Diffusion Transformer Policy
作者: Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, Yuntao Chen
分类: cs.RO, cs.CV
发布日期: 2024-10-21 (更新: 2025-03-23)
备注: preprint; New Project Page: https://robodita.github.io; revert unsuitable replacement
💡 一句话要点
提出Diffusion Transformer Policy,利用扩散Transformer模型提升机器人泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 扩散模型 Transformer 连续动作空间 泛化能力
📋 核心要点
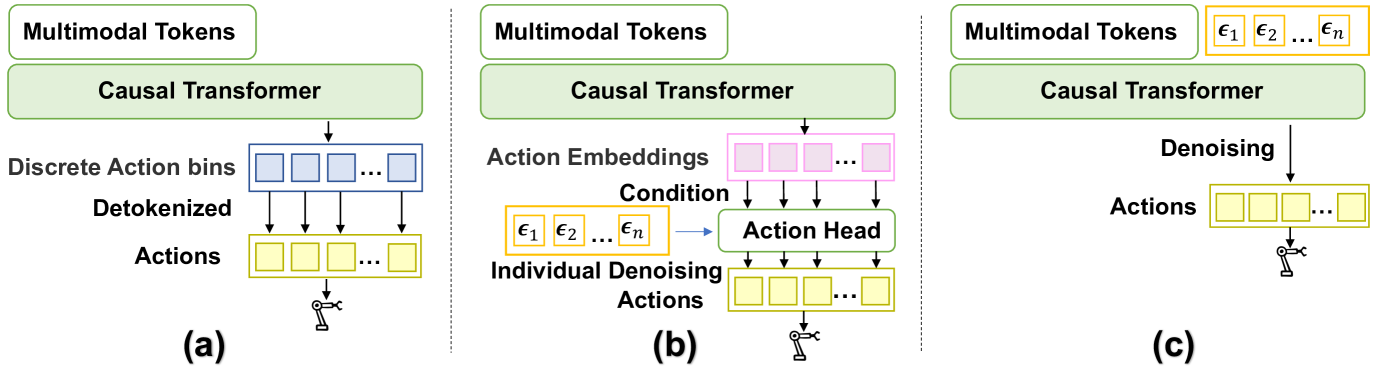
- 现有视觉-语言-动作模型通常使用小动作头预测动作,限制了处理多样化动作空间的能力。
- Diffusion Transformer Policy使用大型多模态扩散Transformer直接对动作块进行去噪,建模连续动作序列。
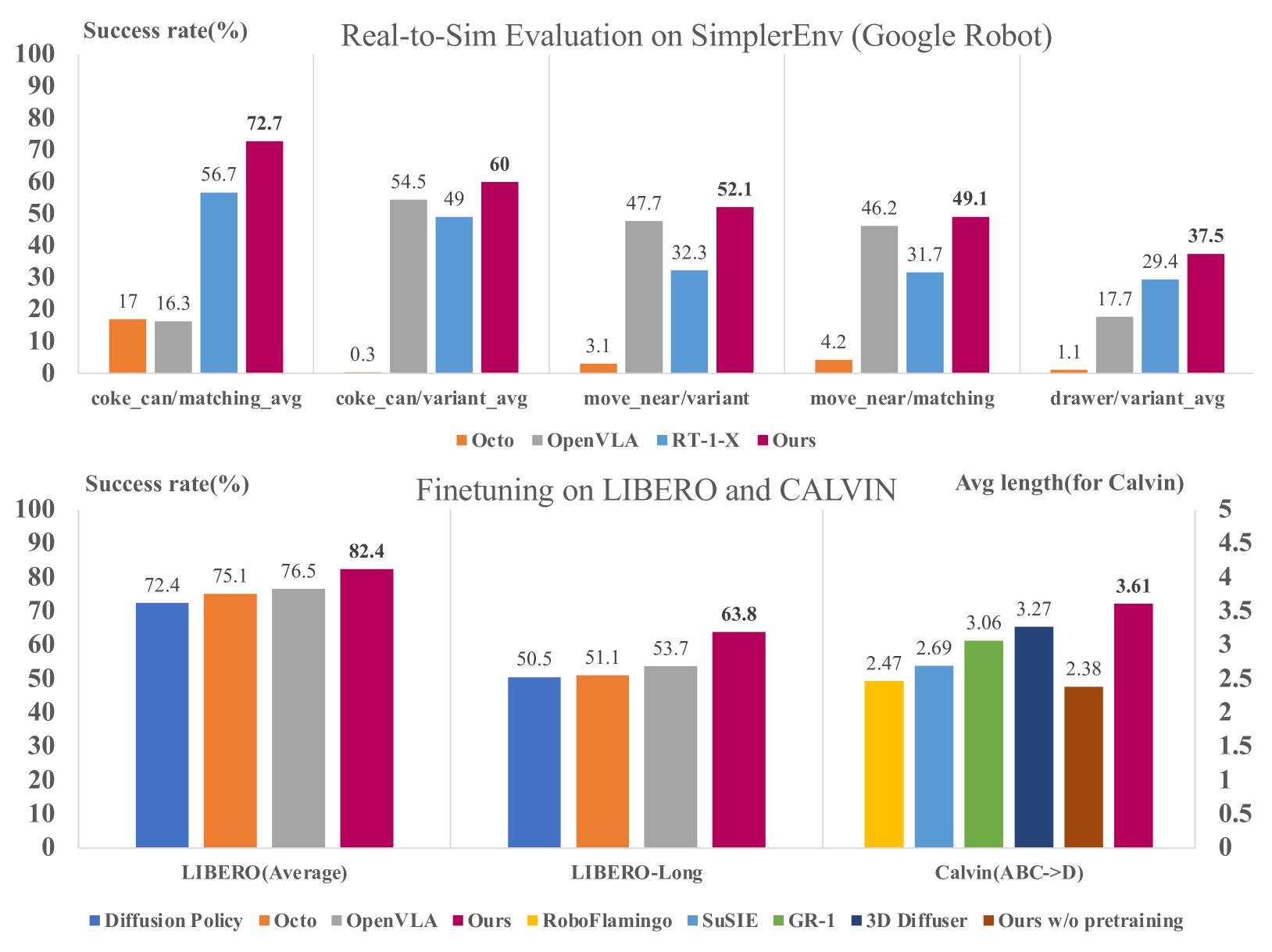
- 实验表明,该方法在多个机器人数据集和真实环境中表现出更好的泛化性能,并在Calvin任务中取得SOTA。
📝 摘要(中文)
本文提出了一种名为Diffusion Transformer Policy的多模态扩散Transformer模型,用于解决机器人控制中动作空间多样性问题。与现有方法中小动作头预测离散或连续动作不同,该方法直接使用大型Transformer模型对连续动作序列进行去噪,从而更好地建模连续末端执行器动作。通过利用Transformer的扩展能力,该方法能够有效地处理大型多样化的机器人数据集,并实现更好的泛化性能。在Maniskill2、Libero、Calvin和SimplerEnv以及真实Franka机械臂上的大量实验表明,Diffusion Transformer Policy具有有效性和泛化性。