Multi-UAV Formation Control with Static and Dynamic Obstacle Avoidance via Reinforcement Learning
作者: Yuqing Xie, Chao Yu, Hongzhi Zang, Feng Gao, Wenhao Tang, Jingyi Huang, Jiayu Chen, Botian Xu, Yi Wu, Yu Wang
分类: cs.RO
发布日期: 2024-10-24 (更新: 2025-03-01)
💡 一句话要点
提出一种基于强化学习的多无人机编队控制方法,用于静态和动态避障。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多无人机编队控制 强化学习 避障 课程学习 注意力机制
📋 核心要点
- 现有方法在复杂环境下难以平衡多无人机编队控制中的定向飞行、避障和编队保持等多重目标。
- 提出一种两阶段强化学习方法,通过奖励函数搜索和课程学习,提升策略在复杂场景下的训练效率。
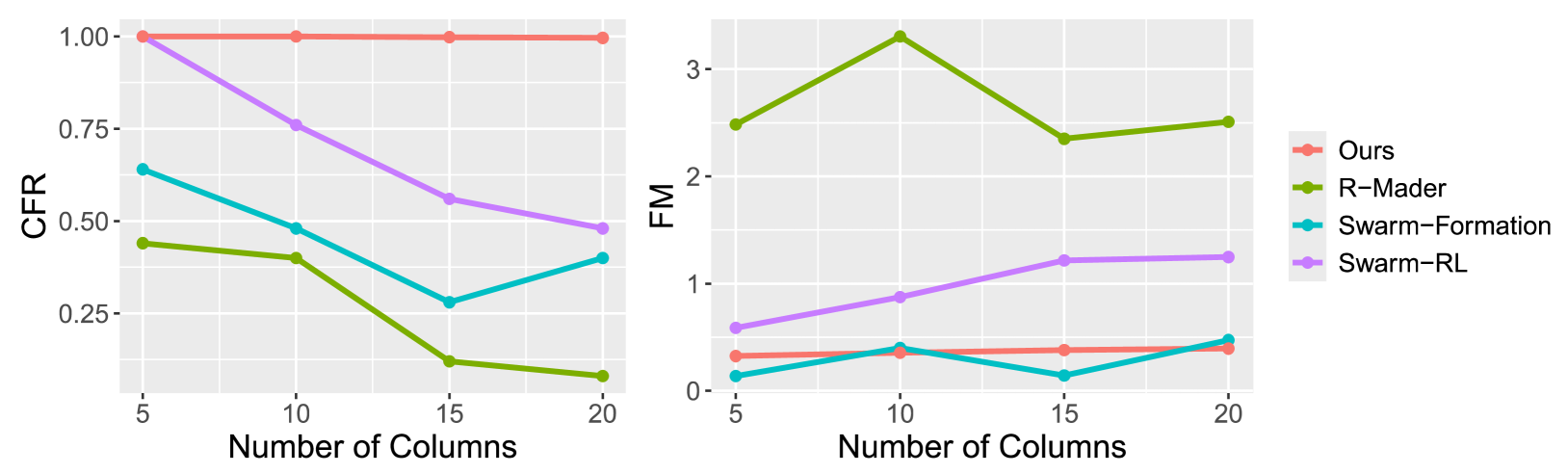
- 实验结果表明,该方法在模拟和真实环境中均优于现有方法,有效提升了无碰撞率和编队保持能力。
📝 摘要(中文)
本文致力于解决多无人机(UAV)在定向飞行中保持编队,同时避开静态和动态障碍物的难题。该任务的复杂性源于其多目标性质、巨大的探索空间以及模拟到真实的差距。为了应对这些挑战,我们提出了一种两阶段强化学习(RL)流程。第一阶段,我们随机搜索奖励函数,以平衡关键目标:定向飞行、避障、编队保持和零样本策略部署。第二阶段,将此奖励函数应用于更复杂的场景,并利用课程学习来加速策略训练。此外,我们还结合了基于注意力的观察编码器,以提高编队保持能力和对不同障碍物密度的适应性。在模拟和真实环境中的实验结果表明,我们的方法在静态、动态和混合障碍物场景中的无碰撞率和编队保持方面均优于基于规划和基于RL的基线方法。消融研究进一步证实了我们的课程学习策略和基于注意力的编码器的有效性。
🔬 方法详解
问题定义:本文旨在解决多无人机在复杂环境中,既要保持预定编队飞行,又要避开静态和动态障碍物的难题。现有方法通常难以在多目标优化、高维状态空间探索以及从仿真到真实环境的迁移等方面取得平衡,导致实际应用效果不佳。
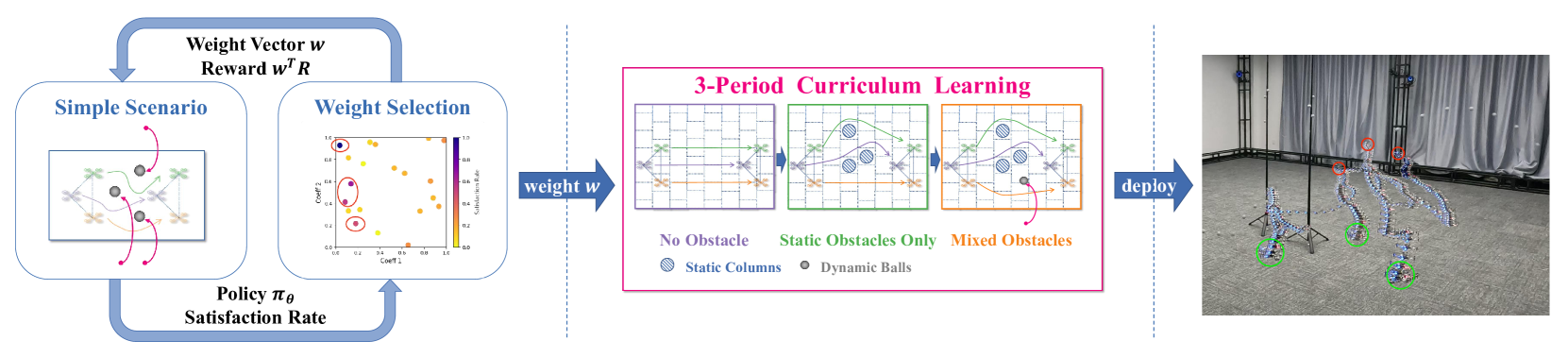
核心思路:论文的核心思路是将复杂的编队控制和避障问题分解为两个阶段的强化学习任务。第一阶段侧重于寻找一个合适的奖励函数,该函数能够有效平衡定向飞行、避障和编队保持三个目标。第二阶段则利用该奖励函数,并通过课程学习的方式,逐步增加训练难度,从而加速策略的收敛,并提高策略的泛化能力。
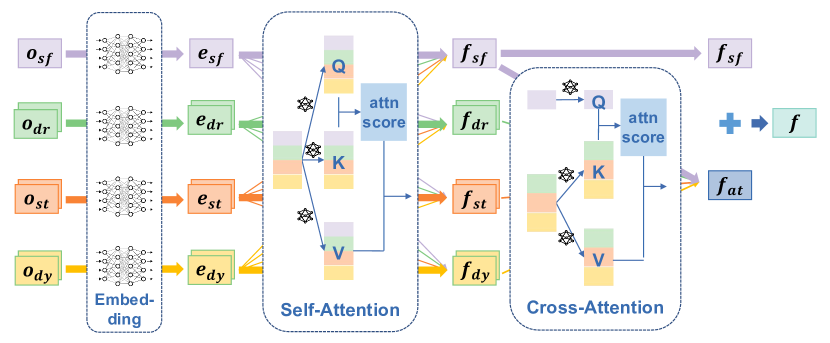
技术框架:该方法采用两阶段强化学习框架。第一阶段,使用随机搜索算法寻找最优奖励函数。第二阶段,使用第一阶段得到的奖励函数,结合课程学习策略,训练强化学习智能体。此外,还引入了基于注意力的观察编码器,用于提取环境信息,并提高对不同障碍物密度的适应性。整体流程包括环境建模、状态观测、动作选择、奖励计算和策略更新等环节。
关键创新:该方法的主要创新点在于:1) 提出了一种两阶段强化学习框架,有效解决了多目标优化问题;2) 引入了课程学习策略,加速了策略训练,并提高了策略的泛化能力;3) 采用了基于注意力的观察编码器,增强了对环境信息的理解和适应性。与现有方法相比,该方法能够更好地平衡编队保持、避障和定向飞行三个目标,并在复杂环境中表现出更强的鲁棒性。
