Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
作者: Zixuan Chen, Xialin He, Yen-Jen Wang, Qiayuan Liao, Yanjie Ze, Zhongyu Li, S. Shankar Sastry, Jiajun Wu, Koushil Sreenath, Saurabh Gupta, Xue Bin Peng
分类: cs.RO, cs.AI
发布日期: 2024-10-15 (更新: 2024-10-28)
备注: 8 pages
💡 一句话要点
提出Lipschitz约束策略,实现人形机器人平滑鲁棒的强化学习运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 人形机器人 运动控制 Lipschitz约束 梯度惩罚
📋 核心要点
- 现有强化学习方法在人形机器人运动控制中依赖平滑奖励或低通滤波器,需要大量手动调参,缺乏通用性。
- 论文提出Lipschitz约束策略(LCP),通过约束策略的Lipschitz常数,直接控制策略的平滑性,无需额外奖励或滤波。
- 实验表明,LCP在多种人形机器人上有效,仿真和真实机器人实验均验证了其平滑性和鲁棒性。
📝 摘要(中文)
本文提出了一种简单有效的Lipschitz约束策略(LCP)方法,用于学习人形机器人的平滑运动控制策略。该方法通过在学习策略上施加Lipschitz约束,避免了传统方法中对平滑奖励或低通滤波器的需求,以及繁琐的超参数调整。Lipschitz约束以梯度惩罚的形式实现,可以轻松地与自动微分框架结合。实验结果表明,LCP能够有效地生成平滑且鲁棒的运动控制器,并在仿真和真实的人形机器人上都取得了成功。项目代码和模型已开源。
🔬 方法详解
问题定义:现有基于强化学习的人形机器人运动控制方法,为了获得平滑的运动轨迹,通常会引入平滑奖励或使用低通滤波器对动作进行平滑处理。然而,这些方法通常不可微,需要针对不同的机器人平台进行大量的超参数调整,缺乏通用性和可扩展性。因此,如何设计一种通用的、可微的、能够自动学习平滑运动控制策略的方法是一个关键问题。
核心思路:论文的核心思路是通过对学习到的策略施加Lipschitz约束,直接控制策略的平滑性。Lipschitz约束保证了策略输出的变化不会超过输入变化的某个倍数,从而避免了剧烈的动作变化,保证了运动的平滑性。这种方法避免了手动设计平滑奖励或使用低通滤波器,并且可以通过梯度惩罚的方式实现,方便与现有的强化学习框架结合。
技术框架:整体框架是在标准的强化学习训练循环中,增加一个Lipschitz约束的梯度惩罚项。具体来说,首先使用策略网络生成动作,然后计算动作关于状态的梯度,并对梯度的范数进行惩罚。这个惩罚项会促使策略网络学习到满足Lipschitz约束的策略。整个训练过程是端到端的,可以使用常见的强化学习算法进行优化。
关键创新:最重要的技术创新点是将Lipschitz约束引入到强化学习策略中,并以梯度惩罚的形式实现。与传统的平滑方法相比,这种方法是可微的,可以自动学习,并且不需要针对不同的机器人平台进行手动调整。此外,梯度惩罚的形式使得Lipschitz约束可以很容易地集成到现有的强化学习框架中。
关键设计:关键的设计包括:1) Lipschitz常数的选择:需要根据具体的机器人平台和任务进行调整,以保证策略的平滑性和性能。2) 梯度惩罚系数的选择:需要平衡策略的平滑性和探索能力。3) 策略网络的结构:可以使用常见的神经网络结构,如多层感知机或循环神经网络。4) 损失函数:除了标准的强化学习损失函数外,还需要加上Lipschitz约束的梯度惩罚项。
🖼️ 关键图片

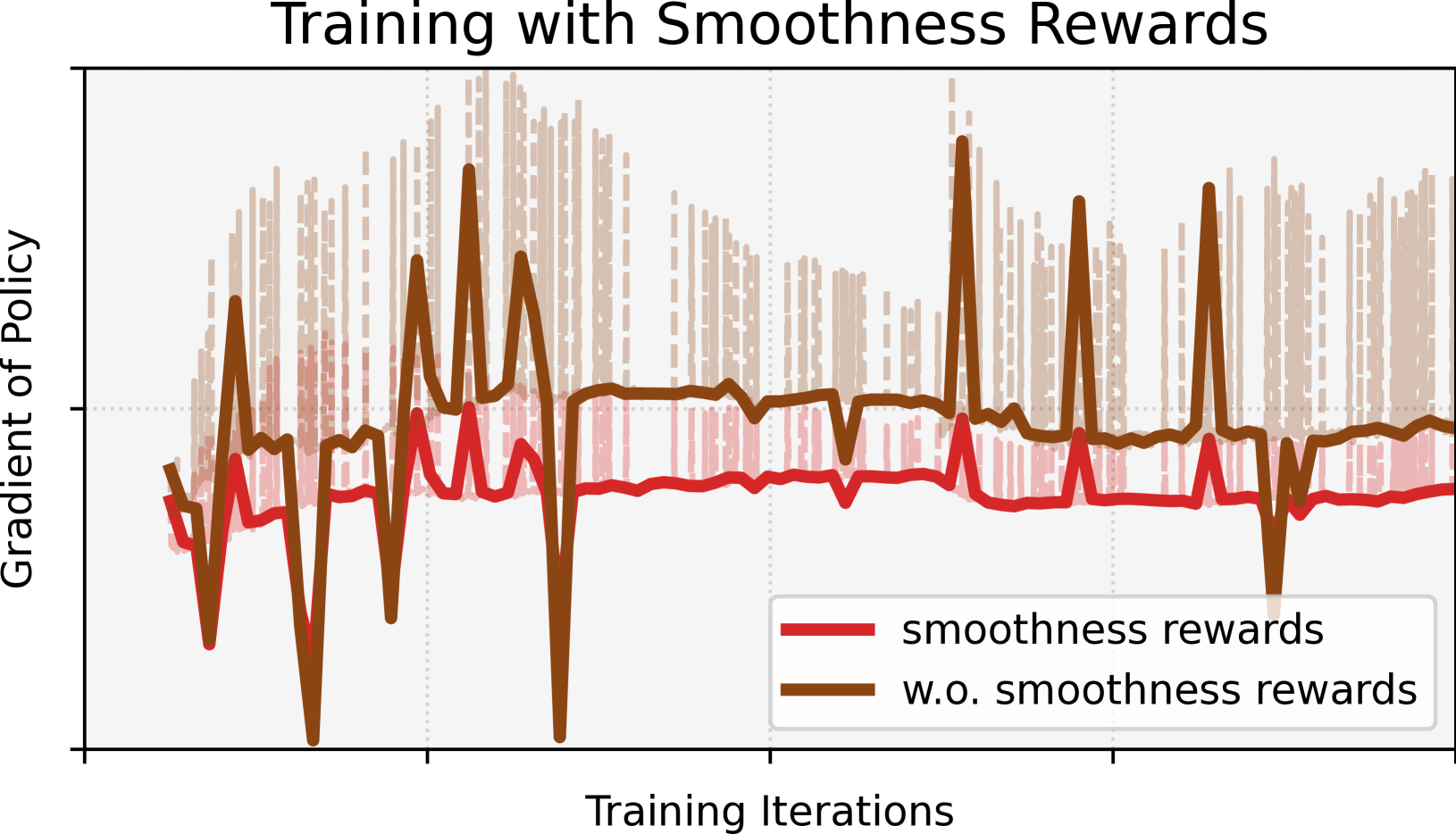

📊 实验亮点
