PAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
作者: Shang-Ching Liu, Van Nhiem Tran, Wenkai Chen, Wei-Lun Cheng, Yen-Lin Huang, I-Bin Liao, Yung-Hui Li, Jianwei Zhang
分类: cs.RO, cs.CV
发布日期: 2024-10-15 (更新: 2025-07-06)
💡 一句话要点
PAVLM:利用视觉语言模型提升点云的Affordance理解
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Affordance理解 点云处理 视觉语言模型 机器人操作 几何深度学习
📋 核心要点
- 现有视觉语言模型在理解机器人交互所需的物理属性方面存在不足,限制了其在Affordance理解任务中的应用。
- PAVLM通过几何引导传播模块和LLM嵌入,增强视觉语义,并利用Llama-3.1生成上下文感知文本,提升指令输入的语义深度。
- 实验表明,PAVLM在3D-AffordanceNet基准测试中,对完整和部分点云的Affordance理解均优于现有方法,泛化能力更强。
📝 摘要(中文)
Affordance理解,即识别3D物体上可交互区域的任务,对于机器人与物理世界交互至关重要。尽管视觉语言模型(VLM)在机器人操作的高级推理和长程规划方面表现出色,但在理解有效人机交互所需的细微物理属性方面仍有不足。本文提出了PAVLM(Point cloud Affordance Vision-Language Model),这是一个创新框架,它利用预训练语言模型中嵌入的大量多模态知识来增强点云的3D affordance理解。PAVLM集成了几何引导的传播模块与大型语言模型(LLM)的隐藏嵌入,以丰富视觉语义。在语言方面,我们提示Llama-3.1模型生成更精细的上下文感知文本,从而利用更深层次的语义线索来增强指令输入。在3D-AffordanceNet基准上的实验结果表明,PAVLM在完整和部分点云方面均优于基线方法,尤其是在推广到新的开放世界3D物体affordance任务方面表现出色。更多信息请访问我们的项目网站:pavlm-source.github.io。
🔬 方法详解
问题定义:论文旨在解决3D点云Affordance理解问题,即识别3D物体上可交互的区域。现有方法,特别是基于视觉语言模型的方法,在理解细微的物理属性和泛化到新的开放世界场景时存在不足。这些方法通常难以充分利用点云的几何信息,并且在处理上下文语义方面不够深入。
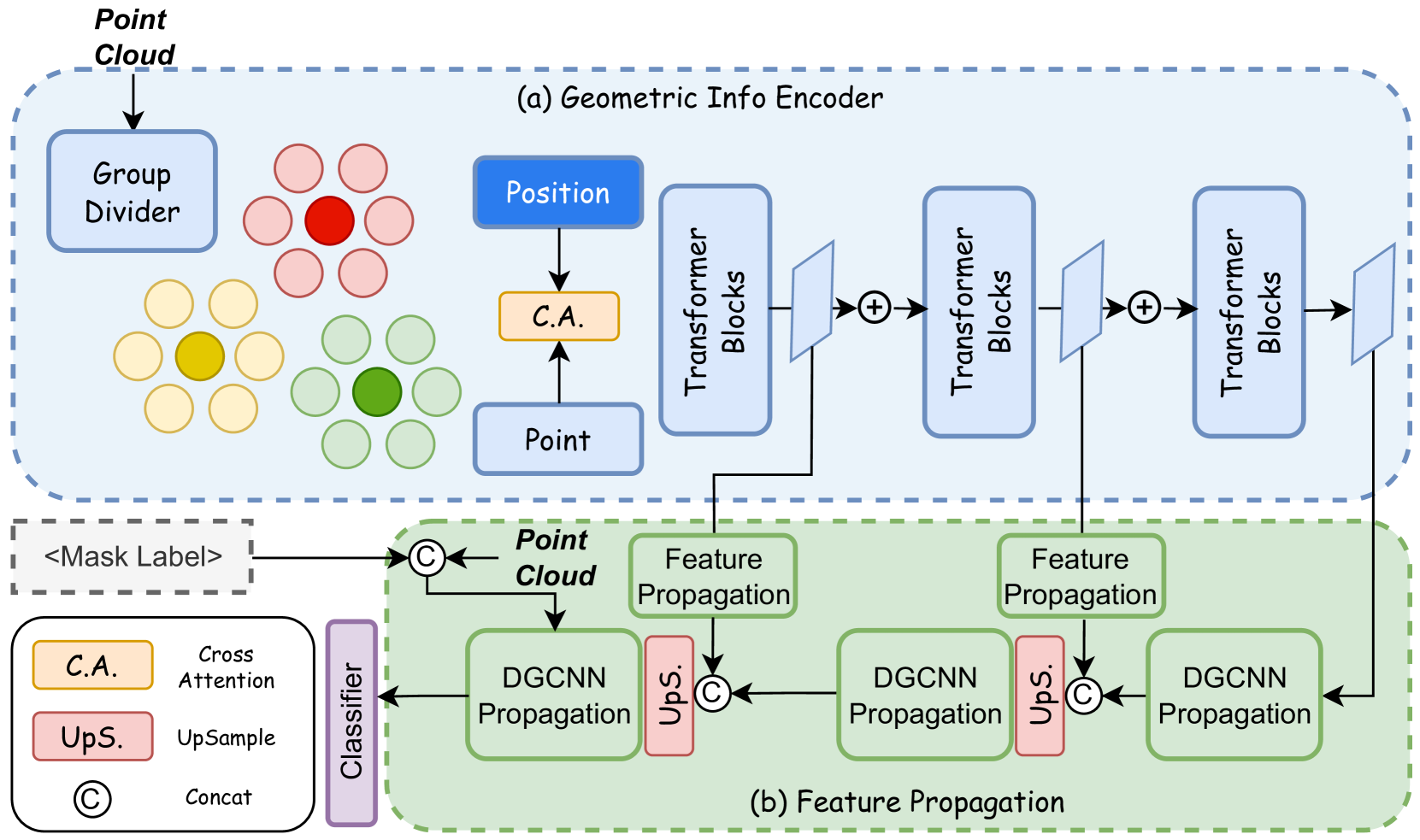
核心思路:论文的核心思路是融合几何信息和大型语言模型的语义知识,从而提升点云Affordance理解的性能。通过几何引导的传播模块,将局部几何特征传播到整个点云,增强视觉语义。同时,利用大型语言模型生成上下文感知的文本描述,为Affordance理解提供更丰富的语义信息。
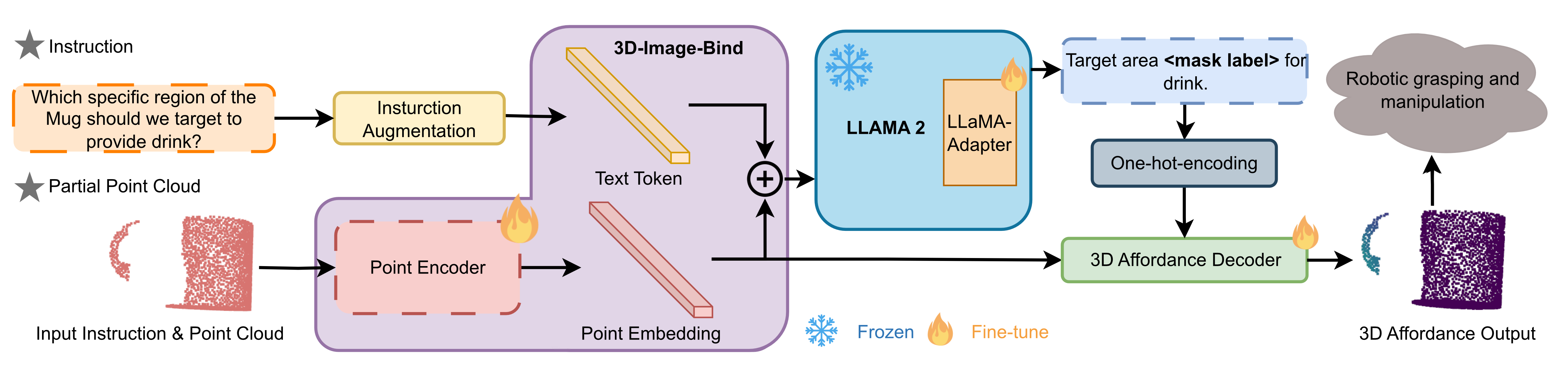
技术框架:PAVLM框架主要包含两个部分:视觉部分和语言部分。视觉部分首先利用几何引导的传播模块提取点云的几何特征,并将其与大型语言模型的隐藏嵌入相结合,从而增强视觉语义。语言部分则利用Llama-3.1模型生成上下文感知的文本描述,为Affordance理解提供更丰富的语义信息。最终,将视觉和语言信息融合,用于预测点云的Affordance。
关键创新:论文的关键创新在于将几何引导的传播模块与大型语言模型相结合,从而有效地利用了点云的几何信息和语言模型的语义知识。这种融合方式能够提升点云Affordance理解的性能,并增强模型的泛化能力。此外,利用Llama-3.1模型生成上下文感知的文本描述也是一个创新点,它能够为Affordance理解提供更丰富的语义信息。
