Reinforcement Learning For Quadrupedal Locomotion: Current Advancements And Future Perspectives
作者: Maurya Gurram, Prakash Kumar Uttam, Shantipal S. Ohol
分类: cs.RO
发布日期: 2024-10-14
备注: 12 pages, 3 figures
💡 一句话要点
综述:基于强化学习的四足机器人运动控制研究进展与未来展望
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 运动控制 步态规划 深度学习
📋 核心要点
- 传统四足机器人控制方法在复杂环境下的适应性和泛化能力不足,难以应对未知地形和干扰。
- 论文综述了基于强化学习的四足机器人运动控制方法,涵盖算法、训练策略、奖励函数和迁移学习等关键技术。
- 该研究旨在为研究人员提供全面的技术理解,促进四足机器人运动控制在现实场景中的应用和发展。
📝 摘要(中文)
近年来,基于强化学习(RL)的四足机器人运动控制已成为一个广泛研究的领域,这得益于其相比传统控制方法在自主学习和适应方面的潜在优势。本文全面研究了应用RL技术开发四足机器人运动控制器的最新研究成果。我们详细概述了基于RL的运动控制器的核心概念、方法和关键进展,包括学习算法、训练课程、奖励函数设计以及从仿真到真实的迁移技术。该研究涵盖了步态约束和无步态方法,突出了它们各自的优势和局限性。此外,我们还讨论了这些控制器与机器人硬件的集成以及传感器反馈在实现自适应行为中的作用。本文还概述了未来的研究方向,例如结合外部感知、结合基于模型和无模型技术以及开发在线学习能力。我们的研究旨在为研究人员和从业人员提供对基于RL的运动控制器的最新技术的全面理解,使他们能够在现有工作的基础上构建,并探索新的解决方案,以增强四足机器人在现实环境中的移动性和适应性。
🔬 方法详解
问题定义:四足机器人在复杂和动态环境中实现鲁棒和高效的运动控制是一个具有挑战性的问题。传统的控制方法通常依赖于精确的机器人模型和环境信息,难以适应未知或变化的条件。此外,手工设计控制策略需要大量的领域知识和人工调整,效率较低。因此,如何使四足机器人能够自主学习并适应各种环境,实现灵活的运动控制,是一个亟待解决的问题。
