Improving the Generalization of Unseen Crowd Behaviors for Reinforcement Learning based Local Motion Planners
作者: Wen Zheng Terence Ng, Jianda Chen, Sinno Jialin Pan, Tianwei Zhang
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-10-16
DOI: 10.1109/ICRA57147.2024.10610641
💡 一句话要点
提出基于信息论目标最大化的强化学习方法,提升机器人对未知人群行为的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人导航 运动规划 人群行为 信息论 泛化能力 避障
📋 核心要点
- 现有基于强化学习的运动规划器在行人环境中易过拟合,难以应对行人行为的不可预测性。
- 该论文提出一种通过最大化信息论目标来增强智能体多样性的方法,提升对未知人群行为的适应性。
- 实验结果表明,该方法在模拟行人场景中优于现有方法,有效减少了碰撞风险。
📝 摘要(中文)
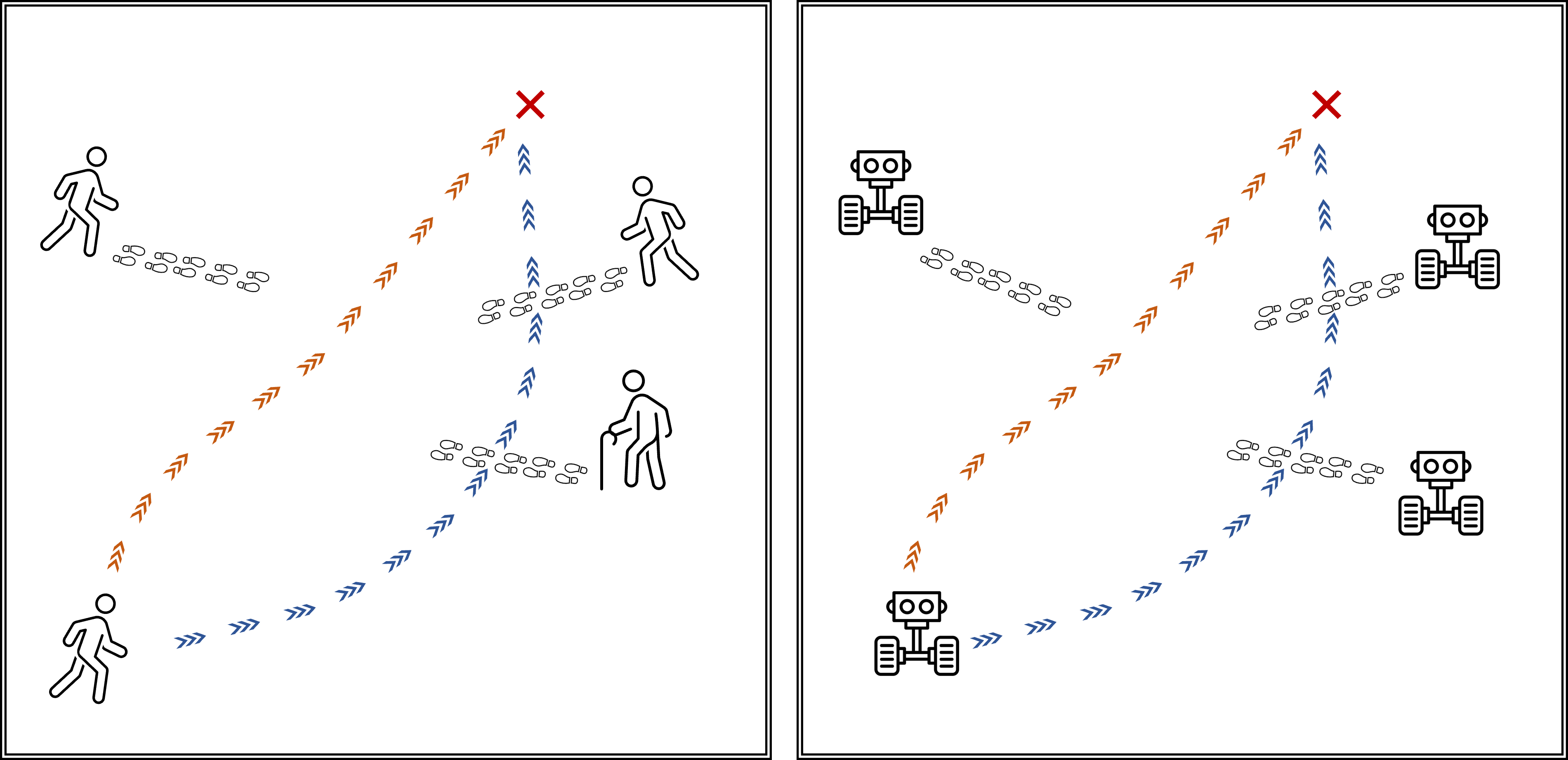
在行人环境中部署安全的移动机器人策略极具挑战,因为行人运动具有不可预测性。现有的基于强化学习的运动规划器依赖于单一策略来模拟行人运动,容易出现过拟合问题。将避障问题视为多智能体框架,虽然智能体可以生成动态运动并学习到达目标,但由于同质性,可能与行人发生冲突。为了解决这个问题,我们提出了一种有效的方法,通过最大化信息论目标来增强单个策略中智能体的多样性。这种多样性丰富了每个智能体的经验,提高了其对未知人群行为的适应性。为了评估智能体对未知人群的鲁棒性,我们提出了受行人行为启发的各种场景。在这些具有挑战性的场景中,我们的行为条件策略优于现有方法,减少了潜在的碰撞,且没有增加额外的时间或行程。
🔬 方法详解
问题定义:论文旨在解决强化学习在机器人局部运动规划中,对未见过的行人拥挤环境泛化能力不足的问题。现有方法主要痛点在于:一是过度依赖单一策略模拟行人,导致对训练数据过拟合;二是将避障问题建模为多智能体框架时,智能体同质性导致与行人行为冲突。
核心思路:论文的核心思路是通过增加智能体策略的多样性,使其能够更好地适应各种未知的行人行为。具体而言,通过最大化信息论目标,鼓励智能体探索不同的行为模式,从而提升其泛化能力和鲁棒性。
技术框架:整体框架基于强化学习,主要包含以下几个模块:1) 环境模拟器,用于生成包含各种行人行为的场景;2) 智能体策略网络,用于学习机器人的运动规划策略;3) 信息论目标函数,用于鼓励智能体探索多样化的行为;4) 奖励函数,用于引导智能体完成避障任务。训练过程中,智能体与环境交互,根据奖励和信息论目标更新策略网络。
关键创新:论文的关键创新在于引入了信息论目标来增强智能体策略的多样性。与传统的强化学习方法相比,该方法能够显式地鼓励智能体探索不同的行为模式,从而提升其对未知环境的适应能力。这种方法避免了单一策略的过拟合问题,并减少了与行人行为的冲突。
