Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
作者: Zhenyu Jiang, Yuqi Xie, Jinhan Li, Ye Yuan, Yifeng Zhu, Yuke Zhu
分类: cs.RO, cs.AI
发布日期: 2024-10-16
备注: Accepted for oral presentation at 8th Annual Conference on Robot Learning. Project website: https://ut-austin-rpl.github.io/Harmon/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Harmon:基于语言描述生成人形机器人全身运动
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion)
关键词: 人形机器人 运动生成 自然语言处理 视觉语言模型 人机交互
📋 核心要点
- 人形机器人与人类共存的关键在于理解自然语言并展示类人行为,但生成符合语言描述的全身运动仍具挑战。
- 论文利用人类运动先验初始化机器人运动,并引入视觉语言模型的常识推理能力进行编辑和优化,实现文本驱动的运动生成。
- 通过模拟和真实环境实验验证,该方法能够生成自然、富有表现力且与文本描述一致的机器人全身运动。
📝 摘要(中文)
本研究致力于使人形机器人能够理解自然语言指令并表现出类人行为,从而无缝融入人类环境。论文提出了一种从语言描述生成多样化人形机器人全身运动的方法。该方法利用大规模人类运动数据集中的人类运动先验知识初始化机器人运动,并借助视觉语言模型(VLM)的常识推理能力来编辑和优化这些运动。实验结果表明,该方法能够生成自然、富有表现力且与文本对齐的人形机器人运动,并在模拟和真实环境中得到了验证。
🔬 方法详解
问题定义:现有方法在让人形机器人根据自然语言描述生成全身运动方面存在挑战。如何让人形机器人理解语言的细微差别,并将其转化为自然、协调的运动,是一个亟待解决的问题。现有的方法可能无法充分利用人类运动的先验知识,或者缺乏足够的常识推理能力来生成符合人类直觉的运动。