核心思路:论文的核心思路是利用强化学习(RL)算法,通过与环境的交互,使四足机器人能够自主学习最优的运动控制策略。强化学习不需要精确的机器人模型和环境信息,可以通过试错的方式,学习到适应各种环境的控制策略。此外,强化学习可以自动优化控制策略,无需人工干预,提高了控制策略的开发效率。
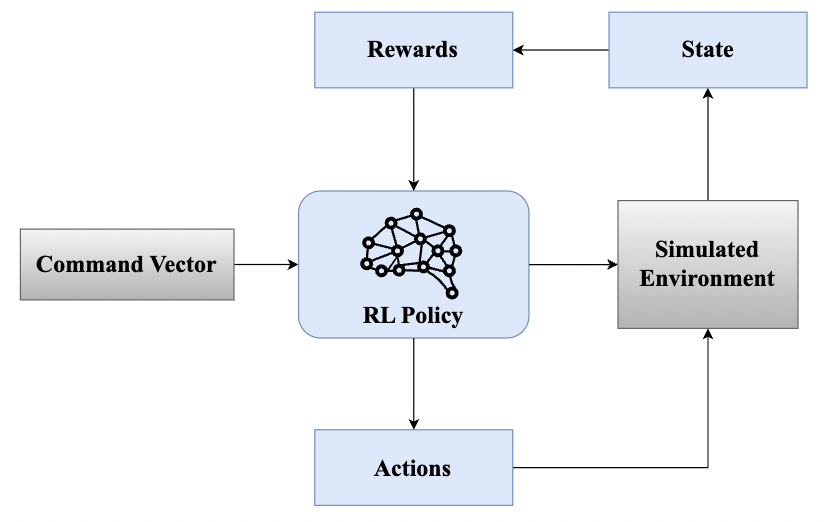
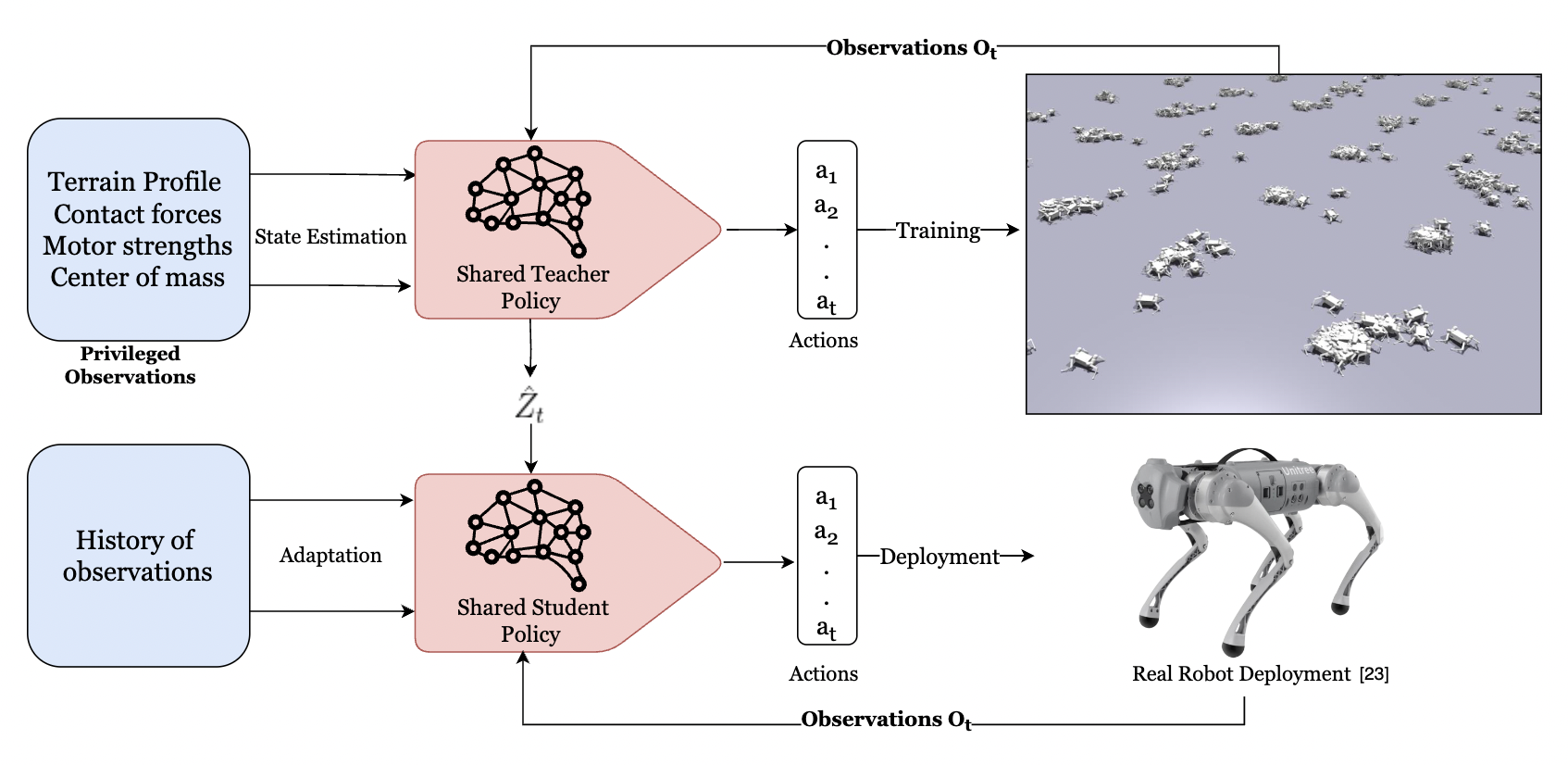
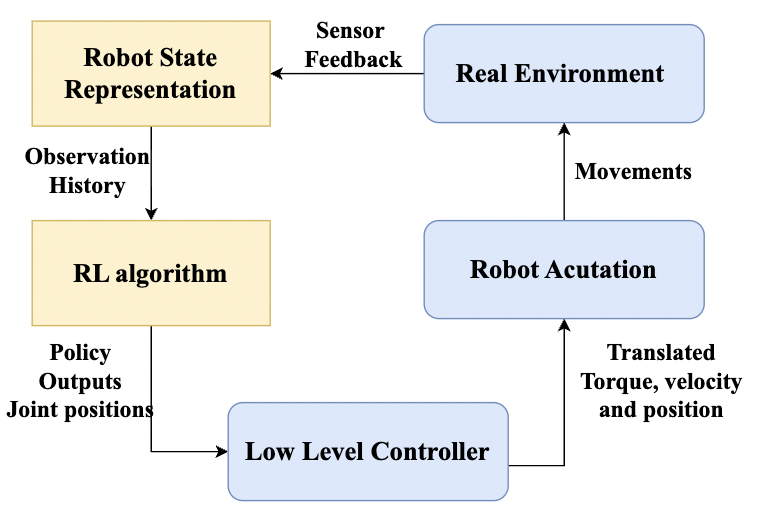
技术框架:该综述涵盖了基于RL的四足机器人运动控制的各个方面,包括:1) 学习算法:介绍了常用的RL算法,如深度Q网络(DQN)、策略梯度算法(如PPO、TRPO)等。2) 训练课程:讨论了如何设计有效的训练课程,以加速学习过程并提高控制策略的泛化能力。3) 奖励函数设计:分析了奖励函数对学习结果的影响,并介绍了常用的奖励函数设计方法。4) 仿真到真实的迁移技术:讨论了如何将仿真环境中学习到的控制策略迁移到真实的机器人上,以解决仿真环境与真实环境之间的差异。
关键创新:该综述的关键创新在于对基于RL的四足机器人运动控制领域的最新研究成果进行了全面的总结和分析。它不仅介绍了各种RL算法在四足机器人运动控制中的应用,还讨论了训练课程设计、奖励函数设计以及仿真到真实的迁移等关键技术。此外,该综述还指出了该领域未来的研究方向,例如结合外部感知、结合基于模型和无模型技术以及开发在线学习能力。
关键设计:在奖励函数设计方面,通常会考虑机器人的前进速度、稳定性、能量消耗等因素。例如,可以设计一个奖励函数,鼓励机器人向前移动,同时惩罚机器人的摔倒和能量消耗。在网络结构方面,通常使用深度神经网络来表示控制策略,例如,可以使用多层感知机(MLP)或循环神经网络(RNN)来处理传感器数据并输出控制指令。在训练过程中,通常使用各种技巧来提高学习效率和稳定性,例如,使用经验回放(Experience Replay)来存储和重用过去的经验,使用目标网络(Target Network)来稳定Q值的估计。
🖼️ 关键图片
📊 实验亮点
