DeformPAM: Data-Efficient Learning for Long-horizon Deformable Object Manipulation via Preference-based Action Alignment
作者: Wendi Chen, Han Xue, Fangyuan Zhou, Yuan Fang, Cewu Lu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-10-15 (更新: 2025-03-12)
备注: Accepted to ICRA 2025. Project page: https://deform-pam.robotflow.ai
💡 一句话要点
提出DeformPAM,通过偏好学习高效解决长时程柔性物体操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 柔性物体操作 长时程任务 偏好学习 模仿学习 扩散模型 机器人学习 奖励学习
📋 核心要点
- 长时程柔性物体操作任务面临高维状态空间、复杂动力学和多模态动作分布的挑战,传统模仿学习方法需要大量数据且易产生分布偏移和累积误差。
- DeformPAM框架通过偏好学习和奖励引导的动作选择,将任务分解为动作原语,并利用扩散模型学习动作分布,从而实现数据高效的学习。
- 实验表明,DeformPAM在真实长时程柔性物体操作任务中,相比基线方法,在数据有限的情况下,显著提升了任务完成质量和效率。
📝 摘要(中文)
本文提出了一种数据高效的通用学习框架DeformPAM,用于解决柔性物体操作中的长时程任务难题。该方法基于偏好学习和奖励引导的动作选择,将长时程任务分解为多个动作原语,利用3D点云输入和扩散模型建模动作分布,并通过人类偏好数据训练隐式奖励模型。在推理阶段,奖励模型对多个候选动作进行评分,选择最优动作执行,从而减少异常动作的发生,提高任务完成质量。在三个具有挑战性的真实长时程柔性物体操作任务上的实验结果表明,即使在有限的数据下,DeformPAM相比基线方法在任务完成质量和效率方面均有所提高。
🔬 方法详解
问题定义:论文旨在解决长时程柔性物体操作任务中,传统模仿学习方法数据效率低、易受分布偏移和累积误差影响的问题。现有方法需要大量数据进行训练,且难以处理柔性物体操作中复杂的状态空间和动力学。
核心思路:论文的核心思路是利用偏好学习和奖励引导的动作选择,将长时程任务分解为多个易于学习的动作原语。通过人类偏好数据训练奖励模型,引导智能体选择更优的动作,从而提高任务完成质量和数据效率。这种方法避免了直接模仿专家轨迹,而是学习一个隐式的奖励函数,鼓励智能体做出符合人类偏好的动作。
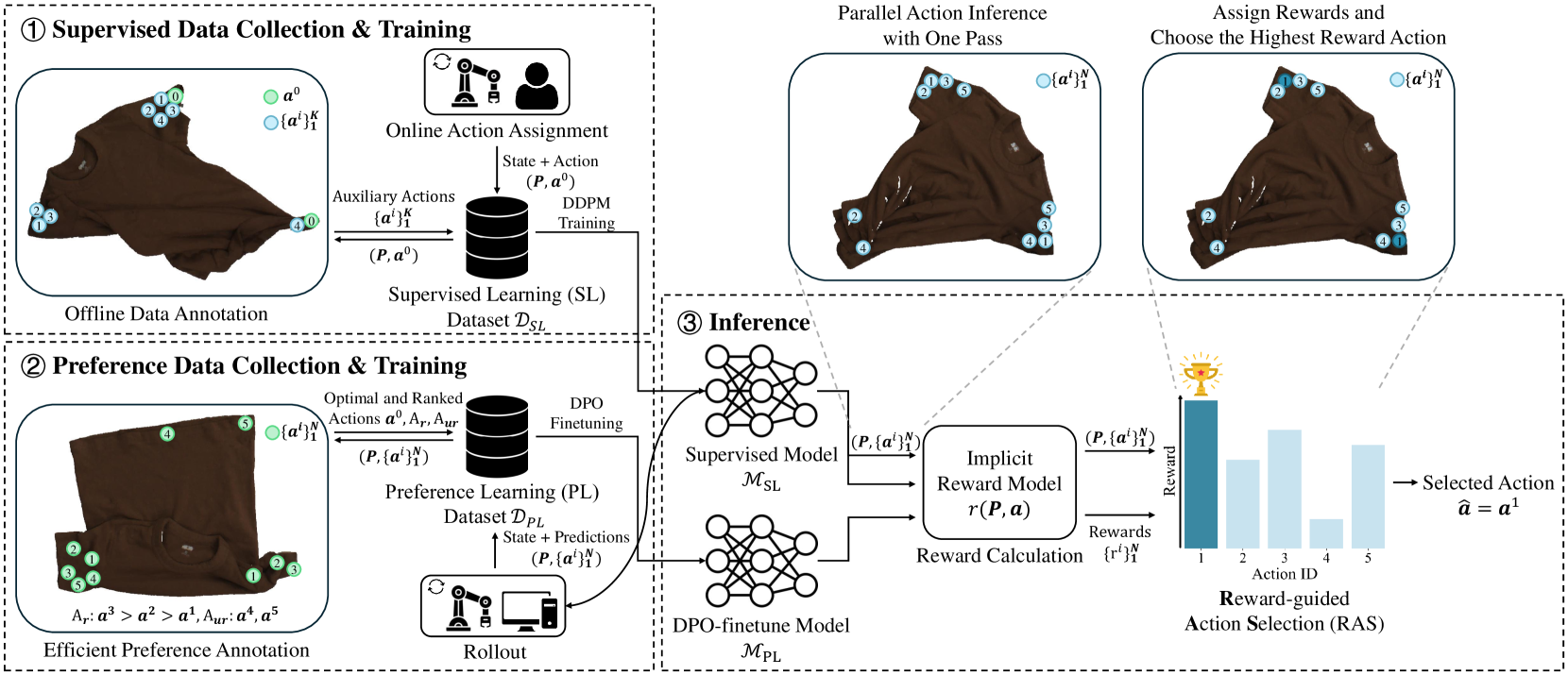
技术框架:DeformPAM框架主要包含以下几个模块:1) 3D点云输入模块,用于获取环境状态信息;2) 扩散模型,用于建模动作分布,生成候选动作;3) 奖励模型,基于人类偏好数据进行训练,对候选动作进行评分;4) 动作选择模块,选择奖励最高的动作执行。整个流程是,首先从环境中获取3D点云数据,然后扩散模型生成多个候选动作,奖励模型对这些动作进行评分,最后选择得分最高的动作执行,并重复这个过程直到任务完成。
关键创新:DeformPAM的关键创新在于将偏好学习和奖励引导的动作选择应用于长时程柔性物体操作任务。与传统的模仿学习方法相比,DeformPAM不需要大量的专家轨迹数据,而是通过人类偏好数据学习一个隐式的奖励函数,从而实现数据高效的学习。此外,利用扩散模型建模动作分布,可以更好地处理柔性物体操作中复杂的多模态动作空间。
关键设计:论文使用3D点云作为环境状态的输入,可以更好地捕捉柔性物体的形状和姿态信息。扩散模型采用U-Net结构,用于生成候选动作。奖励模型采用神经网络结构,输入为当前状态和动作,输出为奖励值。损失函数基于Bradley-Terry模型,用于训练奖励模型,使其能够准确预测人类对不同动作的偏好。具体的参数设置和网络结构细节在论文中有详细描述,但具体数值未知。