关键设计:在奖励函数设计方面,论文考虑了定向飞行、避障和编队保持三个目标,并使用随机搜索算法寻找最优权重组合。在课程学习方面,论文逐步增加障碍物的密度和动态性,以提高策略的泛化能力。在网络结构方面,论文采用了基于注意力的观察编码器,用于提取环境信息,并提高对不同障碍物密度的适应性。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在静态、动态和混合障碍物场景中的无碰撞率和编队保持方面均优于基于规划和基于RL的基线方法。具体而言,在真实环境测试中,该方法能够显著提高无人机编队在复杂环境下的安全性和稳定性,验证了该方法的实际应用价值。
🎯 应用场景
该研究成果可应用于无人机集群协同作业,例如:无人机物流配送、无人机环境监测、无人机搜索救援等领域。通过提高无人机集群在复杂环境下的自主性和安全性,可以有效降低人力成本,提高工作效率,并拓展无人机应用场景。
📄 摘要(原文)
This paper tackles the challenging task of maintaining formation among multiple unmanned aerial vehicles (UAVs) while avoiding both static and dynamic obstacles during directed flight. The complexity of the task arises from its multi-objective nature, the large exploration space, and the sim-to-real gap. To address these challenges, we propose a two-stage reinforcement learning (RL) pipeline. In the first stage, we randomly search for a reward function that balances key objectives: directed flight, obstacle avoidance, formation maintenance, and zero-shot policy deployment. The second stage applies this reward function to more complex scenarios and utilizes curriculum learning to accelerate policy training. Additionally, we incorporate an attention-based observation encoder to improve formation maintenance and adaptability to varying obstacle densities. Experimental results in both simulation and real-world environments demonstrate that our method outperforms both planning-based and RL-based baselines in terms of collision-free rates and formation maintenance across static, dynamic, and mixed obstacle scenarios. Ablation studies further confirm the effectiveness of our curriculum learning strategy and attention-based encoder. Animated demonstrations are available at: https://sites.google.com/view/ uav-formation-with-avoidance/.