在Real-to-Sim基准SimplerEnv、真实Franka机械臂和Libero上,该方法相较于OpenVLA和Octo取得了持续更好的性能。特别是在Calvin任务ABC->D中,仅使用单个第三方视角相机流,无需任何技巧,该方法实现了最先进的性能,将连续完成的任务平均数量从5提高到3.6,并且预训练阶段显著提高了Calvin上的成功序列长度超过1.2。
🔬 方法详解
问题定义:现有的大型视觉-语言-动作模型在机器人控制领域取得了进展,但它们通常依赖于小型动作头来预测离散或连续的动作。这种方式限制了模型处理复杂和多样化动作空间的能力,尤其是在需要精确控制连续末端执行器动作的任务中。现有方法难以充分利用大规模数据集中的信息,导致泛化性能受限。
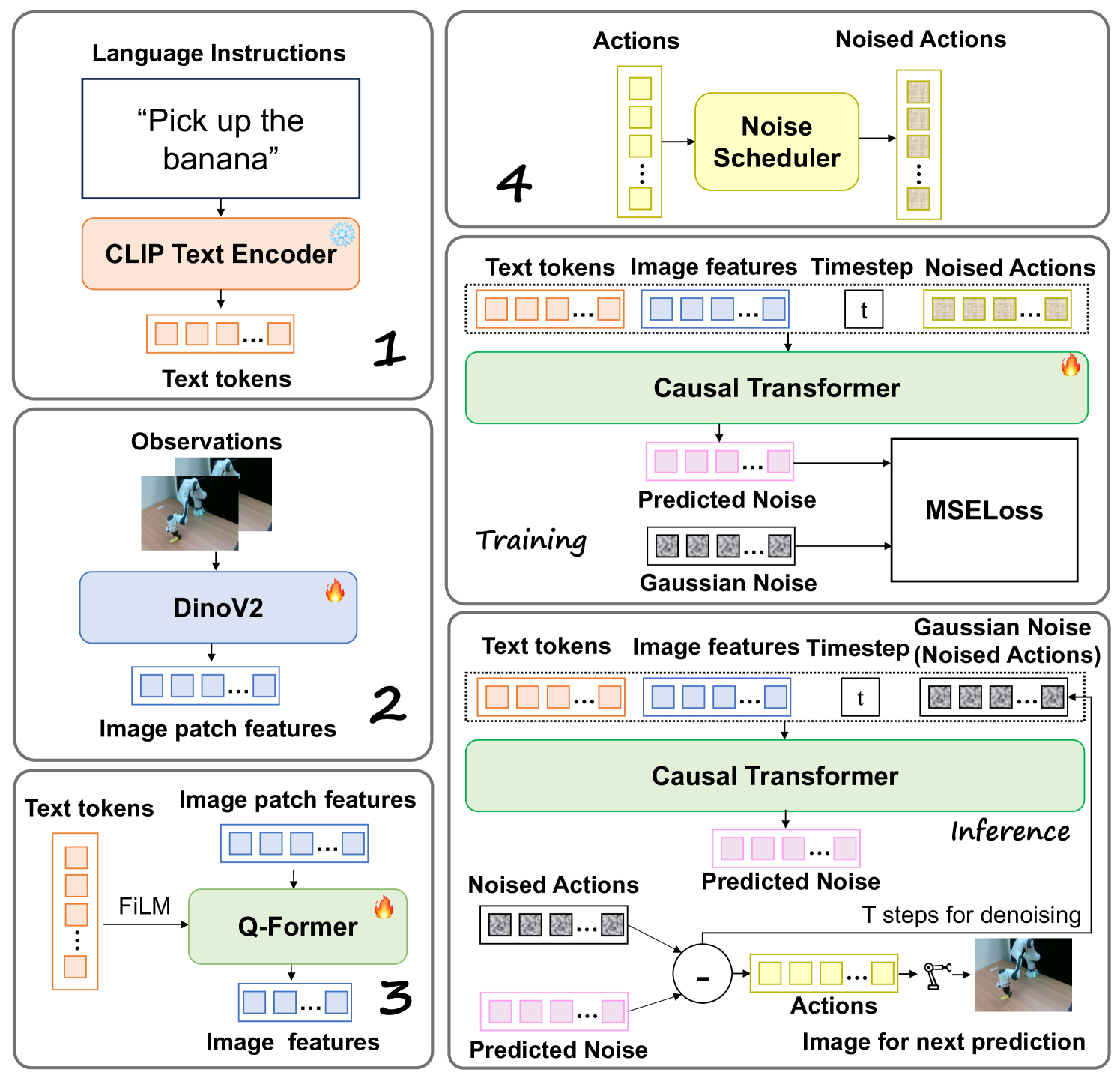
核心思路:本文的核心思路是利用扩散模型和Transformer的强大建模能力,直接对连续动作序列进行建模和去噪。通过将动作序列视为一种数据分布,并使用扩散过程逐步添加噪声,然后使用Transformer模型学习如何逆转这个过程,从而生成高质量的动作序列。这种方法能够更好地捕捉动作之间的依赖关系,并有效地处理高维连续动作空间。
技术框架:Diffusion Transformer Policy的整体框架包括以下几个主要模块:1) 编码器:将视觉输入(例如相机图像)编码成特征向量。2) 扩散过程:对连续动作序列逐步添加高斯噪声,将其转化为噪声序列。3) Transformer解码器:以编码后的视觉特征和噪声动作序列作为输入,预测去噪后的动作序列。4) 损失函数:使用均方误差(MSE)等损失函数来训练Transformer解码器,使其能够准确地预测原始动作序列。
关键创新:该方法最重要的技术创新点在于使用大型Transformer模型直接对动作序列进行去噪,而不是使用小型动作头预测动作。这种方法能够更好地利用Transformer的扩展能力,从而更好地建模连续动作空间中的复杂关系。此外,将扩散模型与Transformer结合,使得模型能够生成更加多样化和高质量的动作序列。
