SDS -- See it, Do it, Sorted: Quadruped Skill Synthesis from Single Video Demonstration
作者: Maria Stamatopoulou, Jeffrey Li, Dimitrios Kanoulas
分类: cs.RO
发布日期: 2024-10-15 (更新: 2025-08-20)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SDS:从单视频演示中合成四足机器人技能,无需标签或奖励工程。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 技能学习 单视频演示 奖励函数生成 大型语言模型 GPT-4o 强化学习
📋 核心要点
- 现有四足机器人技能学习方法依赖于大量标签数据或复杂的奖励函数工程,限制了其泛化性和易用性。
- SDS通过GPT-4o生成奖励函数,利用时空网格视觉编码和结构化输入分解,从单视频演示中提取运动信息。
- 实验表明,SDS在多种四足机器人上成功学习了多种步态,实现了高保真度的步态匹配和稳定的运动性能。
📝 摘要(中文)
本文提出了一种名为SDS(“See it. Do it. Sorted.”)的自动化流程,用于从非结构化演示视频中获取四足机器人运动技能。SDS利用GPT-4o,采用新颖的提示技术,包括基于时空网格的视觉编码($G_{v}$)和结构化输入分解(SUS),从原始输入视频中生成可执行的奖励函数(RF)。这些奖励函数用于训练PPO策略,并通过闭环进化进行优化,使用训练视频和性能指标作为自监督信号。SDS使四足机器人(如Unitree Go1)能够学习四种步态——小跑、奔跑、慢步和跳跃——实现100%的步态匹配保真度,动态时间规整(DTW)距离达到$10^{-6}$量级,并在模拟和真实环境中实现零失败的稳定运动。SDS可以推广到形态不同的四足机器人(如ANYmal),并在数据效率、训练时间和工程工作量方面优于先前的工作。相关材料和代码已开源。
🔬 方法详解
问题定义:现有四足机器人技能学习方法通常需要人工设计奖励函数或依赖大量标注数据,这既耗时又需要专业知识,限制了其在实际场景中的应用。如何仅从少量无标注的视频演示中学习复杂的运动技能,是本文要解决的核心问题。