实验结果表明,LCP方法在仿真和真实的人形机器人上都取得了显著的成功。与传统的平滑方法相比,LCP能够生成更平滑、更鲁棒的运动控制策略,并且不需要手动调整超参数。在真实机器人实验中,LCP能够使机器人稳定行走,即使在受到外部干扰的情况下也能保持平衡。项目开源了所有仿真和部署代码,以及完整的模型。
🎯 应用场景
该研究成果可广泛应用于人形机器人、四足机器人等腿式机器人的运动控制领域。通过学习平滑且鲁棒的运动控制策略,可以提高机器人在复杂环境中的适应性和稳定性,使其能够更好地完成各种任务,例如搜索救援、物流运输、家庭服务等。此外,该方法还可以推广到其他需要平滑控制的机器人系统,例如机械臂、无人机等。
📄 摘要(原文)
Reinforcement learning combined with sim-to-real transfer offers a general framework for developing locomotion controllers for legged robots. To facilitate successful deployment in the real world, smoothing techniques, such as low-pass filters and smoothness rewards, are often employed to develop policies with smooth behaviors. However, because these techniques are non-differentiable and usually require tedious tuning of a large set of hyperparameters, they tend to require extensive manual tuning for each robotic platform. To address this challenge and establish a general technique for enforcing smooth behaviors, we propose a simple and effective method that imposes a Lipschitz constraint on a learned policy, which we refer to as Lipschitz-Constrained Policies (LCP). We show that the Lipschitz constraint can be implemented in the form of a gradient penalty, which provides a differentiable objective that can be easily incorporated with automatic differentiation frameworks. We demonstrate that LCP effectively replaces the need for smoothing rewards or low-pass filters and can be easily integrated into training frameworks for many distinct humanoid robots. We extensively evaluate LCP in both simulation and real-world humanoid robots, producing smooth and robust locomotion controllers. All simulation and deployment code, along with complete checkpoints, is available on our project page: https://lipschitz-constrained-policy.github.io.