关键设计:在具体实现上,论文可能采用了以下关键设计:1) 使用多层Transformer解码器来增强模型的建模能力。2) 采用注意力机制来捕捉动作序列中的长程依赖关系。3) 使用合适的噪声调度策略来控制扩散过程的强度。4) 损失函数的设计可能包括对动作序列的平滑性约束,以生成更加自然的动作。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Diffusion Transformer Policy在多个机器人数据集和真实环境中取得了显著的性能提升。例如,在Calvin任务ABC->D中,仅使用单个第三方视角相机流,该方法就实现了最先进的性能,将连续完成的任务平均数量从5提高到3.6。此外,预训练阶段显著提高了Calvin上的成功序列长度超过1.2。在Real-to-Sim基准SimplerEnv、真实Franka机械臂和Libero上,该方法也相较于OpenVLA和Octo取得了持续更好的性能。
🎯 应用场景
该研究成果可应用于各种机器人控制任务,例如物体操作、导航和装配等。通过提高机器人的泛化能力,使其能够更好地适应新的环境和任务,从而降低机器人部署和维护的成本。此外,该方法还可以应用于虚拟现实和游戏等领域,生成更加逼真的角色动画。
📄 摘要(原文)
Recent large vision-language-action models pretrained on diverse robot datasets have demonstrated the potential for generalizing to new environments with a few in-domain data. However, those approaches usually predict individual discretized or continuous action by a small action head, which limits the ability in handling diverse action spaces. In contrast, we model the continuous action sequence with a large multi-modal diffusion transformer, dubbed as Diffusion Transformer Policy, in which we directly denoise action chunks by a large transformer model rather than a small action head for action embedding. By leveraging the scaling capability of transformers, the proposed approach can effectively model continuous end-effector actions across large diverse robot datasets, and achieve better generalization performance. Extensive experiments demonstrate the effectiveness and generalization of Diffusion Transformer Policy on Maniskill2, Libero, Calvin and SimplerEnv, as well as the real-world Franka arm, achieving consistent better performance on Real-to-Sim benchmark SimplerEnv, real-world Franka Arm and Libero compared to OpenVLA and Octo. Specifically, without bells and whistles, the proposed approach achieves state-of-the-art performance with only a single third-view camera stream in the Calvin task ABC->D, improving the average number of tasks completed in a row of 5 to 3.6, and the pretraining stage significantly facilitates the success sequence length on the Calvin by over 1.2.