Preference Aligned Diffusion Planner for Quadrupedal Locomotion Control
作者: Xinyi Yuan, Zhiwei Shang, Zifan Wang, Chenkai Wang, Zhao Shan, Meixin Zhu, Chenjia Bai, Xuelong Li, Weiwei Wan, Kensuke Harada
分类: cs.RO
发布日期: 2024-10-17 (更新: 2025-03-03)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出偏好对齐扩散规划器,提升四足机器人运动控制在有限数据集下的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 四足机器人 运动控制 扩散模型 偏好学习 强化学习
📋 核心要点
- 四足机器人运动控制依赖大量数据,但现有扩散规划器受限于预收集数据集的多样性,鲁棒性不足。
- 提出两阶段学习框架,离线学习状态-动作分布,在线通过弱偏好标记进行交互,提升行为多样性。
- 实验表明,该方法在不同步态和速度下均表现出卓越的稳定性和速度跟踪精度,并能零样本迁移到真实机器人。
📝 摘要(中文)
扩散模型在捕捉大规模数据集中的复杂分布方面表现出卓越的性能,为四足机器人运动控制提供了一个有前景的解决方案。然而,扩散规划器的鲁棒性本质上依赖于预先收集的数据集的多样性。为了缓解这个问题,我们提出了一个两阶段学习框架,以增强扩散规划器在有限数据集(与奖励无关)下的能力。通过离线阶段,扩散规划器从专家数据集中学习状态-动作序列的联合分布,而不使用奖励标签。随后,我们基于训练好的离线规划器在仿真环境中进行在线交互,这显著地多样化了原始行为,从而提高了鲁棒性。具体来说,我们提出了一种新颖的弱偏好标记方法,无需真实奖励或人类偏好。所提出的方法在不同速度下的步态、小跑和跳跃步态中表现出卓越的稳定性和速度跟踪精度,并且可以对真实的Unitree Go1机器人执行零样本迁移。
🔬 方法详解
问题定义:现有四足机器人运动控制方法依赖大量高质量数据,而扩散模型虽然能学习复杂分布,但其性能受限于预收集数据集的多样性。在数据量有限的情况下,扩散规划器的鲁棒性较差,难以适应真实环境中的各种挑战。因此,如何提升扩散规划器在有限数据集下的鲁棒性是本文要解决的核心问题。
核心思路:本文的核心思路是通过一个两阶段的学习框架来增强扩散规划器的能力。首先,在离线阶段,利用专家数据集学习状态-动作序列的联合分布,无需奖励标签。然后,在在线阶段,基于离线规划器在仿真环境中进行交互,通过弱偏好标记方法,鼓励探索更多样的行为,从而提高规划器的鲁棒性。
技术框架:该方法包含两个主要阶段:离线学习阶段和在线交互阶段。在离线学习阶段,使用扩散模型学习专家数据集中的状态-动作序列的联合分布。在在线交互阶段,首先使用离线训练好的扩散规划器生成初始动作序列,然后在仿真环境中执行这些动作,并根据结果使用弱偏好标记方法对动作序列进行评估。根据评估结果,调整扩散规划器的参数,使其能够生成更符合偏好的动作序列。
关键创新:本文最重要的创新点在于提出了弱偏好标记方法,该方法无需真实的奖励函数或人类偏好,而是通过比较不同动作序列的性能来自动生成偏好标签。这种方法降低了对人工标注的依赖,并且能够有效地引导扩散规划器探索更多样的行为。
关键设计:弱偏好标记方法的具体实现是:在仿真环境中执行多个由扩散规划器生成的动作序列,然后比较这些序列的性能指标(例如,速度跟踪误差、稳定性等)。选择性能较好的序列作为“胜者”,性能较差的序列作为“败者”。然后,使用这些胜者和败者序列来训练一个偏好模型,该模型能够预测给定状态下,哪个动作序列更符合偏好。最后,使用该偏好模型来调整扩散规划器的参数,使其能够生成更符合偏好的动作序列。
🖼️ 关键图片
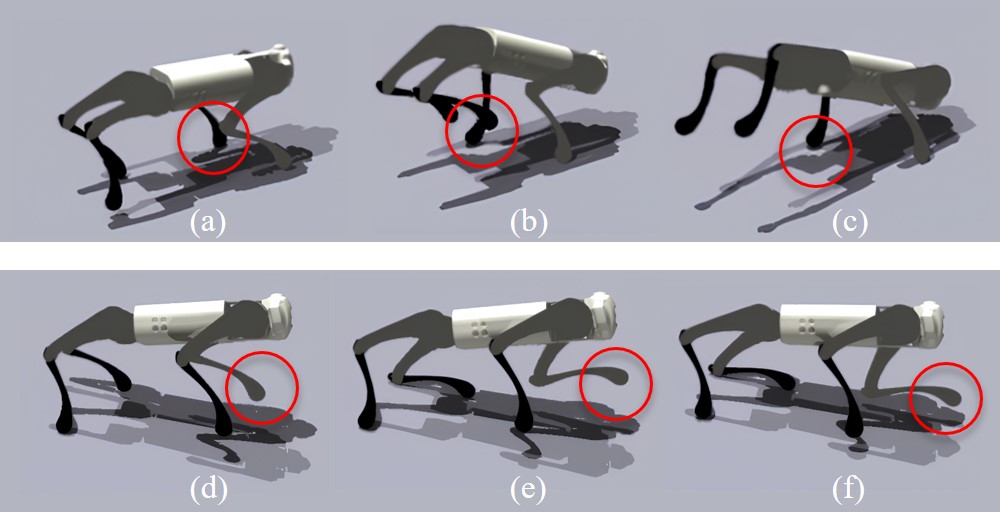


📊 实验亮点
实验结果表明,该方法在步态、小跑和跳跃步态下,速度跟踪精度和稳定性均优于现有方法。在不同速度下,该方法也能保持良好的性能。更重要的是,该方法能够实现零样本迁移到真实的Unitree Go1机器人,验证了其在真实环境中的可行性和有效性。具体数据提升幅度未知。
🎯 应用场景
该研究成果可应用于各种四足机器人的运动控制任务,尤其是在数据收集成本高昂或难以获取真实奖励信号的场景下。例如,在复杂地形或未知环境中,可以利用该方法训练出鲁棒的运动控制器,使四足机器人能够安全有效地完成任务。此外,该方法还可以扩展到其他类型的机器人和控制问题中。
📄 摘要(原文)
Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, the robustness of the diffusion planner is inherently dependent on the diversity of the pre-collected datasets. To mitigate this issue, we propose a two-stage learning framework to enhance the capability of the diffusion planner under limited dataset (reward-agnostic). Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planner, which significantly diversified the original behavior and thus improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under different speeds and can perform a zero-shot transfer to the real Unitree Go1 robots. The project website for this paper is at https://shangjaven.github.io/preference-aligned-diffusion-legged.