LLM's ability to offer efficient, adaptive, and personalized navigation assistance, pointing to promising advancements in this field.