A generic approach for reactive stateful mitigation of application failures in distributed robotics systems deployed with Kubernetes
作者: Florian Mirus, Frederik Pasch, Nikhil Singhal, Kay-Ulrich Scholl
分类: cs.RO
发布日期: 2024-10-24 (更新: 2024-11-04)
💡 一句话要点
提出基于行为树的通用方法,用于Kubernetes部署的分布式机器人系统故障反应式状态缓解。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 分布式机器人系统 Kubernetes 故障缓解 行为树 ROS2 自主移动机器人 机器人操作
📋 核心要点
- 现有云原生领域的故障缓解方法难以满足复杂机器人系统与物理世界交互的特殊挑战和需求。
- 该方法利用行为树的通用性,实现机器人系统的监控和有状态的、反应式的故障缓解,适用于各种机器人任务。
- 在AMR导航和机器人操作的模拟实验中,验证了该方法在不同应用场景下的有效性和通用性。
📝 摘要(中文)
本文提出了一种新颖的方法,用于在Kubernetes (K8s) 和机器人操作系统 (ROS2) 部署的分布式机器人系统中,进行机器人系统监控和有状态的、反应式的故障缓解。针对机器人系统在边缘或云端卸载计算密集型算法时,面临的计算和能源资源限制问题,以及云原生应用在Kubernetes部署中确保针对各种类型故障的弹性问题,该方法利用行为树的通用底层结构,适用于任何机器人工作负载,并支持任意复杂的监控和故障缓解策略。通过在模拟环境中对自主移动机器人 (AMR) 导航和机器人操作两个示例应用进行验证,证明了该方法的有效性和应用无关性。
🔬 方法详解
问题定义:在Kubernetes部署的分布式机器人系统中,如何有效地监控和缓解各种类型的故障,以保证系统的稳定性和可靠性。现有云原生领域的故障缓解方法通常无法满足机器人系统与物理世界交互的特殊需求,例如状态保持、实时响应等。
核心思路:利用行为树(Behavior Trees, BTs)的通用性和灵活性,构建一个通用的故障监控和缓解框架。行为树可以清晰地描述复杂的行为逻辑,并且易于扩展和修改,从而适应不同的机器人应用和故障场景。通过状态化的故障缓解,可以保证系统在故障发生后能够恢复到之前的状态,避免数据丢失和任务中断。
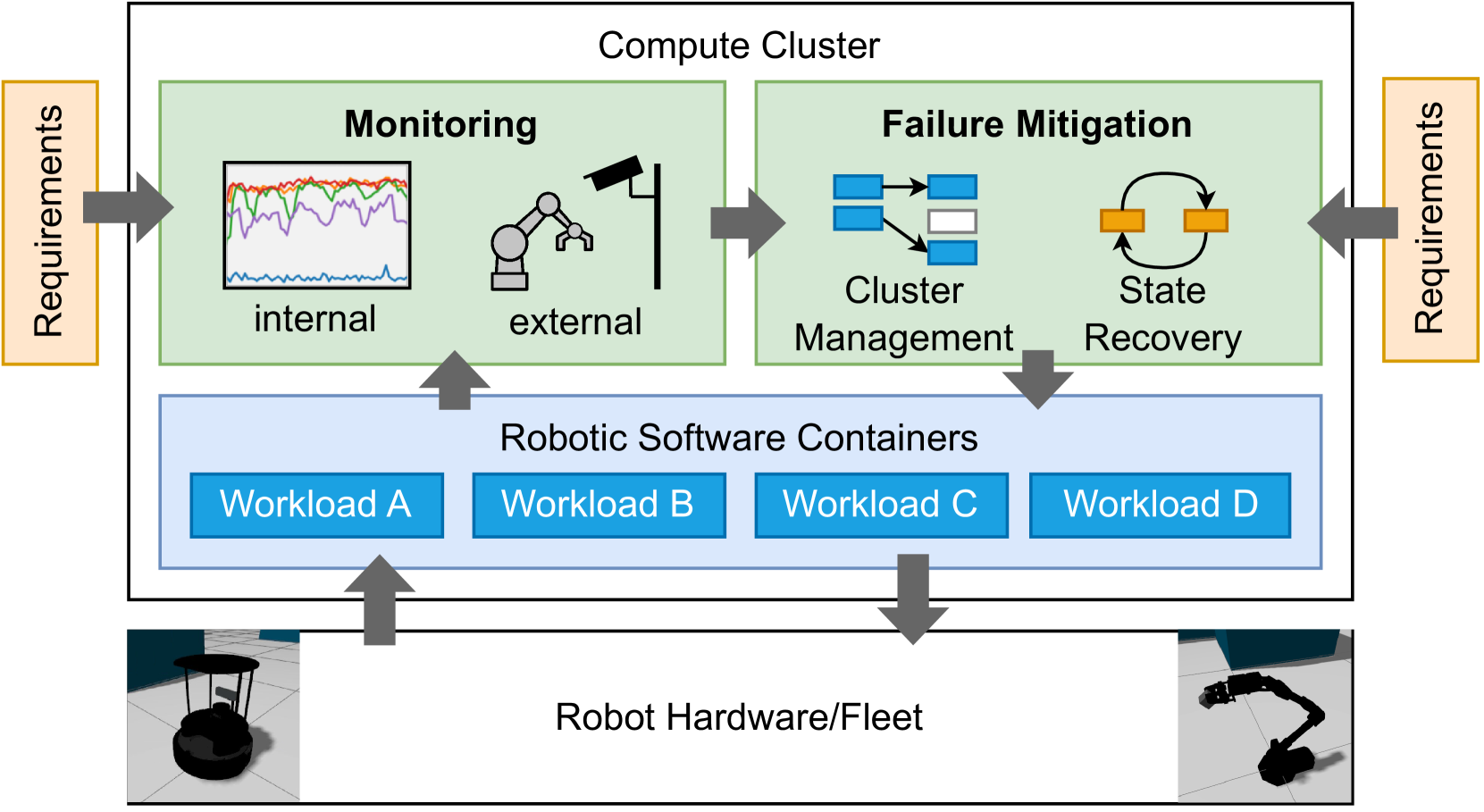
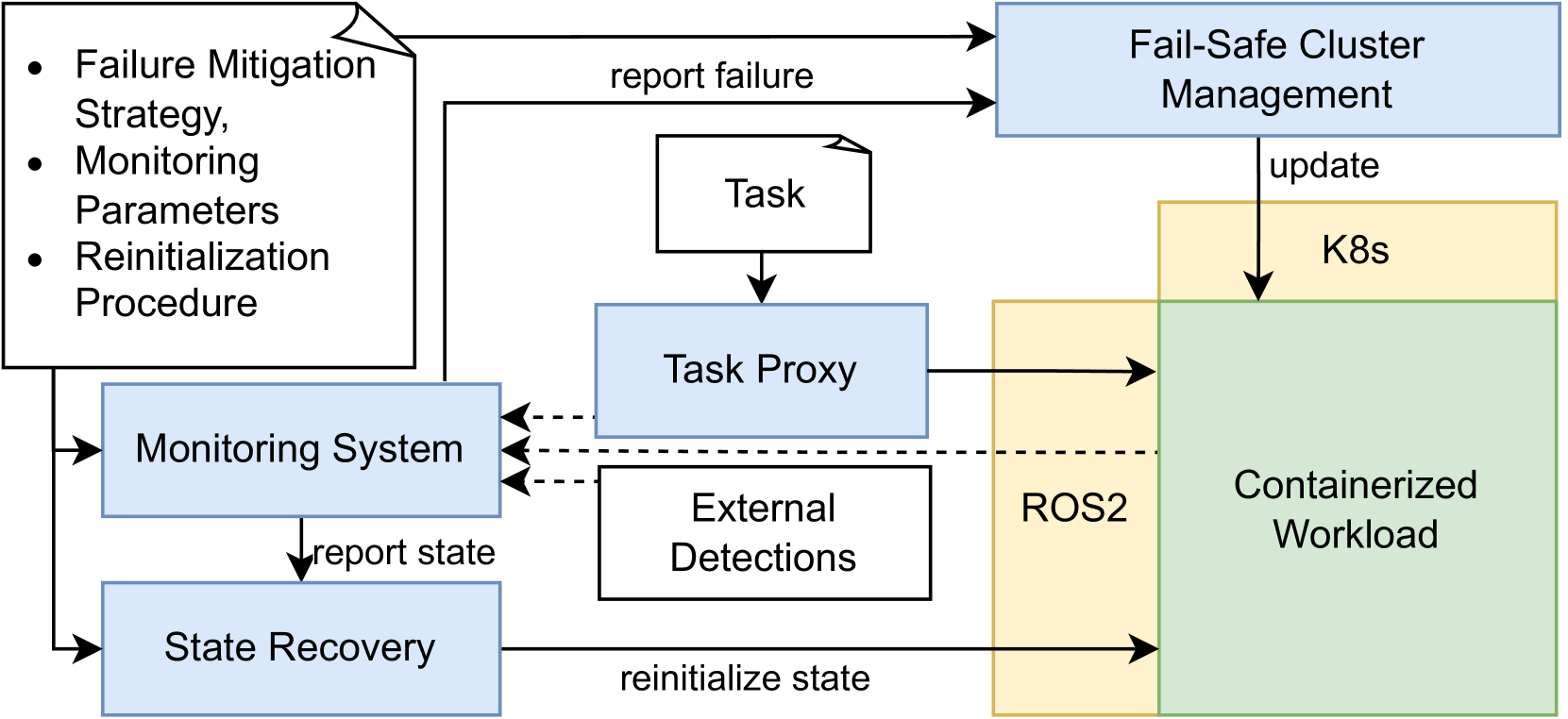
技术框架:该框架主要包含以下几个模块:1) 监控模块:负责监控机器人系统的各个组件的状态,例如CPU利用率、内存占用、网络延迟等。2) 故障检测模块:根据监控数据,判断系统是否发生故障。3) 行为树执行模块:根据故障类型,执行相应的行为树,进行故障缓解。4) 状态管理模块:负责管理机器人系统的状态,例如位置、姿态、任务进度等。
关键创新:该方法的核心创新在于将行为树应用于机器人系统的故障缓解。行为树提供了一种通用的、模块化的方式来描述复杂的故障缓解策略,使得系统可以灵活地应对各种类型的故障。此外,该方法还支持状态化的故障缓解,可以保证系统在故障发生后能够恢复到之前的状态。
关键设计:行为树的设计是该方法的关键。行为树的节点可以分为控制节点(例如Sequence、Selector)和执行节点(例如执行某个任务、发送某个指令)。控制节点负责控制行为树的执行流程,执行节点负责执行具体的任务。行为树的设计需要根据具体的机器人应用和故障场景进行调整。例如,对于AMR导航应用,可以设计一个行为树,当检测到路径规划失败时,自动重新规划路径。
🖼️ 关键图片
📊 实验亮点
该论文在模拟环境中对自主移动机器人 (AMR) 导航和机器人操作两个示例应用进行了实验验证。实验结果表明,该方法能够有效地检测和缓解各种类型的故障,例如组件崩溃、网络中断等。通过对比实验,证明了该方法在故障缓解速度和系统恢复能力方面优于传统的故障缓解方法。具体的性能数据和提升幅度在论文中有详细描述。
🎯 应用场景
该研究成果可广泛应用于各种基于Kubernetes部署的分布式机器人系统,例如自主移动机器人、工业机器人、服务机器人等。通过提高系统的容错性和可靠性,可以降低运维成本,提高生产效率,并为机器人应用提供更稳定的运行环境。未来,该方法还可以扩展到其他类型的分布式系统,例如云计算平台、物联网系统等。
📄 摘要(原文)
Offloading computationally expensive algorithms to the edge or even cloud offers an attractive option to tackle limitations regarding on-board computational and energy resources of robotic systems. In cloud-native applications deployed with the container management system Kubernetes (K8s), one key problem is ensuring resilience against various types of failures. However, complex robotic systems interacting with the physical world pose a very specific set of challenges and requirements that are not yet covered by failure mitigation approaches from the cloud-native domain. In this paper, we therefore propose a novel approach for robotic system monitoring and stateful, reactive failure mitigation for distributed robotic systems deployed using Kubernetes (K8s) and the Robot Operating System (ROS2). By employing the generic substrate of Behaviour Trees, our approach can be applied to any robotic workload and supports arbitrarily complex monitoring and failure mitigation strategies. We demonstrate the effectiveness and application-agnosticism of our approach on two example applications, namely Autonomous Mobile Robot (AMR) navigation and robotic manipulation in a simulated environment.