关键设计:论文中,信息论目标函数的设计至关重要,具体形式未知。此外,奖励函数的设计也需要仔细考虑,以平衡避障任务的完成和行为多样性的探索。策略网络的结构和参数设置也需要根据具体任务进行调整。论文中提到的“行为条件策略”的具体实现方式未知,可能涉及到将行人行为作为策略网络的输入。
🖼️ 关键图片

📊 实验亮点
论文通过在模拟的行人拥挤场景中进行实验,验证了所提出方法的有效性。实验结果表明,该方法在减少碰撞风险方面优于现有方法,并且没有增加额外的时间或行程。具体的性能数据和对比基线未知,但整体结果表明该方法具有显著的优势。
🎯 应用场景
该研究成果可应用于各种需要在拥挤人群中安全导航的机器人场景,例如:服务机器人、自动驾驶汽车、无人机等。通过提升机器人对行人行为的理解和适应能力,可以有效减少事故风险,提高机器人的实用性和安全性,具有重要的实际应用价值和潜在的社会效益。
📄 摘要(原文)
Deploying a safe mobile robot policy in scenarios with human pedestrians is challenging due to their unpredictable movements. Current Reinforcement Learning-based motion planners rely on a single policy to simulate pedestrian movements and could suffer from the over-fitting issue. Alternatively, framing the collision avoidance problem as a multi-agent framework, where agents generate dynamic movements while learning to reach their goals, can lead to conflicts with human pedestrians due to their homogeneity. To tackle this problem, we introduce an efficient method that enhances agent diversity within a single policy by maximizing an information-theoretic objective. This diversity enriches each agent's experiences, improving its adaptability to unseen crowd behaviors. In assessing an agent's robustness against unseen crowds, we propose diverse scenarios inspired by pedestrian crowd behaviors. Our behavior-conditioned policies outperform existing works in these challenging scenes, reducing potential collisions without additional time or travel.