EfficientEQA: An Efficient Approach to Open-Vocabulary Embodied Question Answering
作者: Kai Cheng, Zhengyuan Li, Xingpeng Sun, Byung-Cheol Min, Amrit Singh Bedi, Aniket Bera
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-10-26 (更新: 2025-08-08)
备注: IROS 2025 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
EfficientEQA:一种高效的开放词汇具身问答方法,提升探索效率和答案准确性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 具身问答 视觉语言模型 主动探索 检索增强生成 机器人助手
📋 核心要点
- 现有具身问答方法缺乏主动探索或限制答案范围,难以应用于真实开放环境。
- EfficientEQA结合语义价值加权探索、自适应停止机制和检索增强生成,提升效率和准确性。
- 实验表明,EfficientEQA在答案准确率上提升超过15%,探索步骤减少超过20%。
📝 摘要(中文)
具身问答(EQA)是机器人助手的一项重要但具有挑战性的任务。大型视觉语言模型(VLMs)在EQA中展现出潜力,但现有方法要么将其视为静态视频问答而缺乏主动探索,要么将答案限制在封闭的选择集中。这些限制阻碍了实际应用,在实际应用中,机器人必须高效探索并在开放词汇设置中提供准确的答案。为了克服这些挑战,我们引入了EfficientEQA,这是一个将高效探索与自由形式答案生成相结合的新框架。EfficientEQA具有三个关键创新:(1)具有来自黑盒VLM的口头置信度的语义价值加权前沿探索(SFE),以优先探索语义上重要的区域,使智能体能够更快地收集相关信息;(2)一种基于BLIP相关性的机制,通过将高度相关的观察结果标记为异常值来适应性地停止,以指示智能体是否已收集到足够的信息;(3)一种用于VLM的检索增强生成(RAG)方法,用于基于来自智能体观察历史的相关图像准确地回答问题,而无需依赖预定义的选项。我们的实验结果表明,EfficientEQA的答案准确率比最先进的方法高出15%以上,并且所需的探索步骤减少了20%以上。我们的代码可在https://github.com/chengkaiAcademyCity/EfficientEQA获得。
🔬 方法详解
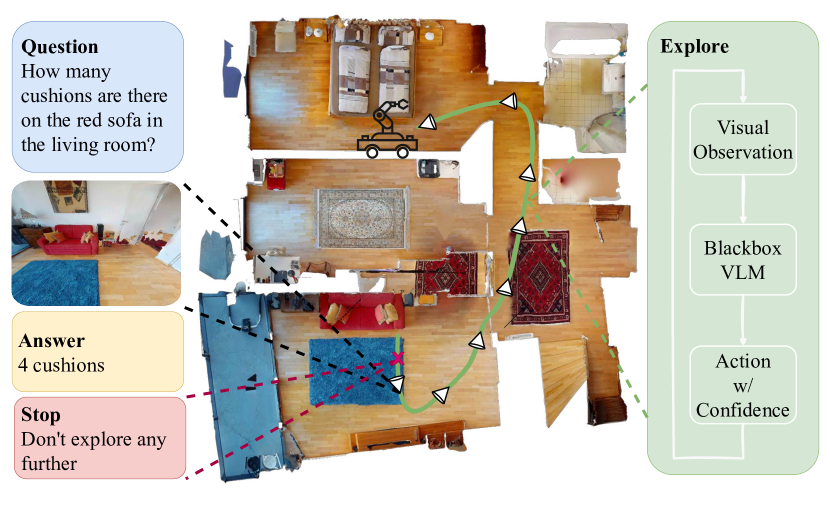
问题定义:论文旨在解决开放词汇具身问答(Open-Vocabulary Embodied Question Answering)问题。现有方法主要存在两个痛点:一是将EQA视为静态视频问答,忽略了主动探索的重要性;二是将答案限制在预定义的封闭集合中,无法应对真实世界中开放式的提问方式。
核心思路:EfficientEQA的核心思路是通过高效的探索策略和检索增强的答案生成,使智能体能够在开放环境中快速找到相关信息并准确回答问题。该方法旨在模仿人类在未知环境中探索和学习的方式,即优先关注语义信息丰富的区域,并根据已收集的信息判断何时停止探索。
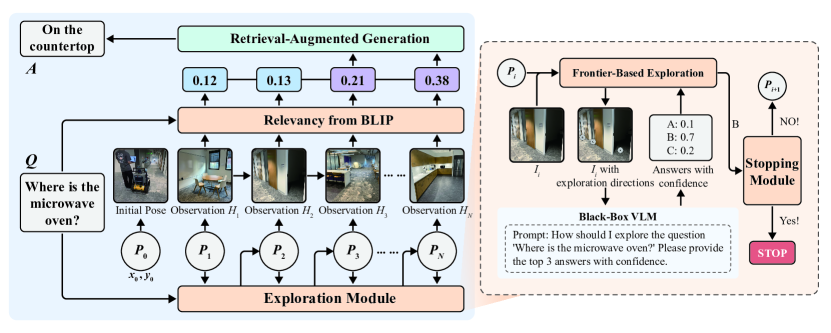
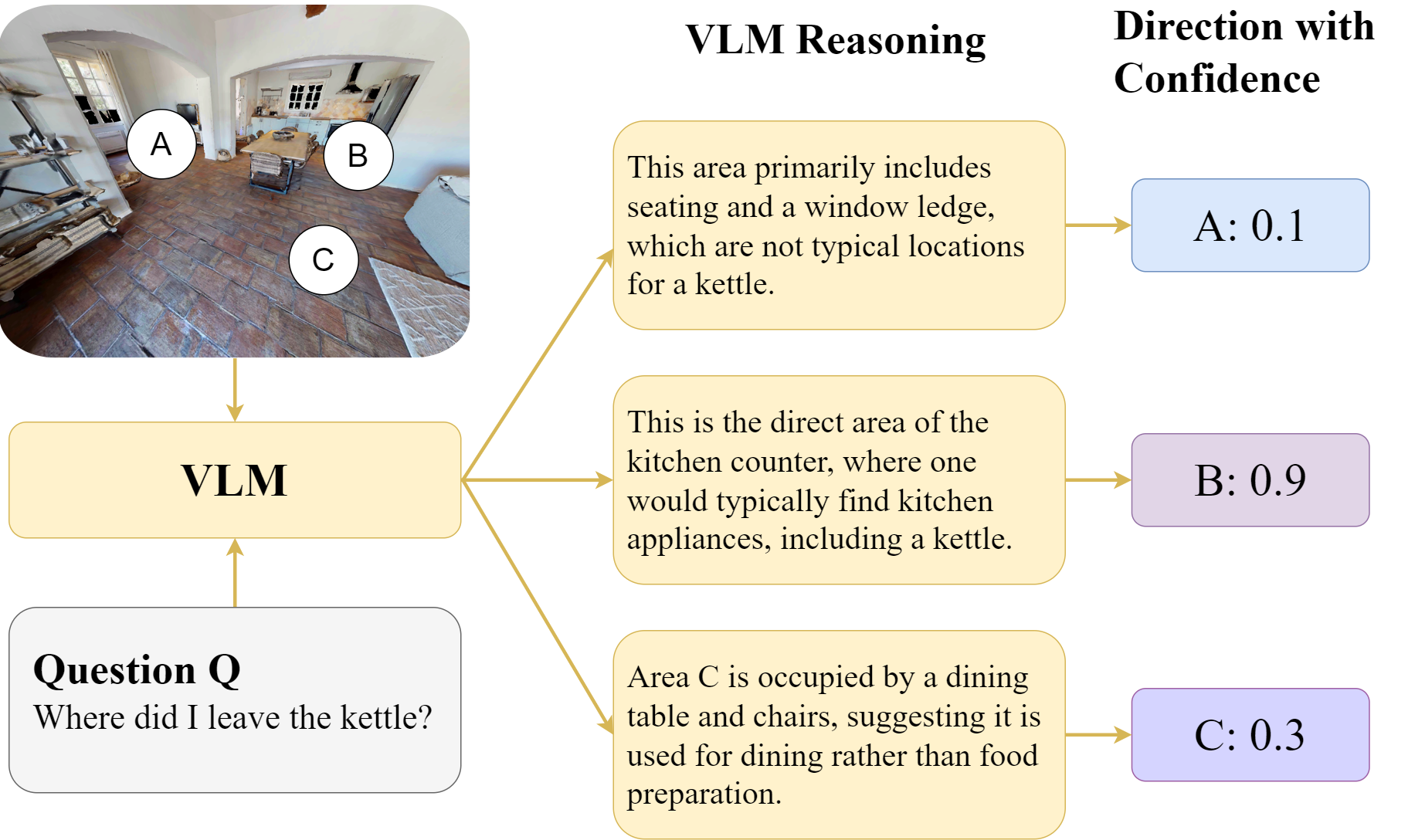
技术框架:EfficientEQA的整体框架包含三个主要模块:(1) 语义价值加权前沿探索(SFE):利用视觉语言模型(VLM)评估场景中不同区域的语义价值,并优先探索价值高的区域。(2) 基于BLIP相关性的自适应停止机制:使用BLIP模型判断当前观察到的图像与问题是否相关,当相关性达到一定阈值时,停止探索。(3) 检索增强生成(RAG):从智能体的观察历史中检索与问题相关的图像,并利用VLM基于这些图像生成答案。
关键创新:EfficientEQA的关键创新在于将高效探索与自由形式答案生成相结合。具体来说,SFE通过语义价值引导探索方向,提高了信息收集效率;自适应停止机制避免了不必要的探索,节省了计算资源;RAG则允许VLM在开放词汇环境下生成准确的答案,无需依赖预定义的选项。
关键设计:SFE中,语义价值的计算依赖于黑盒VLM的置信度输出,并结合了探索区域的距离信息。自适应停止机制中,BLIP模型的相关性阈值需要根据具体任务进行调整。RAG中,检索到的图像数量和VLM的生成策略也会影响最终的答案质量。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EfficientEQA在iTHOR数据集上取得了显著的性能提升。与最先进的方法相比,EfficientEQA的答案准确率提高了15%以上,同时所需的探索步骤减少了20%以上。这些结果验证了EfficientEQA在开放词汇具身问答任务中的有效性和高效性。
🎯 应用场景
EfficientEQA可应用于各种机器人助手场景,例如家庭服务机器人、导览机器人和搜索救援机器人。该方法能够使机器人在未知环境中高效地探索和学习,并准确地回答用户提出的问题,从而提高机器人的实用性和智能化水平。未来,该技术有望应用于更复杂的任务,例如自主导航、目标识别和人机协作。
📄 摘要(原文)
Embodied Question Answering (EQA) is an essential yet challenging task for robot assistants. Large vision-language models (VLMs) have shown promise for EQA, but existing approaches either treat it as static video question answering without active exploration or restrict answers to a closed set of choices. These limitations hinder real-world applicability, where a robot must explore efficiently and provide accurate answers in open-vocabulary settings. To overcome these challenges, we introduce EfficientEQA, a novel framework that couples efficient exploration with free-form answer generation. EfficientEQA features three key innovations: (1) Semantic-Value-Weighted Frontier Exploration (SFE) with Verbalized Confidence (VC) from a black-box VLM to prioritize semantically important areas to explore, enabling the agent to gather relevant information faster; (2) a BLIP relevancy-based mechanism to stop adaptively by flagging highly relevant observations as outliers to indicate whether the agent has collected enough information; and (3) a Retrieval-Augmented Generation (RAG) method for the VLM to answer accurately based on pertinent images from the agent's observation history without relying on predefined choices. Our experimental results show that EfficientEQA achieves over 15% higher answer accuracy and requires over 20% fewer exploration steps than state-of-the-art methods. Our code is available at: https://github.com/chengkaiAcademyCity/EfficientEQA