Visual Imitation Learning of Non-Prehensile Manipulation Tasks with Dynamics-Supervised Models
作者: Abdullah Mustafa, Ryo Hanai, Ixchel Ramirez, Floris Erich, Ryoichi Nakajo, Yukiyasu Domae, Tetsuya Ogata
分类: cs.RO
发布日期: 2024-10-25
备注: Accepted to IEEE CASE 2024
💡 一句话要点
提出动力学监督的视觉模仿学习方法,提升非抓取操作任务的泛化性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉模仿学习 非抓取操作 动力学监督 世界模型 机器人控制
📋 核心要点
- 现有视觉模仿学习方法泛化性差,通常学习任务特定特征,难以适应新环境。
- 论文提出动力学监督的世界模型,通过预测物体位姿、速度和加速度来学习更通用的特征。
- 实验表明,该方法显著提升了非抓取操作任务的性能,尤其是在世界模型预训练阶段。
📝 摘要(中文)
与准静态操作任务(如抓取放置)不同,动态任务(如非抓取操作)对基于视觉的控制提出了更大的挑战。成功的控制需要提取与目标任务相关的特征。在视觉模仿学习中,这些特征可以通过反向传播策略损失来学习,但这种方法通常学习到任务特定的特征,泛化性有限。本文提出通过直接监督目标动态状态(动力学映射)来学习更好的动力学信息世界模型。除了RGB重建,世界模型还被训练来直接预测环境刚体的位姿、速度和加速度。在“平衡-到达”和“落箱”两个非抓取2D环境中验证了该假设。动力学映射增强了不同训练配置和策略架构下的任务性能。尤其是在世界模型预训练中,成功率从21%提高到85%。虽然冻结的动力学信息世界模型可以很好地泛化到具有域内动力学的任务,但对于具有域外动力学的任务则表现不佳。
🔬 方法详解
问题定义:现有的视觉模仿学习方法在处理非抓取操作等动态任务时,面临泛化性挑战。这些方法通常依赖于直接从视觉输入到动作的端到端学习,导致模型过度拟合训练数据,难以适应新的环境和任务。痛点在于,模型学习到的特征是任务特定的,缺乏对底层物理动力学的理解。
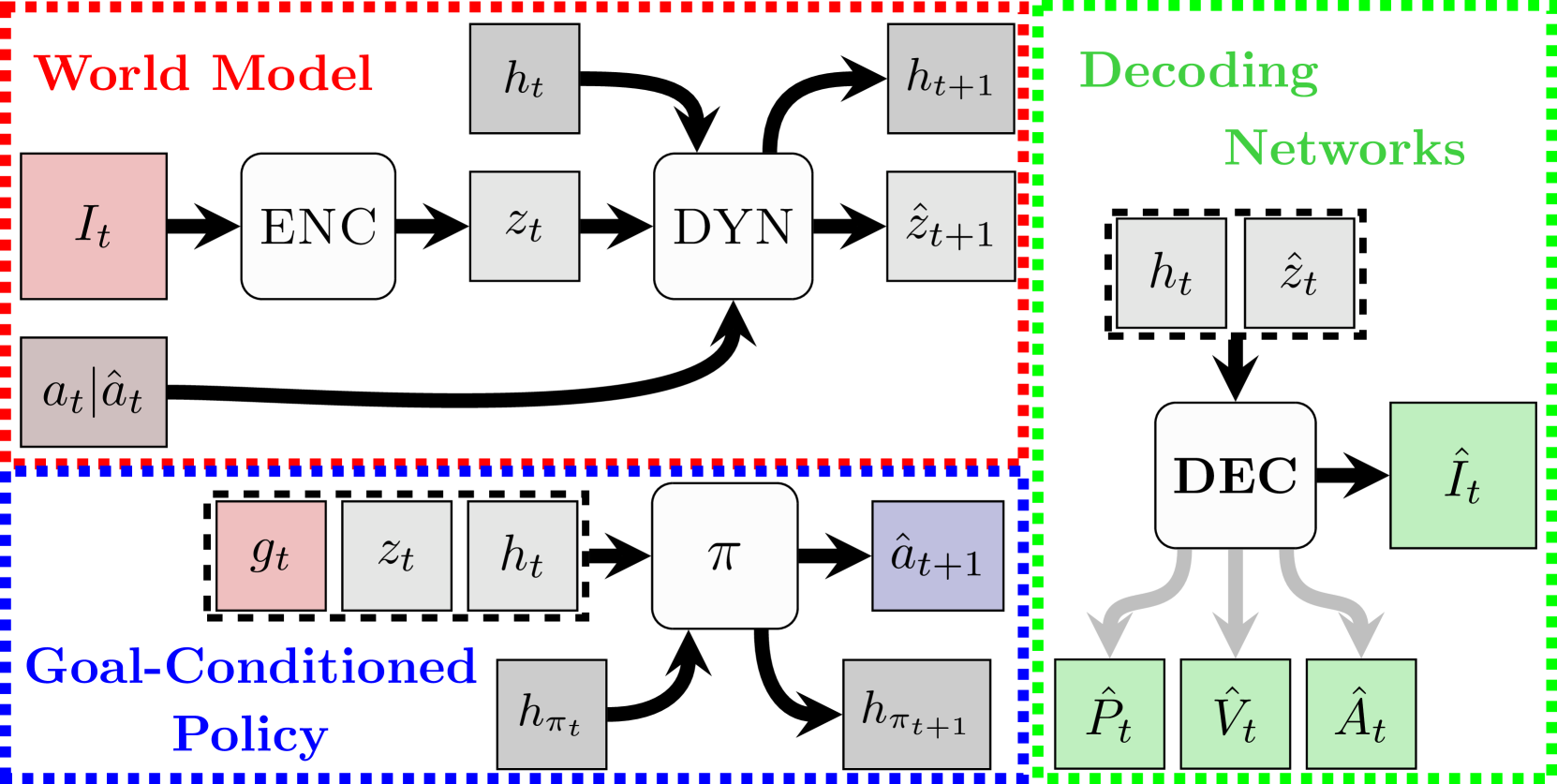
核心思路:论文的核心思路是通过引入动力学监督来增强世界模型的学习能力。具体来说,除了传统的RGB图像重建,模型还被训练来直接预测环境中刚体的位姿、速度和加速度等动力学状态。这样做的目的是让模型学习到更丰富的、与任务相关的动力学信息,从而提高模型的泛化能力。
技术框架:整体框架包含两个主要阶段:首先,使用动力学监督训练世界模型,使其能够从视觉输入中预测环境的动力学状态。然后,利用训练好的世界模型作为视觉特征提取器,训练一个策略网络来执行特定的操作任务。策略网络的输入是世界模型提取的特征,输出是控制机器人的动作。论文探讨了不同的训练配置,包括解耦训练、联合训练和端到端训练。
关键创新:最重要的创新点在于引入了动力学映射,即直接监督世界模型预测环境的动力学状态。与传统的只预测RGB图像的方法相比,动力学映射能够让模型学习到更丰富的、与任务相关的动力学信息,从而提高模型的泛化能力。
关键设计:论文设计了一个2D非抓取操作环境,包含“平衡-到达”和“落箱”两个任务。世界模型采用卷积神经网络提取视觉特征,并使用循环神经网络预测动力学状态。损失函数包括RGB重建损失和动力学预测损失。动力学预测损失计算预测的位姿、速度和加速度与真实值之间的均方误差。策略网络可以使用前馈网络或循环神经网络。
🖼️ 关键图片

📊 实验亮点
实验结果表明,动力学映射显著提升了非抓取操作任务的性能。在世界模型预训练阶段,成功率从21%提高到85%。即使冻结世界模型,其在域内动力学任务上的泛化能力也优于传统方法。这些结果验证了动力学监督的有效性,并表明该方法能够学习到更通用的视觉特征。
🎯 应用场景
该研究成果可应用于机器人非抓取操作、物体操控、自动驾驶等领域。通过学习动力学信息,机器人可以更好地理解环境,从而执行更复杂的任务。例如,可以应用于物流分拣、自动化装配、家庭服务机器人等场景,提升机器人的智能化水平和适应能力。未来,该方法有望扩展到更复杂的3D环境和更广泛的机器人任务。
