Configurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
作者: Anthony Opipari, Aravindhan K Krishnan, Shreekant Gayaka, Min Sun, Cheng-Hao Kuo, Arnie Sen, Odest Chadwicke Jenkins
分类: cs.RO, cs.CV
发布日期: 2024-10-16
备注: Accepted in IEEE Robotics and Automation Letters October 2024
💡 一句话要点
提出一种可配置的具身数据生成方法,用于提升机器人平台上的类别无关RGB-D视频分割性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视频分割 数据生成 机器人视觉 RGB-D 深度学习 迁移学习
📋 核心要点
- 现有方法在将通用分割模型应用于特定机器人平台时,忽略了机器人自身的具身特性,导致性能受限。
- 论文提出一种可配置的具身数据生成流水线,通过模拟不同机器人平台的传感器配置和环境光照,生成更贴合实际应用场景的数据。
- 实验表明,使用生成的MVPd数据集进行微调,可以显著提升基础模型在特定机器人平台上的视频分割性能,并验证了3D模态的有效性。
📝 摘要(中文)
本文提出了一种生成大规模数据集的方法,旨在提升不同形态机器人上的类别无关视频分割性能。具体而言,本文研究了在数据生成过程中考虑机器人具身特性(如传感器类型、传感器位置和光源)的情况下,在通用分割数据上训练的视频分割模型是否能更有效地应用于特定机器人平台。为了解决这个问题,本文构建了一个流水线,利用3D重建数据(例如来自HM3DSem)生成分割视频,这些视频可以根据机器人的具身特性进行配置。同时,本文还引入了一个大规模RGB-D视频全景分割数据集(MVPd),用于对基础模型和视频分割模型进行广泛的基准测试,并支持以具身特性为中心的视频分割研究。实验结果表明,使用MVPd进行微调可以提高基础模型在特定机器人具身特性(如特定相机位置)上的迁移性能。这些实验还表明,使用3D模态(深度图像和相机姿态)可以提高视频分割的准确性和一致性。项目网页可在https://topipari.com/projects/MVPd 访问。
🔬 方法详解
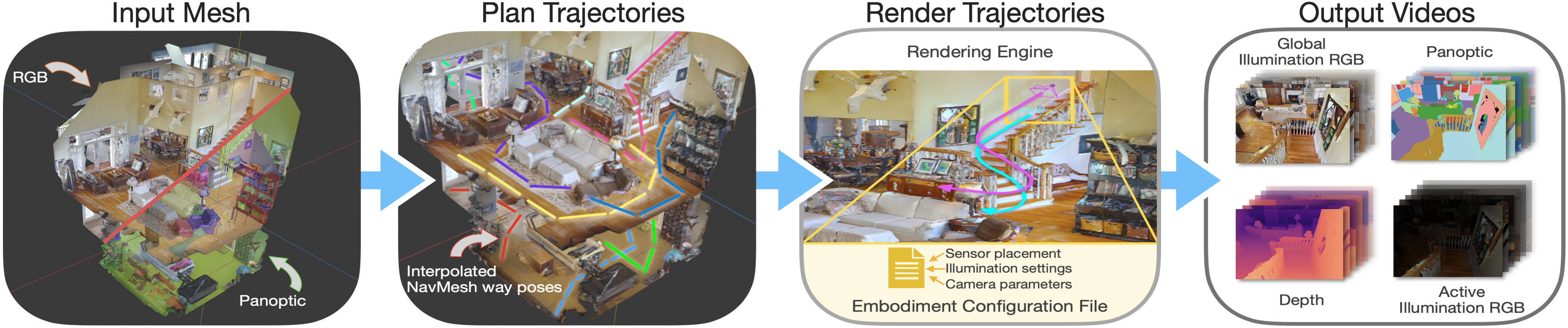
问题定义:现有的视频分割模型通常在通用数据集上训练,忽略了不同机器人平台的具身特性(如传感器类型、位置和环境光照)。这导致模型在特定机器人上的泛化能力较差,无法充分利用机器人自身的传感器信息。因此,需要一种方法来生成更贴合特定机器人平台的数据,以提升视频分割模型的性能。
核心思路:论文的核心思路是利用3D重建数据,模拟不同机器人平台的传感器配置和环境光照,生成可配置的具身数据集。通过在这些数据集上进行训练或微调,可以使模型更好地适应特定机器人平台的具身特性,从而提升视频分割的性能。这种方法的核心在于将机器人自身的物理属性融入到数据生成过程中。
技术框架:该方法包含以下几个主要步骤:1) 利用3D重建数据(如HM3DSem)构建虚拟环境;2) 根据目标机器人平台的具身特性(如相机类型、位置、视野范围等)配置虚拟相机的参数;3) 模拟环境光照条件;4) 在虚拟环境中渲染生成RGB-D视频,并进行分割标注;5) 构建大规模的具身视频分割数据集(MVPd)。
关键创新:该方法最重要的创新点在于提出了可配置的具身数据生成流水线。与以往的通用数据生成方法不同,该方法能够根据特定机器人平台的具身特性进行定制化数据生成,从而使模型更好地适应实际应用场景。此外,该方法还充分利用了3D信息(深度图像和相机姿态),为视频分割提供了更丰富的上下文信息。
关键设计:在数据生成过程中,关键的设计包括:1) 虚拟相机的参数设置,需要精确模拟真实相机的内外参数;2) 环境光照的模拟,需要考虑不同光照条件对图像质量的影响;3) 分割标注的自动化,需要保证标注的准确性和一致性;4) 数据集的规模,需要足够大以保证模型的泛化能力。此外,损失函数的设计也至关重要,需要考虑分割的准确性和一致性,以及对不同类别的平衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用MVPd数据集进行微调可以显著提升基础模型在特定机器人平台上的视频分割性能。例如,在特定相机位置的设置下,性能提升幅度可观。此外,实验还验证了3D模态(深度图像和相机姿态)对视频分割准确性和一致性的提升作用。这些结果表明,具身数据生成方法能够有效地提升机器人视觉感知能力。
🎯 应用场景
该研究成果可广泛应用于机器人视觉领域,例如家庭服务机器人、自动驾驶汽车、工业机器人等。通过使用具身数据进行训练,可以提升机器人在复杂环境下的感知能力,从而实现更智能、更可靠的自主导航、目标识别和场景理解等功能。此外,该方法还可以用于评估不同机器人平台的传感器配置对视觉感知性能的影响,为机器人设计提供指导。
📄 摘要(原文)
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd