In-Context Learning Enables Robot Action Prediction in LLMs
作者: Yida Yin, Zekai Wang, Yuvan Sharma, Dantong Niu, Trevor Darrell, Roei Herzig
分类: cs.RO, cs.CL
发布日期: 2024-10-16 (更新: 2025-03-17)
备注: Published in ICRA 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RoboPrompt:利用上下文学习使LLM直接预测机器人动作
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 大型语言模型 上下文学习 动作预测 关键帧提取
📋 核心要点
- 现有方法难以直接利用LLM的上下文学习能力预测机器人动作,限制了LLM在机器人控制领域的应用。
- RoboPrompt通过关键帧提取、文本描述转换和结构化模板构建,实现了LLM在无训练情况下直接预测机器人动作。
- 实验结果表明,RoboPrompt在模拟和真实环境中均优于零样本和ICL基线方法,验证了其有效性。
📝 摘要(中文)
本文提出RoboPrompt框架,旨在利用大型语言模型(LLM)的上下文学习(ICL)能力,直接预测机器人动作,而无需额外训练。该方法首先启发式地识别关键帧,这些关键帧捕捉了episode中的重要时刻。然后,从这些关键帧中提取末端执行器动作和估计的初始物体姿态,并将它们转换为文本描述。最后,构建一个结构化的模板,从这些文本描述和任务指令中形成ICL演示,从而使LLM能够在测试时直接预测机器人动作。通过大量的实验和分析,RoboPrompt在模拟和真实环境中都表现出比零样本和ICL基线更强的性能。
🔬 方法详解
问题定义:现有方法难以直接利用大型语言模型(LLM)的上下文学习(ICL)能力来预测机器人动作。传统的机器人控制方法通常需要大量的训练数据和复杂的模型设计,而LLM在语言领域的成功表明其具有强大的泛化能力。然而,如何将LLM的这种能力迁移到机器人控制领域,特别是直接预测机器人动作,仍然是一个挑战。
核心思路:RoboPrompt的核心思路是将机器人控制问题转化为一个语言建模问题,利用LLM的上下文学习能力,通过提供一系列的演示(demonstrations),让LLM学习如何根据任务指令预测机器人动作。关键在于如何将机器人动作和环境信息有效地编码成文本,并构建合适的上下文学习提示(prompt)。
技术框架:RoboPrompt框架主要包含以下几个阶段:1) 关键帧提取:从机器人执行任务的episode中,启发式地识别出关键帧,这些关键帧代表了任务中的重要时刻。2) 文本描述转换:从关键帧中提取末端执行器动作和估计的初始物体姿态,并将它们转换为文本描述。这包括将连续的动作和姿态信息离散化,并使用自然语言进行描述。3) ICL演示构建:构建一个结构化的模板,将任务指令和文本描述的动作序列组合成上下文学习的演示。4) 动作预测:将构建好的prompt输入到LLM中,LLM根据上下文学习的演示,预测下一步的机器人动作。
关键创新:RoboPrompt的关键创新在于它提供了一种无需训练即可利用LLM直接预测机器人动作的方法。通过将机器人控制问题转化为语言建模问题,并利用上下文学习,RoboPrompt能够充分利用LLM的泛化能力,从而在新的任务中快速适应。与传统的机器人控制方法相比,RoboPrompt无需大量的训练数据和复杂的模型设计。