📄 摘要(原文)
Unlike quasi-static robotic manipulation tasks like pick-and-place, dynamic tasks such as non-prehensile manipulation pose greater challenges, especially for vision-based control. Successful control requires the extraction of features relevant to the target task. In visual imitation learning settings, these features can be learnt by backpropagating the policy loss through the vision backbone. Yet, this approach tends to learn task-specific features with limited generalizability. Alternatively, learning world models can realize more generalizable vision backbones. Utilizing the learnt features, task-specific policies are subsequently trained. Commonly, these models are trained solely to predict the next RGB state from the current state and action taken. But only-RGB prediction might not fully-capture the task-relevant dynamics. In this work, we hypothesize that direct supervision of target dynamic states (Dynamics Mapping) can learn better dynamics-informed world models. Beside the next RGB reconstruction, the world model is also trained to directly predict position, velocity, and acceleration of environment rigid bodies. To verify our hypothesis, we designed a non-prehensile 2D environment tailored to two tasks: "Balance-Reaching" and "Bin-Dropping". When trained on the first task, dynamics mapping enhanced the task performance under different training configurations (Decoupled, Joint, End-to-End) and policy architectures (Feedforward, Recurrent). Notably, its most significant impact was for world model pretraining boosting the success rate from 21% to 85%. Although frozen dynamics-informed world models could generalize well to a task with in-domain dynamics, but poorly to a one with out-of-domain dynamics.