Data Scaling Laws in Imitation Learning for Robotic Manipulation
作者: Yingdong Hu, Fanqi Lin, Pingyue Sheng, Chuan Wen, Jiacheng You, Yang Gao
分类: cs.RO
发布日期: 2024-10-24 (更新: 2025-10-13)
💡 一句话要点
研究模仿学习中机器人操作的数据缩放规律,实现零样本泛化
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 数据缩放 零样本泛化 环境多样性 物体多样性 数据收集策略
📋 核心要点
- 现有机器人模仿学习方法在面对新环境和新物体时泛化能力不足,需要大量特定场景数据。
- 通过研究数据量、环境多样性、物体多样性对策略泛化性能的影响,探索机器人操作中的数据缩放规律。
- 实验表明,环境和物体的多样性比数据量更重要,并据此提出高效的数据收集策略,实现较好的零样本泛化。
📝 摘要(中文)
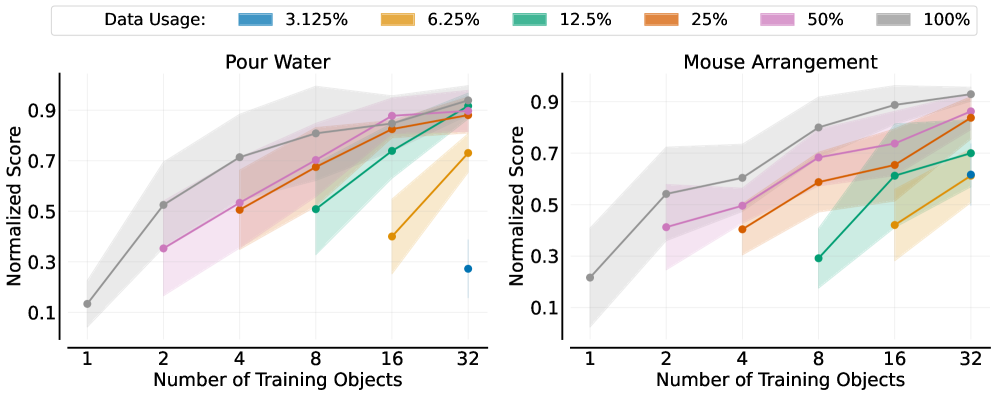
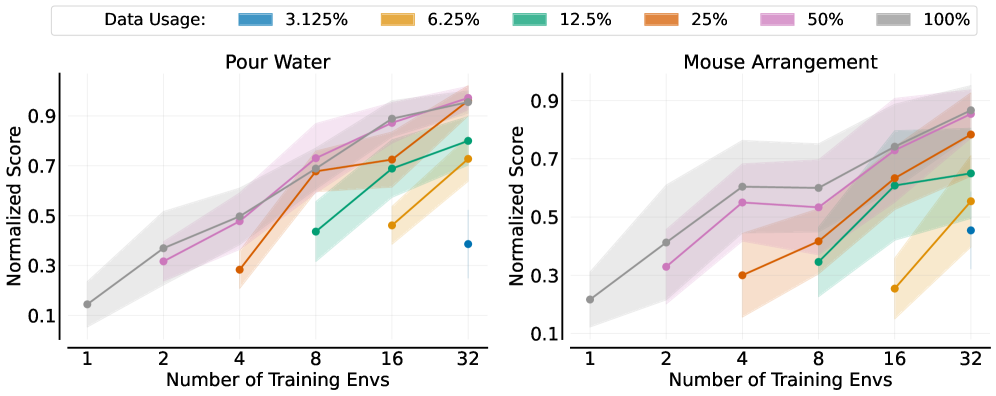
本文研究了机器人领域,特别是机器人操作中是否存在类似于自然语言处理和计算机视觉领域的数据缩放规律,以及适当的数据缩放是否能够产生单任务机器人策略,从而在任何环境中对同一类别中的任何对象进行零样本部署。为此,我们对模仿学习中的数据缩放进行了全面的实证研究。通过收集跨多个环境和对象的数据,我们研究了策略的泛化性能如何随训练环境、对象和演示的数量而变化。在整个研究过程中,我们收集了超过 40,000 个演示,并在严格的评估协议下执行了超过 15,000 次真实世界的机器人rollout。我们的发现揭示了几个有趣的结果:策略的泛化性能与环境和对象的数量大致呈幂律关系。环境和对象的多样性远比演示的绝对数量重要;一旦每个环境或对象的演示数量达到某个阈值,额外的演示效果甚微。基于这些见解,我们提出了一种高效的数据收集策略。通过四个数据收集器工作一个下午,我们收集了足够的数据,使两个任务的策略能够在具有未见对象的全新环境中达到大约 90% 的成功率。
🔬 方法详解
问题定义:论文旨在解决机器人模仿学习中策略泛化能力不足的问题,尤其是在面对未见过的环境和物体时。现有方法通常需要针对特定场景进行大量数据收集和训练,难以实现零样本泛化。痛点在于数据效率低,泛化性差。
核心思路:论文的核心思路是借鉴自然语言处理和计算机视觉领域的数据缩放规律,研究在机器人操作任务中,数据量、环境多样性和物体多样性对策略泛化性能的影响。通过分析这些因素之间的关系,找到提升泛化性能的关键因素,并据此设计高效的数据收集策略。
技术框架:论文采用模仿学习框架,通过收集大量机器人操作演示数据,训练机器人策略。整体流程包括:1) 定义机器人操作任务;2) 设计数据收集环境和物体;3) 收集机器人操作演示数据;4) 训练机器人策略;5) 在新环境和新物体上评估策略的泛化性能;6) 分析数据量、环境多样性和物体多样性对泛化性能的影响。
关键创新:论文最重要的技术创新点在于发现了机器人操作任务中数据缩放规律,即环境和物体的多样性远比数据量本身更重要。这一发现颠覆了以往认为数据量越大越好的认知,为高效数据收集和提升策略泛化性能提供了新的思路。
关键设计:论文的关键设计包括:1) 精心设计的多个环境和物体,以保证数据的多样性;2) 严格的评估协议,以保证泛化性能评估的准确性;3) 高效的数据收集策略,通过并行数据收集器在短时间内收集足够的数据;4) 策略网络结构和训练方法,具体细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,策略的泛化性能与环境和对象的数量大致呈幂律关系。通过四个数据收集器工作一个下午,收集的数据足以使两个任务的策略能够在具有未见对象的全新环境中达到大约 90% 的成功率。这表明,通过关注环境和对象的多样性,可以显著提高数据效率和策略泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过高效的数据收集和训练,可以快速部署具有良好泛化能力的机器人策略,降低开发成本,提高生产效率。未来,该研究可以进一步扩展到更复杂的机器人任务和环境,实现更智能、更灵活的机器人应用。
📄 摘要(原文)
Data scaling has revolutionized fields like natural language processing and computer vision, providing models with remarkable generalization capabilities. In this paper, we investigate whether similar data scaling laws exist in robotics, particularly in robotic manipulation, and whether appropriate data scaling can yield single-task robot policies that can be deployed zero-shot for any object within the same category in any environment. To this end, we conduct a comprehensive empirical study on data scaling in imitation learning. By collecting data across numerous environments and objects, we study how a policy's generalization performance changes with the number of training environments, objects, and demonstrations. Throughout our research, we collect over 40,000 demonstrations and execute more than 15,000 real-world robot rollouts under a rigorous evaluation protocol. Our findings reveal several intriguing results: the generalization performance of the policy follows a roughly power-law relationship with the number of environments and objects. The diversity of environments and objects is far more important than the absolute number of demonstrations; once the number of demonstrations per environment or object reaches a certain threshold, additional demonstrations have minimal effect. Based on these insights, we propose an efficient data collection strategy. With four data collectors working for one afternoon, we collect sufficient data to enable the policies for two tasks to achieve approximately 90% success rates in novel environments with unseen objects.