🖼️ 关键图片


📊 实验亮点
DeformPAM在三个真实的柔性物体操作任务上进行了验证,实验结果表明,即使在有限的数据下,DeformPAM相比于基线方法,显著提高了任务完成质量和效率。具体提升幅度未知,但论文强调了其数据效率优势。
🎯 应用场景
DeformPAM技术可应用于各种需要柔性物体操作的机器人任务中,例如服装整理、医疗手术、食品加工等。该技术能够降低机器人学习复杂操作任务所需的数据量,提高机器人的智能化水平和适应性,具有广泛的应用前景和实际价值。
📄 摘要(原文)
In recent years, imitation learning has made progress in the field of robotic manipulation. However, it still faces challenges when addressing complex long-horizon tasks with deformable objects, such as high-dimensional state spaces, complex dynamics, and multimodal action distributions. Traditional imitation learning methods often require a large amount of data and encounter distributional shifts and accumulative errors in these tasks. To address these issues, we propose a data-efficient general learning framework (DeformPAM) based on preference learning and reward-guided action selection. DeformPAM decomposes long-horizon tasks into multiple action primitives, utilizes 3D point cloud inputs and diffusion models to model action distributions, and trains an implicit reward model using human preference data. During the inference phase, the reward model scores multiple candidate actions, selecting the optimal action for execution, thereby reducing the occurrence of anomalous actions and improving task completion quality. Experiments conducted on three challenging real-world long-horizon deformable object manipulation tasks demonstrate the effectiveness of this method. Results show that DeformPAM improves both task completion quality and efficiency compared to baseline methods even with limited data. Code and data will be available at https://deform-pam.robotflow.ai.