Learning Quadrotor Control From Visual Features Using Differentiable Simulation
作者: Johannes Heeg, Yunlong Song, Davide Scaramuzza
分类: cs.RO
发布日期: 2024-10-21 (更新: 2026-01-15)
备注: Accepted for presentation at the IEEE International Conference on Robotics and Automation (ICRA) 2025
DOI: 10.1109/ICRA55743.2025.11128641
💡 一句话要点
利用可微仿真,从视觉特征中学习四旋翼飞行器控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 可微仿真 强化学习 四旋翼控制 视觉控制 状态表示学习
📋 核心要点
- 强化学习在机器人控制中面临样本效率低的挑战,尤其是在视觉控制任务中,难以获得可靠的状态估计。
- 该论文提出利用可微仿真,通过动力学模型反向传播梯度,实现低方差策略梯度,从而提高样本效率。
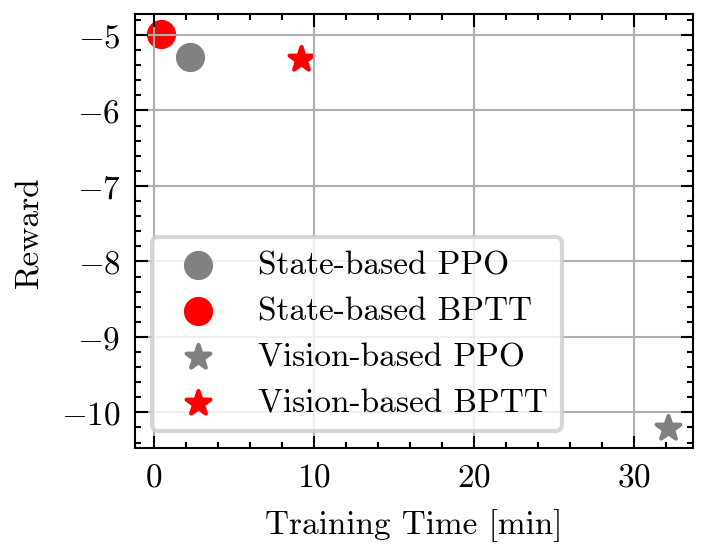
- 实验表明,在可微仿真中训练的策略,在样本效率和训练时间上均优于无模型强化学习,视觉控制任务也能在几分钟内完成。
📝 摘要(中文)
强化学习(RL)的样本效率低下仍然是机器人领域的一个重大挑战。强化学习需要大规模的仿真,并且仍然会导致较长的训练时间,从而减缓研究和创新。这个问题在无法获得可靠状态估计的基于视觉的控制任务中尤其突出。可微仿真提供了一种替代方案,它可以通过动力学模型反向传播梯度,从而提供低方差的解析策略梯度,并因此提高样本效率。然而,它在现实世界机器人任务中的应用仍然有限。这项工作展示了可微仿真在学习四旋翼飞行器控制方面的巨大潜力。我们表明,在可微仿真中进行训练在样本效率和训练时间方面都明显优于无模型强化学习,从而允许策略在提供车辆状态时在几秒钟内学会恢复四旋翼飞行器,而在仅依赖视觉特征时在几分钟内学会恢复四旋翼飞行器。我们成功的关键在于两点。首先,使用简单的替代模型进行梯度计算可以大大加快训练速度,而不会牺牲控制性能。其次,将状态表示学习与策略学习相结合,可以提高仅可观察到视觉特征的任务中的收敛速度。这些发现突出了可微仿真在现实世界机器人技术中的潜力,并为传统的强化学习方法提供了一种引人注目的替代方案。
🔬 方法详解
问题定义:该论文旨在解决四旋翼飞行器基于视觉的控制问题,特别是强化学习训练样本效率低下的问题。传统的强化学习方法需要大量的训练数据,并且在实际机器人系统中部署时,由于环境的复杂性和状态估计的不准确性,性能往往会下降。
核心思路:论文的核心思路是利用可微仿真来训练控制策略。通过可微仿真,可以计算策略关于动力学模型的梯度,从而实现更高效的策略学习。此外,论文还结合了状态表示学习,以提高在仅有视觉特征作为输入时的训练收敛速度。
技术框架:整体框架包括三个主要模块:可微仿真环境、状态表示学习模块和策略学习模块。首先,使用可微仿真环境模拟四旋翼飞行器的动力学行为。然后,状态表示学习模块从视觉特征中提取有用的状态信息。最后,策略学习模块利用可微仿真提供的梯度信息,优化控制策略。整个过程通过反向传播算法进行端到端训练。
关键创新:该论文的关键创新在于将可微仿真应用于四旋翼飞行器的视觉控制任务,并结合状态表示学习来提高训练效率。与传统的强化学习方法相比,可微仿真能够提供更准确的梯度信息,从而加速策略学习过程。此外,使用简单的替代模型进行梯度计算,进一步提高了训练速度。
关键设计:论文使用了一个简单的替代模型来加速梯度计算,具体模型结构未知。损失函数包括控制目标相关的损失项,以及用于状态表示学习的损失项。网络结构细节未知,但强调了状态表示学习模块的重要性,该模块负责从视觉特征中提取有用的状态信息,例如位置、速度等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在可微仿真中训练的策略,在样本效率和训练时间上均优于无模型强化学习。在提供车辆状态时,策略可以在几秒钟内学会恢复四旋翼飞行器;在仅依赖视觉特征时,策略可以在几分钟内学会恢复四旋翼飞行器。这些结果突出了可微仿真在机器人控制中的潜力。
🎯 应用场景
该研究成果可应用于无人机自主导航、智能巡检、物流配送等领域。通过可微仿真训练得到的控制策略,可以提高无人机在复杂环境中的适应性和鲁棒性,降低对传感器精度的要求,并减少实际部署中的调试时间。未来,该方法有望推广到其他机器人控制任务中,加速机器人技术的应用。
📄 摘要(原文)
The sample inefficiency of reinforcement learning (RL) remains a significant challenge in robotics. RL requires large-scale simulation and can still cause long training times, slowing research and innovation. This issue is particularly pronounced in vision-based control tasks where reliable state estimates are not accessible. Differentiable simulation offers an alternative by enabling gradient back-propagation through the dynamics model, providing low-variance analytical policy gradients and, hence, higher sample efficiency. However, its usage for real-world robotic tasks has yet been limited. This work demonstrates the great potential of differentiable simulation for learning quadrotor control. We show that training in differentiable simulation significantly outperforms model-free RL in terms of both sample efficiency and training time, allowing a policy to learn to recover a quadrotor in seconds when providing vehicle states and in minutes when relying solely on visual features. The key to our success is two-fold. First, the use of a simple surrogate model for gradient computation greatly accelerates training without sacrificing control performance. Second, combining state representation learning with policy learning enhances convergence speed in tasks where only visual features are observable. These findings highlight the potential of differentiable simulation for real-world robotics and offer a compelling alternative to conventional RL approaches.