关键设计:几何引导的传播模块的具体实现方式未知,论文中可能没有详细描述。Llama-3.1模型的prompt设计是关键,需要根据具体的Affordance任务进行调整,以生成合适的上下文感知文本。损失函数的设计也至关重要,需要能够有效地衡量预测的Affordance与真实Affordance之间的差异。
🖼️ 关键图片

📊 实验亮点
PAVLM在3D-AffordanceNet基准测试中取得了显著的性能提升,尤其是在泛化到新的开放世界3D物体Affordance任务方面表现出色。具体性能数据和对比基线方法的提升幅度未知,需要在论文中查找更详细的实验结果。
🎯 应用场景
该研究成果可应用于机器人操作、人机交互、智能制造等领域。例如,机器人可以利用Affordance理解技术,自主地识别物体上的可交互区域,从而完成抓取、放置、组装等任务。在人机交互方面,该技术可以帮助机器人更好地理解人类的指令,并做出相应的动作。在智能制造领域,该技术可以用于自动化生产线的优化和改进。
📄 摘要(原文)
Affordance understanding, the task of identifying actionable regions on 3D objects, plays a vital role in allowing robotic systems to engage with and operate within the physical world. Although Visual Language Models (VLMs) have excelled in high-level reasoning and long-horizon planning for robotic manipulation, they still fall short in grasping the nuanced physical properties required for effective human-robot interaction. In this paper, we introduce PAVLM (Point cloud Affordance Vision-Language Model), an innovative framework that utilizes the extensive multimodal knowledge embedded in pre-trained language models to enhance 3D affordance understanding of point cloud. PAVLM integrates a geometric-guided propagation module with hidden embeddings from large language models (LLMs) to enrich visual semantics. On the language side, we prompt Llama-3.1 models to generate refined context-aware text, augmenting the instructional input with deeper semantic cues. Experimental results on the 3D-AffordanceNet benchmark demonstrate that PAVLM outperforms baseline methods for both full and partial point clouds, particularly excelling in its generalization to novel open-world affordance tasks of 3D objects. For more information, visit our project site: pavlm-source.github.io.