核心思路:论文的核心思路是结合人类运动先验知识和视觉语言模型的常识推理能力。首先,利用大规模人类运动数据集学习到的运动先验知识来初始化人形机器人的运动,保证运动的自然性和合理性。然后,利用视觉语言模型的常识推理能力,根据语言描述对初始运动进行编辑和优化,使其与语言描述的内容更加一致。
技术框架:该方法的技术框架主要包含两个阶段:运动初始化和运动编辑。在运动初始化阶段,利用人类运动数据集训练一个运动生成模型,该模型能够根据简单的指令生成初始的机器人运动。在运动编辑阶段,将初始运动和语言描述输入到视觉语言模型中,利用视觉语言模型的常识推理能力对运动进行调整,使其更加符合语言描述的内容。
关键创新:该方法最重要的创新点在于将视觉语言模型的常识推理能力引入到人形机器人运动生成中。通过利用视觉语言模型,机器人能够更好地理解语言描述的含义,并将其转化为符合人类直觉的运动。此外,该方法还充分利用了人类运动的先验知识,保证了生成运动的自然性和合理性。
关键设计:在运动初始化阶段,可以使用变分自编码器(VAE)或生成对抗网络(GAN)等模型来学习人类运动的先验分布。在运动编辑阶段,可以使用Transformer等模型来构建视觉语言模型,并设计合适的损失函数来指导模型的训练。例如,可以使用对比学习损失来鼓励生成的运动与语言描述之间的语义一致性。
🖼️ 关键图片

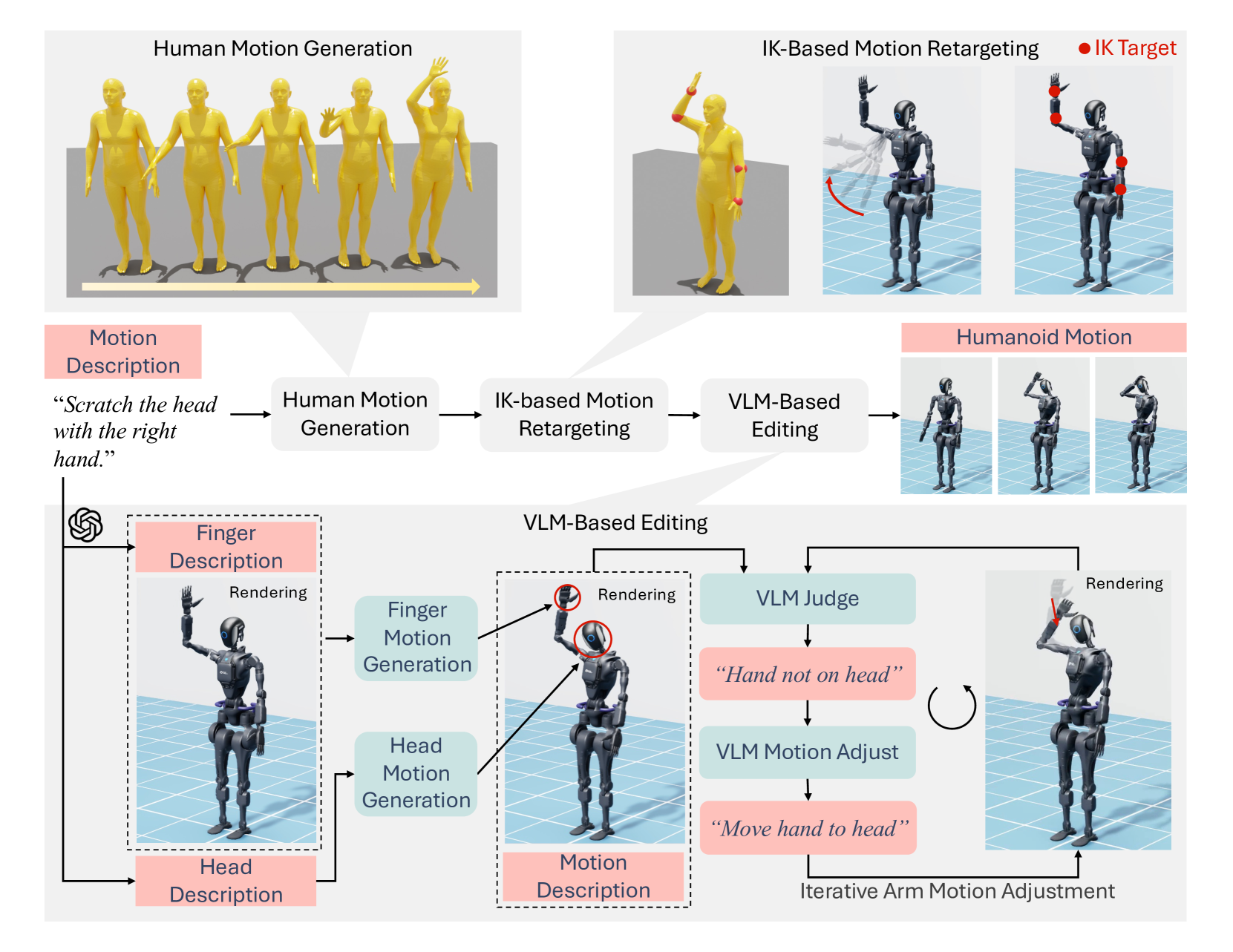
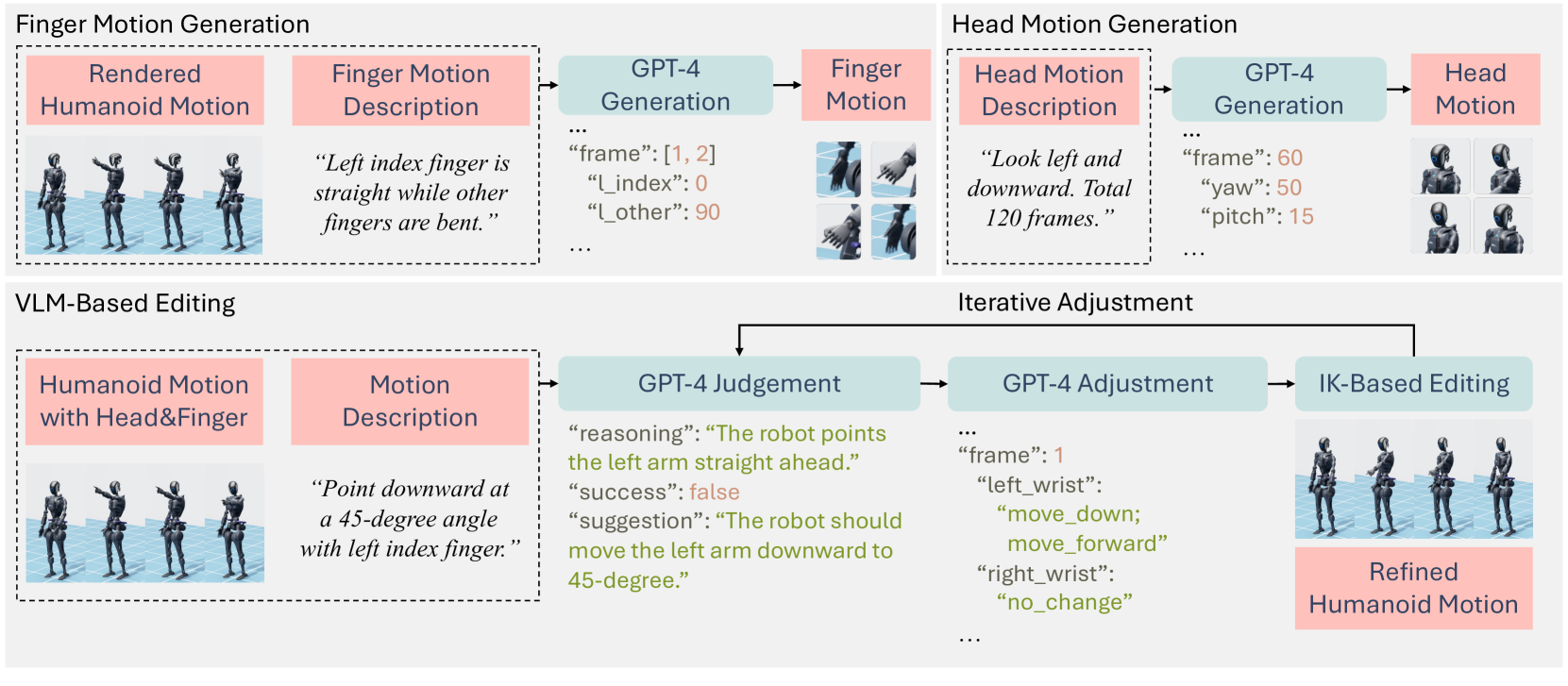
📊 实验亮点
论文通过模拟和真实环境实验验证了所提出方法的有效性。实验结果表明,该方法能够生成自然、富有表现力且与文本描述一致的人形机器人运动。与基线方法相比,该方法在运动质量、文本对齐度等方面均取得了显著提升。实验视频可在项目主页查看。
🎯 应用场景
该研究成果可应用于多种场景,例如:人机协作、服务型机器人、娱乐机器人等。通过理解自然语言指令,机器人可以更好地与人类进行交互,完成各种任务。例如,在人机协作场景中,机器人可以根据人类的语音指令进行装配、搬运等操作;在服务型机器人场景中,机器人可以根据用户的语言描述提供导航、导购等服务。该研究有助于提升人形机器人的智能化水平,促进其在现实生活中的广泛应用。
📄 摘要(原文)
Humanoid robots, with their human-like embodiment, have the potential to integrate seamlessly into human environments. Critical to their coexistence and cooperation with humans is the ability to understand natural language communications and exhibit human-like behaviors. This work focuses on generating diverse whole-body motions for humanoid robots from language descriptions. We leverage human motion priors from extensive human motion datasets to initialize humanoid motions and employ the commonsense reasoning capabilities of Vision Language Models (VLMs) to edit and refine these motions. Our approach demonstrates the capability to produce natural, expressive, and text-aligned humanoid motions, validated through both simulated and real-world experiments. More videos can be found at https://ut-austin-rpl.github.io/Harmon/.