SPIRE: Synergistic Planning, Imitation, and Reinforcement Learning for Long-Horizon Manipulation
作者: Zihan Zhou, Animesh Garg, Dieter Fox, Caelan Garrett, Ajay Mandlekar
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2024-10-23
备注: Conference on Robot Learning (CoRL) 2024
💡 一句话要点
SPIRE:结合规划、模仿和强化学习,解决长时程机器人操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 长时程任务 模仿学习 强化学习 任务规划 运动规划 机器人学习
📋 核心要点
- 长时程机器人操作任务面临探索空间巨大、学习难度随任务长度增加等挑战,现有模仿学习和强化学习方法难以有效解决。
- SPIRE系统结合任务和运动规划(TAMP)、模仿学习和强化学习,将复杂任务分解为子问题,并利用各自优势提升学习效率。
- 实验结果表明,SPIRE在长时程操作任务上显著优于现有方法,任务性能提升35%-50%,数据效率提升6倍,任务完成效率提升近2倍。
📝 摘要(中文)
机器人学习已被证明是编程机械臂的一种通用且有效的方法。模仿学习能够仅从人类演示中学习,但受限于演示的能力。强化学习通过探索来发现更好的行为;然而,可能的改进空间可能太大,无法从头开始。对于这两种技术,学习难度都与操作任务的长度成正比。考虑到这一点,我们提出了SPIRE,该系统首先使用任务和运动规划(TAMP)将任务分解为更小的学习子问题,其次结合模仿和强化学习以最大限度地发挥它们的优势。我们开发了在规划系统环境中部署时训练学习代理的新策略。我们在一套长时程和接触丰富的机器人操作问题上评估了SPIRE。我们发现,SPIRE的平均任务性能优于先前集成模仿学习、强化学习和规划的方法35%到50%,在训练熟练代理所需的人类演示数量方面,数据效率提高了6倍,并且学习完成任务的效率提高了近2倍。
🔬 方法详解
问题定义:论文旨在解决长时程机器人操作任务中,模仿学习受限于演示质量,强化学习探索空间过大,导致学习效率低下的问题。现有方法难以有效处理复杂、接触丰富的操作任务,且学习难度随任务长度增加而显著提升。
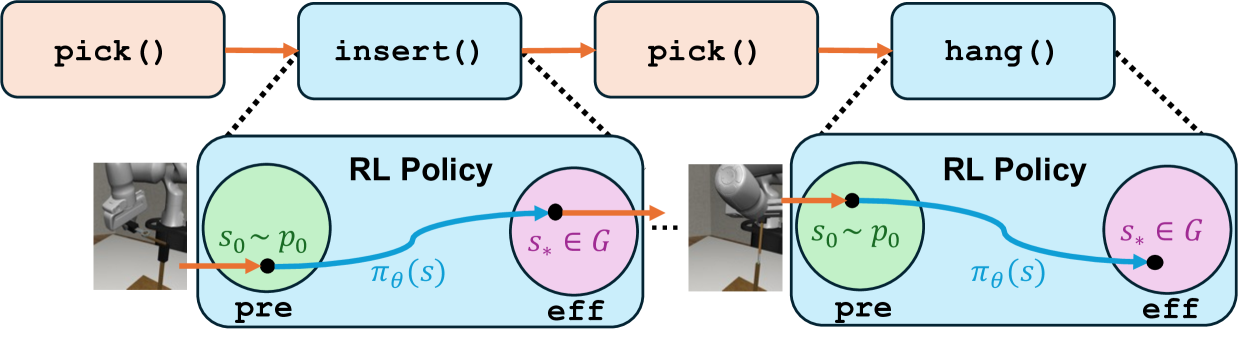
核心思路:论文的核心思路是将长时程任务分解为更小的、可管理的子任务,并结合模仿学习和强化学习的优势。通过任务和运动规划(TAMP)进行任务分解,然后利用模仿学习提供初始策略,再通过强化学习进行策略优化,从而提高学习效率和任务完成性能。
技术框架:SPIRE系统的整体框架包含三个主要模块:1) 任务和运动规划(TAMP):将长时程任务分解为一系列子任务,并生成相应的运动规划。2) 模仿学习:利用人类演示数据训练初始策略,为强化学习提供良好的起点。3) 强化学习:在模仿学习的基础上,通过探索和奖励机制优化策略,提高任务完成的鲁棒性和效率。这三个模块协同工作,实现高效的长时程操作任务学习。
关键创新:SPIRE的关键创新在于将任务分解与模仿学习和强化学习相结合,并设计了在规划系统环境中训练学习代理的新策略。这种结合充分利用了规划的全局性和学习的自适应性,有效解决了长时程任务的学习难题。与现有方法相比,SPIRE能够更有效地利用人类演示数据,并更快地学习到高质量的控制策略。
关键设计:论文中关键的设计包括:1) 使用TAMP进行任务分解的具体策略,例如如何定义子任务的边界和目标。2) 模仿学习的损失函数设计,例如行为克隆或生成对抗模仿学习。3) 强化学习的奖励函数设计,如何平衡任务完成的效率和安全性。4) 如何在规划系统和学习代理之间进行有效的信息传递和协同工作。这些细节对SPIRE的性能至关重要,但具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SPIRE在长时程机器人操作任务上显著优于现有方法,平均任务性能提升35%到50%,在训练熟练代理所需的人类演示数量方面,数据效率提高了6倍,并且学习完成任务的效率提高了近2倍。这些结果表明SPIRE在长时程操作任务学习方面具有显著优势。
🎯 应用场景
SPIRE技术可应用于各种长时程机器人操作任务,例如装配、拆卸、整理、烹饪等。该研究具有很高的实际应用价值,能够显著提高机器人在复杂环境中的自主操作能力,降低人工干预的需求,并有望推动机器人技术在制造业、服务业等领域的广泛应用。
📄 摘要(原文)
Robot learning has proven to be a general and effective technique for programming manipulators. Imitation learning is able to teach robots solely from human demonstrations but is bottlenecked by the capabilities of the demonstrations. Reinforcement learning uses exploration to discover better behaviors; however, the space of possible improvements can be too large to start from scratch. And for both techniques, the learning difficulty increases proportional to the length of the manipulation task. Accounting for this, we propose SPIRE, a system that first uses Task and Motion Planning (TAMP) to decompose tasks into smaller learning subproblems and second combines imitation and reinforcement learning to maximize their strengths. We develop novel strategies to train learning agents when deployed in the context of a planning system. We evaluate SPIRE on a suite of long-horizon and contact-rich robot manipulation problems. We find that SPIRE outperforms prior approaches that integrate imitation learning, reinforcement learning, and planning by 35% to 50% in average task performance, is 6 times more data efficient in the number of human demonstrations needed to train proficient agents, and learns to complete tasks nearly twice as efficiently. View https://sites.google.com/view/spire-corl-2024 for more details.