Foundation Models for Rapid Autonomy Validation
作者: Alec Farid, Peter Schleede, Aaron Huang, Christoffer Heckman
分类: cs.RO, cs.LG
发布日期: 2024-10-22 (更新: 2025-05-29)
💡 一句话要点
提出基于行为Foundation Model的自动驾驶验证方法,加速碰撞风险评估。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶验证 Foundation Model 掩码自编码器 场景难度评估 碰撞风险评估
📋 核心要点
- 自动驾驶验证需要大量真实场景测试,成本高昂且难以覆盖所有Corner Case。
- 利用行为Foundation Model学习驾驶场景表征,并根据碰撞风险评估场景难度。
- 通过优先测试高难度场景,加速碰撞风险评估,同时保证场景覆盖率。
📝 摘要(中文)
本文致力于解决自动驾驶车辆性能验证问题。自动驾驶车辆需要在各种驾驶场景(包括罕见事件)中进行测试,以充分验证其安全性并避免极端情况下的异常行为。自动驾驶公司依赖于在真实模拟环境中进行数百万英里的测试,以评估碰撞的频率和严重程度。为了提高可扩展性和覆盖范围,我们提出了一种行为Foundation Model,具体来说是使用掩码自编码器(MAE)来重建驾驶场景。我们以两种互补的方式利用该Foundation Model:(i) 使用学习到的嵌入空间将定性相似的场景分组;(ii) 微调模型,根据模拟中发生碰撞的可能性来标记场景的难度。我们将难度评分用作场景组的重要性权重。结果表明,该方法可以通过优先考虑高难度场景,同时确保覆盖每种驾驶场景,从而更快速地估计碰撞的频率和严重程度。
🔬 方法详解
问题定义:自动驾驶车辆的性能验证需要大量的测试,以确保其在各种驾驶场景下的安全性。现有的方法依赖于在真实模拟环境中进行数百万英里的测试,这既耗时又昂贵,并且难以覆盖所有可能出现的极端情况(Corner Case)。因此,如何更有效地进行自动驾驶车辆的性能验证是一个关键问题。
核心思路:本文的核心思路是利用行为Foundation Model学习驾驶场景的表征,并根据碰撞风险评估场景的难度。通过优先测试高难度场景,可以更快速地估计碰撞的频率和严重程度,同时确保覆盖各种驾驶场景。这种方法旨在提高验证效率,降低测试成本,并增强自动驾驶系统的安全性。