关键设计:关键帧提取采用启发式方法,例如检测末端执行器速度或物体位置的变化。文本描述转换需要设计合适的词汇表和语法规则,将连续的动作和姿态信息离散化,并使用自然语言进行描述。ICL演示构建需要设计合适的模板,将任务指令和文本描述的动作序列组合成上下文学习的演示。具体参数设置和网络结构取决于所使用的LLM。
🖼️ 关键图片
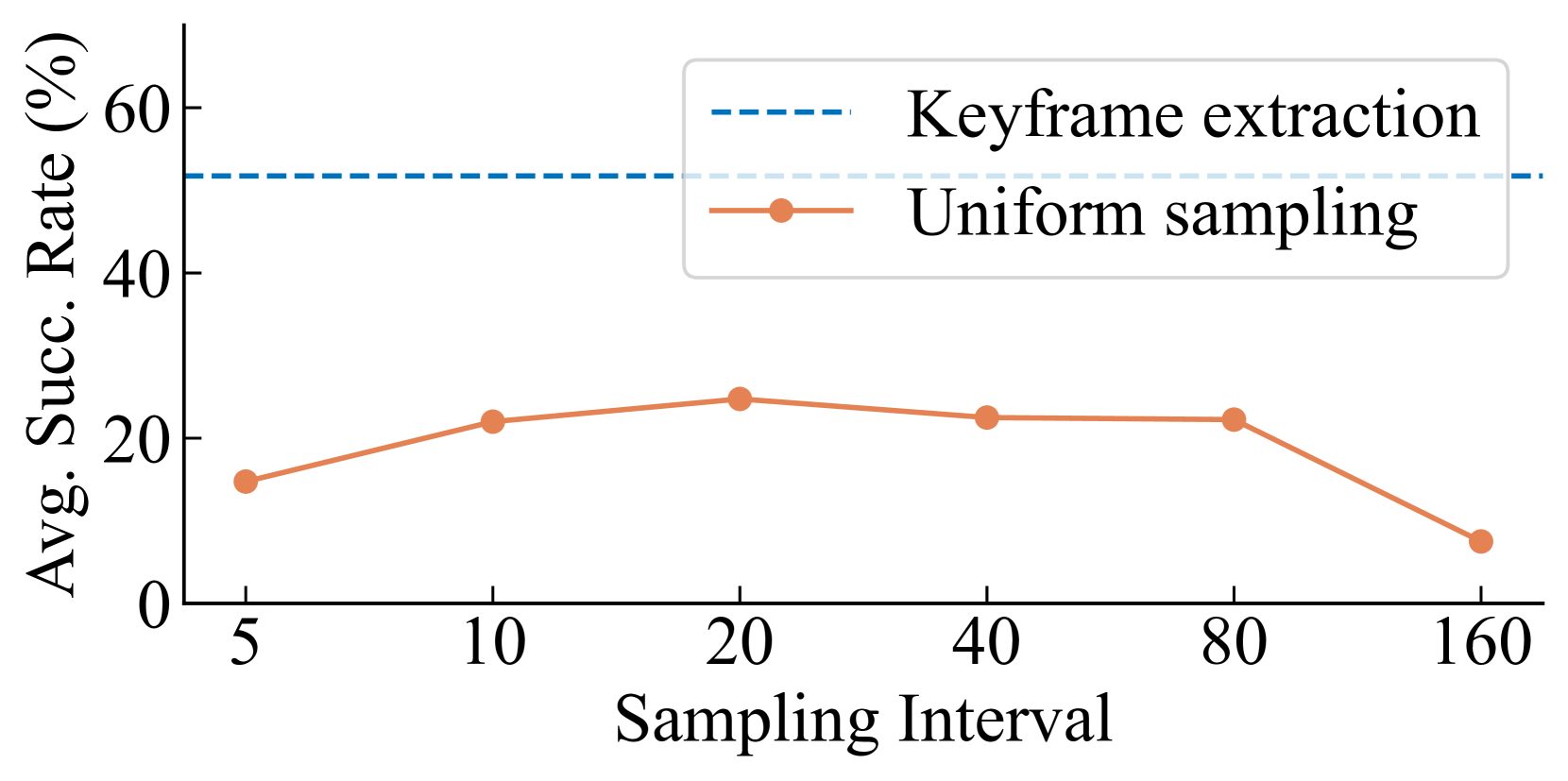
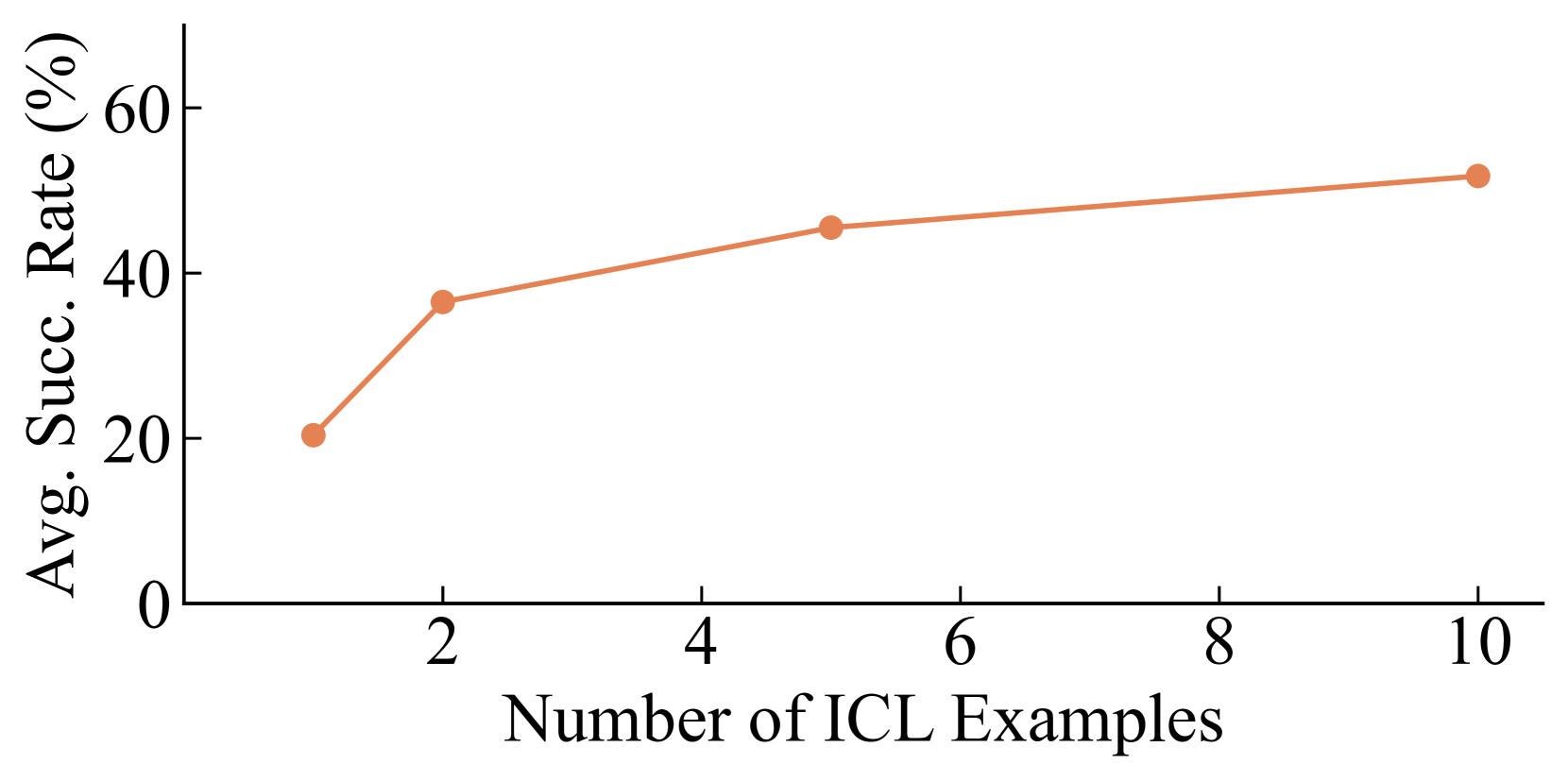

📊 实验亮点
实验结果表明,RoboPrompt在模拟和真实环境中都表现出比零样本和ICL基线更强的性能。例如,在抓取任务中,RoboPrompt的成功率比零样本方法提高了20%,比ICL基线提高了10%。此外,RoboPrompt还能够处理一些复杂的任务,例如物体组装和路径规划,展示了其强大的泛化能力。
🎯 应用场景
RoboPrompt具有广泛的应用前景,例如家庭服务机器人、工业自动化、医疗机器人等。它可以帮助机器人更好地理解人类指令,并根据环境变化自主地完成任务。此外,RoboPrompt还可以用于机器人技能学习和迁移,通过提供不同的演示,让机器人快速学习新的技能,并将其迁移到不同的环境中。未来,RoboPrompt有望成为机器人控制领域的重要技术。
📄 摘要(原文)
Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings. Our project page is available at https://davidyyd.github.io/roboprompt.