DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance Control
作者: Md Faizal Karim, Shreya Bollimuntha, Mohammed Saad Hashmi, Autrio Das, Gaurav Singh, Srinath Sridhar, Arun Kumar Singh, Nagamanikandan Govindan, K Madhava Krishna
分类: cs.RO
发布日期: 2024-10-25
💡 一句话要点
DA-VIL:基于强化学习和变阻抗控制的自适应双臂操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双臂操作 强化学习 变阻抗控制 机器人控制 轨迹跟踪
📋 核心要点
- 双臂操作需要精确协调和动态适应性,现有方法难以有效管理手臂与物体间的交互力。
- 该论文提出一种结合策略学习和梯度优化的新流程,动态调节阻抗,提升双臂操作的稳定性和灵活性。
- 实验结果表明,该方法在轨迹跟踪任务中优于其他三种已建立的双臂机器人控制方法。
📝 摘要(中文)
双臂操作是机器人领域日益增长的研究方向。使机器人能够执行需要协调使用双臂的任务,对于处理大型物体、组装部件和执行类人交互等复杂操作至关重要。然而,实现有效的双臂操作面临诸多挑战,包括精确协调、动态适应性以及管理手臂与被操作物体之间的交互力。我们提出了一种新颖的流程,结合了基于环境反馈的策略学习和基于梯度的优化,以学习控制输出所需的控制器增益。这使得机器人系统能够根据任务需求动态调节其阻抗,从而确保双臂操作的稳定性和灵活性。我们在涉及各种具有不同质量和几何形状的大型复杂物体的轨迹跟踪任务中评估了我们的流程。然后将性能与用于控制双臂机器人的其他三种已建立的方法进行比较,证明了优越的结果。
🔬 方法详解
问题定义:双臂操作需要精确的协调控制,以应对不同质量和几何形状的物体。现有的双臂控制方法在动态适应性和处理交互力方面存在不足,难以保证操作的稳定性和灵活性。因此,需要一种能够根据任务需求动态调节阻抗的控制方法。
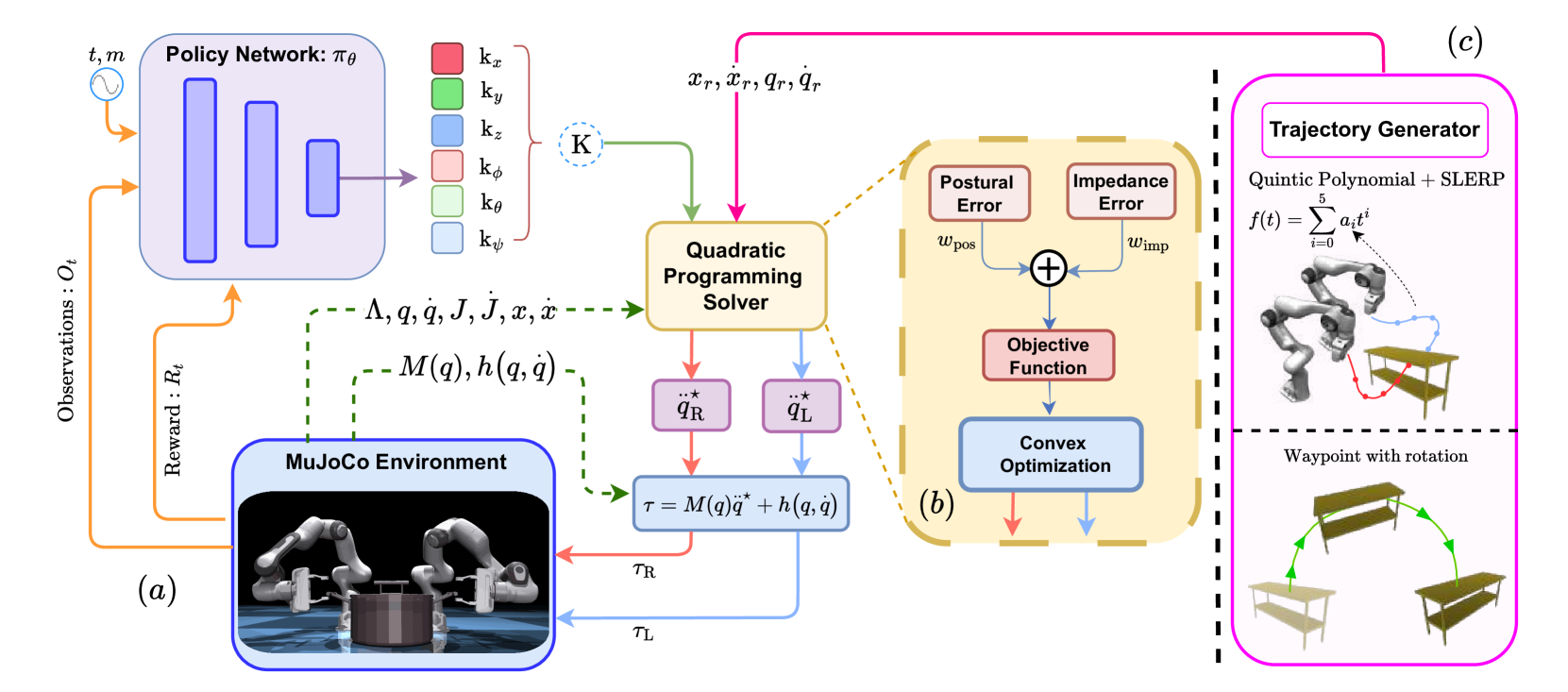
核心思路:论文的核心思路是将强化学习与变阻抗控制相结合。强化学习用于从环境反馈中学习控制策略,而变阻抗控制则允许机器人动态调节其阻抗,以适应不同的任务需求。通过结合这两种方法,机器人可以更好地处理交互力,并实现更稳定、更灵活的双臂操作。
技术框架:该论文提出的技术框架包含以下主要模块:1) 策略学习模块:使用强化学习算法(具体算法未知)从环境反馈中学习控制策略。2) 梯度优化模块:使用梯度优化算法来优化控制器增益,从而实现变阻抗控制。3) 阻抗控制模块:根据学习到的控制策略和优化的控制器增益,动态调节机器人的阻抗。整体流程是,首先通过强化学习获得初步的控制策略,然后通过梯度优化进一步调整控制器的参数,最后通过阻抗控制实现精确的双臂操作。
关键创新:该论文的关键创新在于将强化学习与变阻抗控制相结合,提出了一种自适应的双臂操作方法。与传统的双臂控制方法相比,该方法能够根据任务需求动态调节阻抗,从而更好地处理交互力,并实现更稳定、更灵活的操作。这种结合使得机器人能够更好地适应不同的环境和任务,提高了双臂操作的鲁棒性和泛化能力。