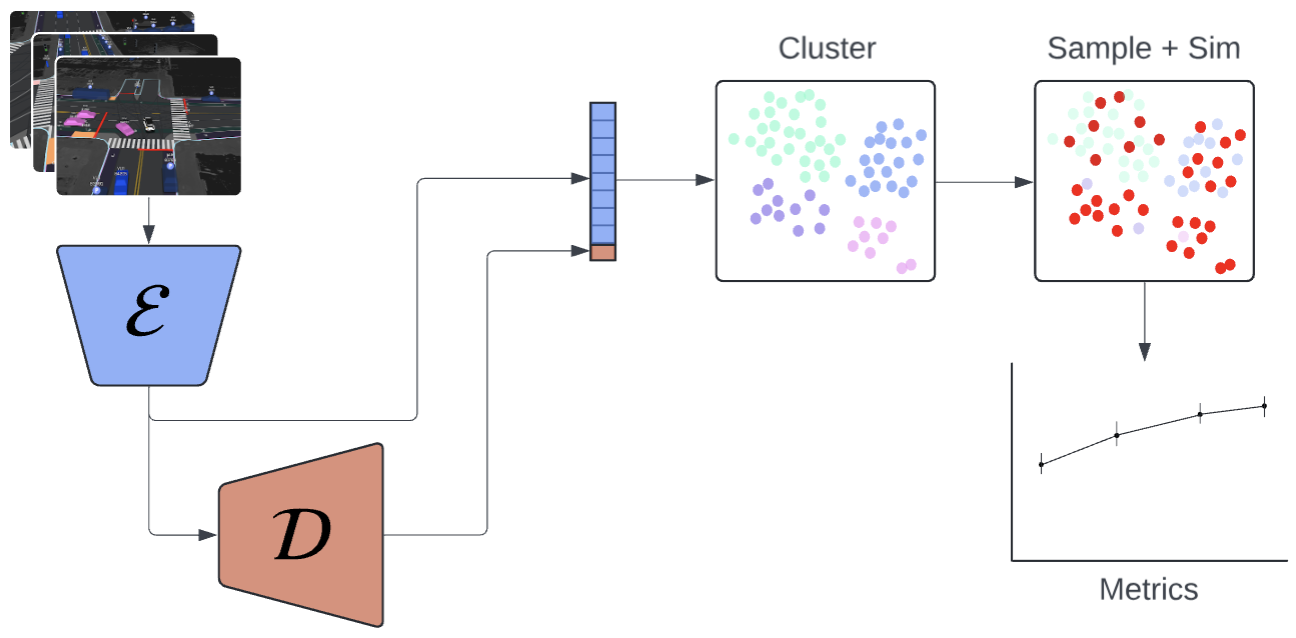
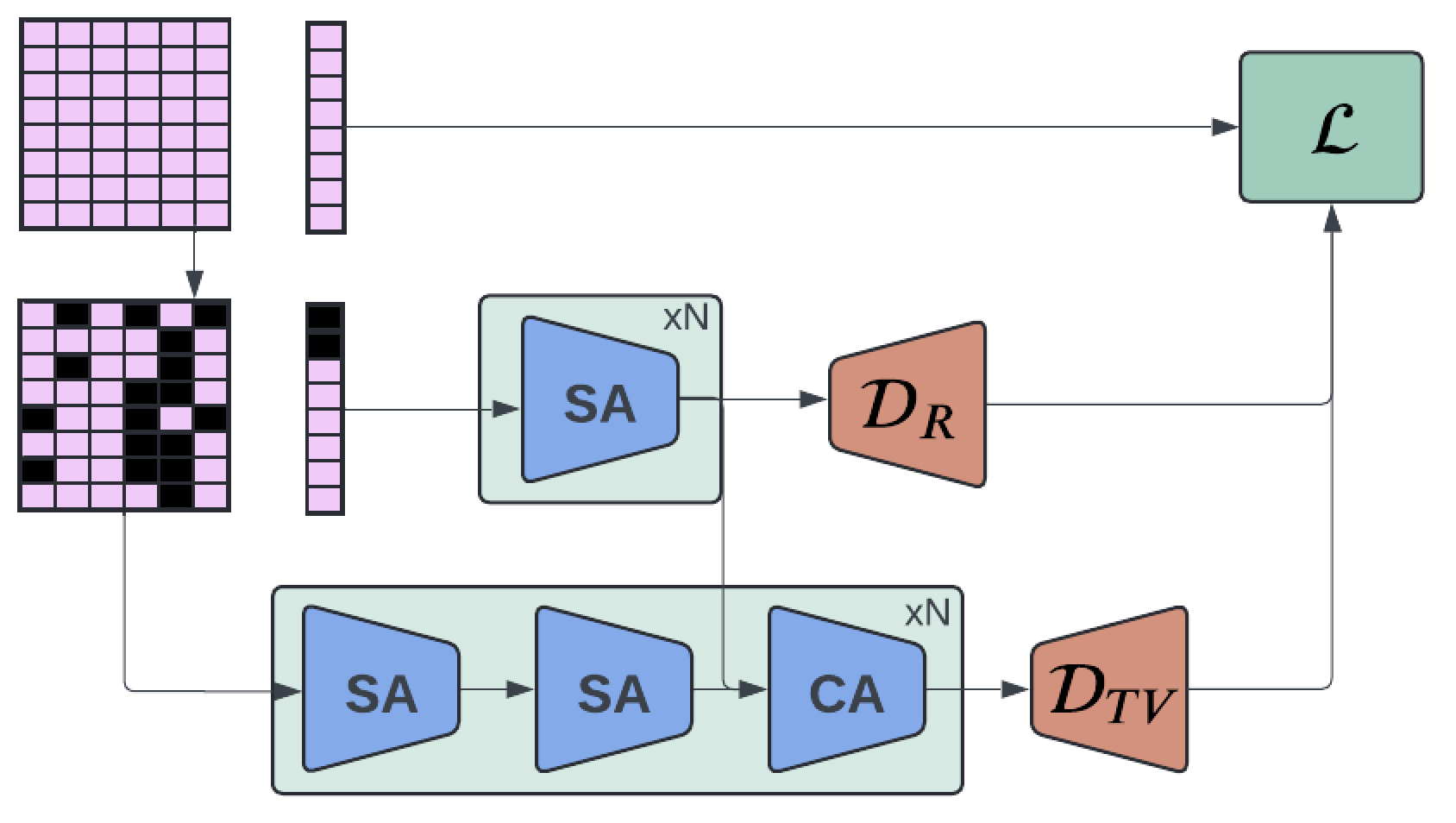
技术框架:该方法的技术框架主要包括以下几个阶段:1) 使用掩码自编码器(MAE)训练行为Foundation Model,使其能够重建驾驶场景。2) 利用学习到的嵌入空间将定性相似的场景分组。3) 微调Foundation Model,根据模拟中发生碰撞的可能性来标记场景的难度。4) 将难度评分用作场景组的重要性权重,优先测试高难度场景。
关键创新:该方法最重要的技术创新点在于利用行为Foundation Model进行驾驶场景的表征学习和难度评估。与传统的基于规则或人工设计的场景选择方法相比,该方法能够自动地学习场景的特征,并根据碰撞风险进行难度评估,从而更有效地选择测试场景。
关键设计:关键设计包括:1) 使用MAE作为行为Foundation Model,MAE在自监督学习方面表现出色,能够有效地学习驾驶场景的表征。2) 使用碰撞可能性作为场景难度的指标,这能够直接反映场景的风险程度。3) 将难度评分用作场景组的重要性权重,这能够确保优先测试高难度场景,同时保证场景覆盖率。
🖼️ 关键图片

📊 实验亮点
论文提出了一种基于行为Foundation Model的自动驾驶验证方法,通过优先测试高难度场景,加速碰撞风险评估。实验结果(具体数值未知)表明,该方法能够在保证场景覆盖率的前提下,更快速地估计碰撞的频率和严重程度,从而提高验证效率。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的性能验证、场景生成和风险评估等领域。通过加速碰撞风险评估,可以缩短自动驾驶系统的开发周期,降低测试成本,并提高系统的安全性。此外,该方法还可以用于生成更具挑战性的测试场景,以进一步提高自动驾驶系统的鲁棒性。
📄 摘要(原文)
We are motivated by the problem of autonomous vehicle performance validation. A key challenge is that an autonomous vehicle requires testing in every kind of driving scenario it could encounter, including rare events, to provide a strong case for safety and show there is no edge-case pathological behavior. Autonomous vehicle companies rely on potentially millions of miles driven in realistic simulation to expose the driving stack to enough miles to estimate rates and severity of collisions. To address scalability and coverage, we propose the use of a behavior foundation model, specifically a masked autoencoder (MAE), trained to reconstruct driving scenarios. We leverage the foundation model in two complementary ways: we (i) use the learned embedding space to group qualitatively similar scenarios together and (ii) fine-tune the model to label scenario difficulty based on the likelihood of a collision upon simulation. We use the difficulty scoring as importance weighting for the groups of scenarios. The result is an approach which can more rapidly estimate the rates and severity of collisions by prioritizing hard scenarios while ensuring exposure to every kind of driving scenario.