Coherence-Driven Multimodal Safety Dialogue with Active Learning for Embodied Agents
作者: Sabit Hassan, Hye-Young Chung, Xiang Zhi Tan, Malihe Alikhani
分类: cs.RO, cs.CL
发布日期: 2024-10-18 (更新: 2025-02-25)
备注: To appear at AAMAS, 2025
💡 一句话要点
提出M-CoDAL,利用连贯性驱动的多模态对话系统提升具身智能体在安全场景下的交互能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能体 多模态对话 安全场景 话语连贯性 主动学习 人机交互 机器人安全
📋 核心要点
- 现有具身智能体在安全场景中,难以准确理解视觉信息并有效沟通,尤其是在复杂或细微的安全违规情况下。
- M-CoDAL利用话语连贯性关系增强上下文理解,并采用基于聚类的主动学习方法,高效选择信息量大的样本进行训练。
- 实验表明,M-CoDAL在安全场景理解、用户情感和对话安全性方面均有提升,并在真实机器人平台上验证了其有效性。
📝 摘要(中文)
本文提出了一种名为M-CoDAL的多模态对话系统,专为具身智能体设计,旨在提升其在安全关键场景中的理解和沟通能力,例如识别地面上的尖锐物体。该系统利用话语连贯性关系来增强上下文理解和沟通能力。为了训练该系统,引入了一种新颖的基于聚类的主动学习机制,该机制利用外部大型语言模型(LLM)来识别信息丰富的实例。使用一个新创建的多模态数据集(包含从2K Reddit图像中提取的1K安全违规)评估了该方法。这些违规行为使用大型多模态模型(LMM)进行标注,并由人工标注员验证。结果表明,该方法提高了安全态势的解决能力、用户情感以及对话的安全性。最后,将对话系统部署在Hello Robot Stretch机器人上,并与真实用户进行了一项受试者内用户研究。研究结果证实并扩展了自动化评估的结果,表明所提出的系统在真实具身智能体环境中更具说服力。
🔬 方法详解
问题定义:论文旨在解决具身智能体在安全关键场景中,如何更准确地理解视觉信息并进行有效沟通的问题。现有方法在处理复杂或细微的安全违规情况时,往往缺乏足够的上下文理解能力,导致无法及时有效地进行干预。此外,训练数据不足也是一个挑战,尤其是在安全领域,获取大量标注数据成本高昂。
核心思路:论文的核心思路是利用话语连贯性关系来增强具身智能体的上下文理解能力,并采用主动学习方法来高效地选择信息量大的样本进行训练。通过话语连贯性,系统可以更好地理解对话的上下文,从而更准确地判断安全风险并做出适当的反应。主动学习则可以减少人工标注的工作量,提高训练效率。
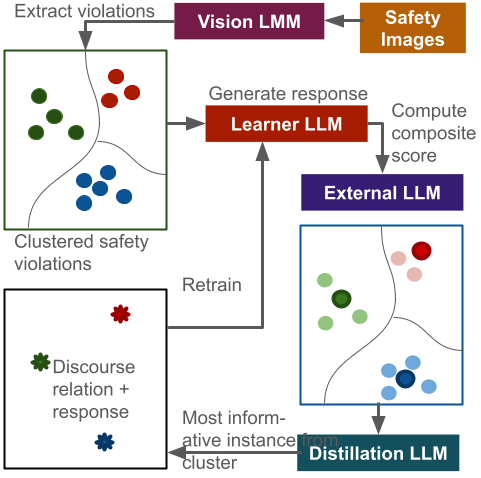
技术框架:M-CoDAL系统的整体架构包含以下几个主要模块:1) 多模态输入模块:接收视觉和语言输入;2) 话语连贯性建模模块:利用话语连贯性关系来增强上下文理解;3) 对话管理模块:负责对话的生成和管理;4) 主动学习模块:基于聚类算法和大型语言模型(LLM)选择信息量大的样本。整个流程是,首先通过多模态输入模块获取视觉和语言信息,然后通过话语连贯性建模模块增强上下文理解,接着由对话管理模块生成合适的回复,最后通过主动学习模块选择新的样本进行训练,不断优化系统性能。
关键创新:论文的关键创新点在于:1) 将话语连贯性关系引入到具身智能体的对话系统中,从而增强了上下文理解能力;2) 提出了一种基于聚类的主动学习机制,该机制利用外部大型语言模型(LLM)来识别信息丰富的实例,提高了训练效率。与现有方法相比,M-CoDAL能够更准确地理解安全风险,并生成更具针对性和说服力的回复。
关键设计:在话语连贯性建模方面,论文采用了基于规则和机器学习相结合的方法,定义了一系列话语连贯性关系,并使用机器学习模型来识别这些关系。在主动学习方面,论文首先使用聚类算法将未标注的数据分成不同的簇,然后利用大型语言模型(LLM)对每个簇进行评估,选择信息量最大的簇进行标注。具体的参数设置和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,M-CoDAL在安全态势的解决能力、用户情感以及对话的安全性方面均有显著提升。用户研究表明,M-CoDAL比基于OpenAI ChatGPT的基线系统更具说服力。具体性能数据和提升幅度在摘要中未详细给出,属于未知信息。
🎯 应用场景
该研究成果可应用于家庭服务机器人、工业安全巡检机器人、医疗辅助机器人等领域。通过提升机器人对安全风险的识别和沟通能力,可以有效减少事故发生,提高工作效率,并改善人机交互体验。未来,该技术有望进一步扩展到更复杂的安全场景,例如自动驾驶、智能监控等。
📄 摘要(原文)
When assisting people in daily tasks, robots need to accurately interpret visual cues and respond effectively in diverse safety-critical situations, such as sharp objects on the floor. In this context, we present M-CoDAL, a multimodal-dialogue system specifically designed for embodied agents to better understand and communicate in safety-critical situations. The system leverages discourse coherence relations to enhance its contextual understanding and communication abilities. To train this system, we introduce a novel clustering-based active learning mechanism that utilizes an external Large Language Model (LLM) to identify informative instances. Our approach is evaluated using a newly created multimodal dataset comprising 1K safety violations extracted from 2K Reddit images. These violations are annotated using a Large Multimodal Model (LMM) and verified by human annotators. Results with this dataset demonstrate that our approach improves resolution of safety situations, user sentiment, as well as safety of the conversation. Next, we deploy our dialogue system on a Hello Robot Stretch robot and conduct a within-subject user study with real-world participants. In the study, participants role-play two safety scenarios with different levels of severity with the robot and receive interventions from our model and a baseline system powered by OpenAI's ChatGPT. The study results corroborate and extend the findings from the automated evaluation, showing that our proposed system is more persuasive in a real-world embodied agent setting.