关键设计:论文中关于强化学习算法、梯度优化算法以及阻抗控制的具体实现细节未知。但是,可以推测,强化学习算法的选择需要考虑到双臂操作的连续动作空间和高维状态空间。梯度优化算法需要能够有效地优化控制器增益,以实现期望的阻抗特性。阻抗控制器的设计需要考虑到双臂的动力学特性和交互力。
🖼️ 关键图片


📊 实验亮点
该论文通过实验验证了所提出方法的有效性。在轨迹跟踪任务中,该方法在处理不同质量和几何形状的物体时,表现出优于其他三种已建立的双臂机器人控制方法的性能。具体的性能数据和提升幅度未知,但摘要中明确指出该方法取得了“superior results”。
🎯 应用场景
该研究成果可应用于各种需要双臂协调操作的场景,例如工业自动化中的零部件组装、医疗手术中的辅助操作、以及家庭服务机器人中的物品搬运等。通过提高双臂操作的稳定性和灵活性,可以显著提升生产效率和服务质量,并为机器人技术在复杂环境中的应用开辟新的可能性。
📄 摘要(原文)
Dual-arm manipulation is an area of growing interest in the robotics community. Enabling robots to perform tasks that require the coordinated use of two arms, is essential for complex manipulation tasks such as handling large objects, assembling components, and performing human-like interactions. However, achieving effective dual-arm manipulation is challenging due to the need for precise coordination, dynamic adaptability, and the ability to manage interaction forces between the arms and the objects being manipulated. We propose a novel pipeline that combines the advantages of policy learning based on environment feedback and gradient-based optimization to learn controller gains required for the control outputs. This allows the robotic system to dynamically modulate its impedance in response to task demands, ensuring stability and dexterity in dual-arm operations. We evaluate our pipeline on a trajectory-tracking task involving a variety of large, complex objects with different masses and geometries. The performance is then compared to three other established methods for controlling dual-arm robots, demonstrating superior results.