Learning from 10 Demos: Generalisable and Sample-Efficient Policy Learning with Oriented Affordance Frames
作者: Krishan Rana, Jad Abou-Chakra, Sourav Garg, Robert Lee, Ian Reid, Niko Suenderhauf
分类: cs.RO, cs.AI
发布日期: 2024-10-15 (更新: 2025-08-31)
备注: Accepted at the Conference on Robot Learning (CoRL), 2025. Videos can be found on our project website: https://affordance-policy.github.io
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于Oriented Affordance Frames的策略学习方法,仅需少量演示即可泛化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 模仿学习 机器人操作 策略学习 泛化能力 少量样本学习
📋 核心要点
- 现有模仿学习方法在长时程、多对象任务中样本效率低,泛化能力有限,需要大量演示数据。
- 论文提出Oriented Affordance Frames,对状态和动作空间进行结构化表示,提升空间和类内泛化能力。
- 实验表明,该方法仅需10个演示即可学习策略,并能泛化到未见过的对象,实现高成功率。
📝 摘要(中文)
模仿学习在机器人灵巧行为展示方面具有潜力,但由于样本效率低和泛化能力有限,它在长时程、多对象任务中仍然面临挑战。现有方法需要大量的演示来覆盖可能的任务变化,这使得它们成本高昂,并且在实际部署中往往不切实际。本文通过引入Oriented Affordance Frames来解决这一挑战,这是一种用于状态和动作空间的结构化表示,可提高空间和类内泛化能力,并使策略能够仅从10个演示中有效地学习。更重要的是,本文展示了这种抽象如何实现独立训练的子策略的组合泛化,以解决长时程、多对象任务。为了在子策略之间无缝过渡,本文引入了自我进度预测的概念,该概念直接从训练演示的持续时间中得出。本文在三个真实世界的任务中验证了该方法,每个任务都需要多步骤、多对象交互。尽管数据集很小,但策略能够稳健地泛化到未见过的对象外观、几何形状和空间排列,无需依赖详尽的训练数据即可实现高成功率。
🔬 方法详解
问题定义:现有模仿学习方法在处理长时程、多对象任务时,需要大量的演示数据才能保证策略的泛化能力,这在实际应用中成本很高且不切实际。因此,如何利用少量演示数据学习到具有良好泛化能力的策略是本文要解决的问题。
核心思路:论文的核心思路是利用Oriented Affordance Frames对状态和动作空间进行结构化表示,从而提高策略的空间和类内泛化能力。通过这种结构化的表示,策略可以更容易地学习到任务的关键特征,从而减少对大量演示数据的依赖。此外,论文还提出了自我进度预测的概念,用于在子策略之间进行无缝过渡。
技术框架:该方法的技术框架主要包含以下几个模块:1) Oriented Affordance Frames表示模块:用于将状态和动作空间转换为结构化的表示;2) 策略学习模块:利用少量演示数据学习策略;3) 自我进度预测模块:用于在子策略之间进行无缝过渡。整体流程是,首先利用Oriented Affordance Frames对状态和动作空间进行表示,然后利用少量演示数据训练策略,最后利用自我进度预测模块实现子策略之间的切换,完成长时程任务。
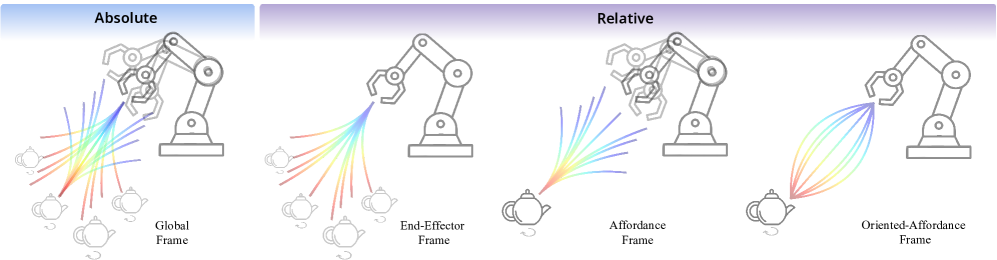
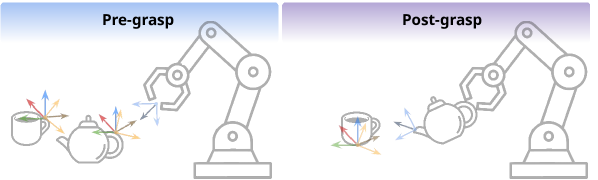
关键创新:该方法最重要的技术创新点在于Oriented Affordance Frames的引入。这种结构化的表示方式能够有效地提高策略的空间和类内泛化能力,从而减少对大量演示数据的依赖。与传统的模仿学习方法相比,该方法能够在少量演示数据下学习到更具泛化能力的策略。
关键设计:Oriented Affordance Frames的具体实现方式未知,论文中可能没有详细描述其参数设置和网络结构。自我进度预测模块的具体实现方式也未知,可能涉及到一些时间序列预测或者回归模型。
🖼️ 关键图片

📊 实验亮点
该方法在三个真实世界的机器人任务中进行了验证,每个任务都需要多步骤、多对象交互。实验结果表明,该方法仅需10个演示即可学习策略,并能泛化到未见过的对象外观、几何形状和空间排列,实现高成功率。这表明该方法具有很强的泛化能力和样本效率。
🎯 应用场景
该研究成果可应用于机器人操作、自动化装配、智能家居等领域。通过少量演示数据即可训练出具有良好泛化能力的机器人策略,降低了机器人部署的成本和难度。未来,该方法有望推广到更复杂的机器人任务中,实现更智能、更灵活的机器人应用。
📄 摘要(原文)
Imitation learning has unlocked the potential for robots to exhibit highly dexterous behaviours. However, it still struggles with long-horizon, multi-object tasks due to poor sample efficiency and limited generalisation. Existing methods require a substantial number of demonstrations to cover possible task variations, making them costly and often impractical for real-world deployment. We address this challenge by introducing oriented affordance frames, a structured representation for state and action spaces that improves spatial and intra-category generalisation and enables policies to be learned efficiently from only 10 demonstrations. More importantly, we show how this abstraction allows for compositional generalisation of independently trained sub-policies to solve long-horizon, multi-object tasks. To seamlessly transition between sub-policies, we introduce the notion of self-progress prediction, which we directly derive from the duration of the training demonstrations. We validate our method across three real-world tasks, each requiring multi-step, multi-object interactions. Despite the small dataset, our policies generalise robustly to unseen object appearances, geometries, and spatial arrangements, achieving high success rates without reliance on exhaustive training data. Video demonstration can be found on our project page: https://affordance-policy.github.io/.