核心思路:本文的核心思路是利用大型语言模型(LLM)如GPT-4o,从单视频演示中自动生成可执行的奖励函数。通过将视频信息编码成LLM可以理解的形式,并设计合适的提示语,引导LLM生成与目标运动技能相对应的奖励函数。然后,利用这些奖励函数训练强化学习策略,最终实现机器人的运动技能学习。
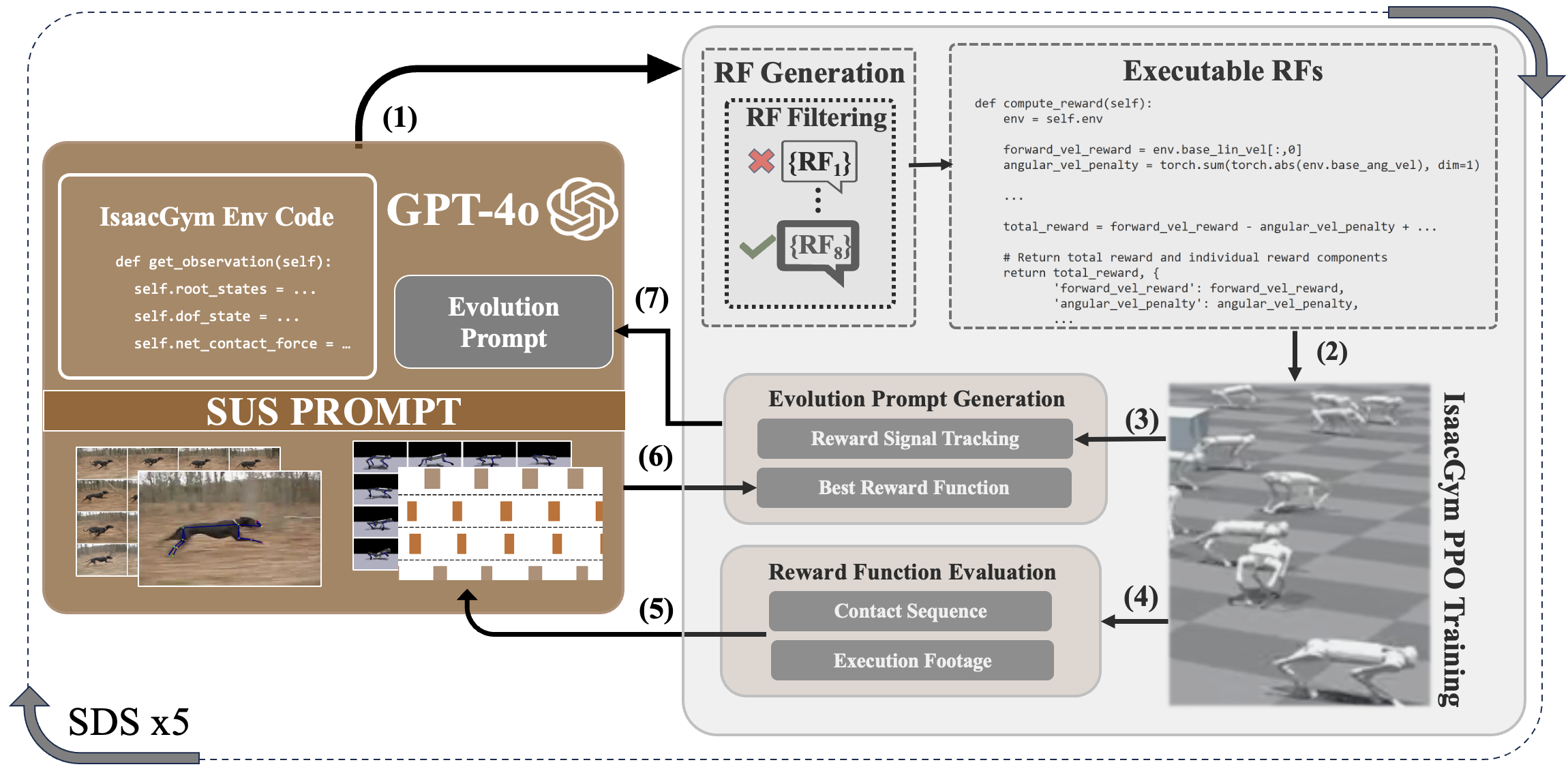
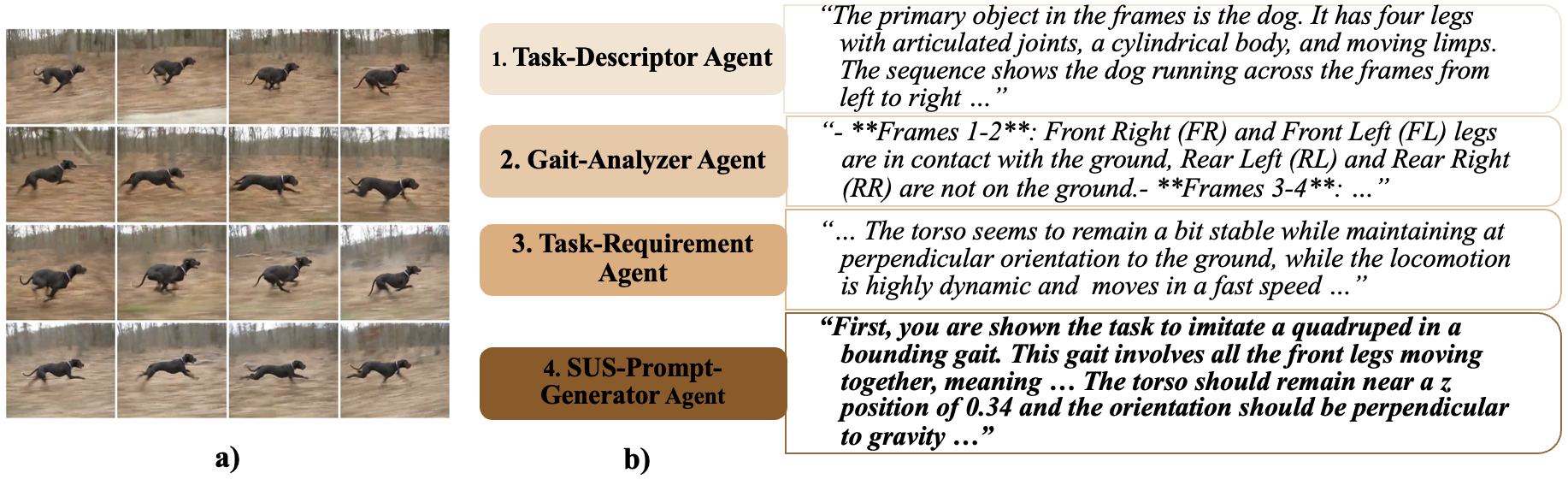
技术框架:SDS的整体框架包含以下几个主要阶段:1) 视频编码:使用时空网格视觉编码($G_{v}$)将视频帧转换为LLM可理解的视觉特征表示。2) 结构化输入分解(SUS):将复杂的视频信息分解为更易于处理的结构化输入,例如关键帧序列。3) 奖励函数生成:利用GPT-4o,基于编码后的视频信息和结构化输入,生成可执行的奖励函数。4) 策略训练:使用PPO等强化学习算法,利用生成的奖励函数训练机器人控制策略。5) 闭环优化:使用训练视频和性能指标作为自监督信号,通过闭环进化优化奖励函数和策略。
关键创新:SDS的关键创新在于利用LLM自动生成奖励函数,从而避免了人工设计奖励函数的复杂性和主观性。此外,时空网格视觉编码和结构化输入分解技术,使得LLM能够更好地理解视频信息,生成更有效的奖励函数。
关键设计:在视频编码方面,使用了时空网格将视频帧划分为多个区域,并提取每个区域的视觉特征。在奖励函数生成方面,设计了特定的提示语,引导GPT-4o生成与目标运动技能相对应的奖励函数,例如,鼓励机器人模仿视频中的运动轨迹和姿态。PPO算法使用了默认的参数设置,并根据具体任务进行了微调。
🖼️ 关键图片

📊 实验亮点
SDS在Unitree Go1和ANYmal等四足机器人上成功学习了四种步态(小跑、奔跑、慢步和跳跃),实现了100%的步态匹配保真度,动态时间规整(DTW)距离达到$10^{-6}$量级,并在模拟和真实环境中实现了零失败的稳定运动。SDS在数据效率、训练时间和工程工作量方面均优于先前的工作。
🎯 应用场景
SDS技术具有广泛的应用前景,可用于快速开发各种四足机器人的运动技能,例如搜救、巡检、物流等。通过从人类演示视频中学习,机器人可以更容易地适应复杂和动态的环境,提高其自主性和适应性。该技术还可以应用于其他类型的机器人,例如人形机器人和机械臂,实现更智能和灵活的自动化。
📄 摘要(原文)
Imagine a robot learning locomotion skills from any single video, without labels or reward engineering. We introduce SDS ("See it. Do it. Sorted."), an automated pipeline for skill acquisition from unstructured demonstrations. Using GPT-4o, SDS applies novel prompting techniques, in the form of spatio-temporal grid-based visual encoding ($G_{v}$) and structured input decomposition (SUS). These produce executable reward functions (RF) from the raw input videos. The RFs are used to train PPO policies and are optimized through closed-loop evolution, using training footage and performance metrics as self-supervised signals. SDS allows quadrupeds (e.g. Unitree Go1) to learn four gaits -- trot, bound, pace, and hop -- achieving 100% gait matching fidelity, Dynamic Time Warping (DTW) distance in the order of $10^{-6}$, and stable locomotion with zero failures, both in simulation and the real world. SDS generalizes to morphologically different quadrupeds (e.g. ANYmal) and outperforms prior work in data efficiency, training time and engineering effort. Further materials and the code are open-source under: https://rpl-cs-ucl.github.io/SDSweb/.