该综述总结了近年来基于强化学习的四足机器人运动控制的最新进展,涵盖了多种学习算法、训练策略和奖励函数设计。通过对比不同方法的优缺点,为研究人员提供了有价值的参考。此外,该综述还指出了未来研究方向,例如结合外部感知和开发在线学习能力,为该领域的发展提供了指导。
🎯 应用场景
该研究成果可应用于搜救、勘探、物流等领域。四足机器人能够在复杂地形和恶劣环境下自主行走,完成各种任务,例如在地震灾区搜寻幸存者,在矿山勘探矿产资源,在仓库或工厂进行货物搬运。此外,该研究还可以促进机器人技术的发展,为其他类型的机器人提供借鉴。
📄 摘要(原文)
In recent years, reinforcement learning (RL) based quadrupedal locomotion control has emerged as an extensively researched field, driven by the potential advantages of autonomous learning and adaptation compared to traditional control methods. This paper provides a comprehensive study of the latest research in applying RL techniques to develop locomotion controllers for quadrupedal robots. We present a detailed overview of the core concepts, methodologies, and key advancements in RL-based locomotion controllers, including learning algorithms, training curricula, reward formulations, and simulation-to-real transfer techniques. The study covers both gait-bound and gait-free approaches, highlighting their respective strengths and limitations. Additionally, we discuss the integration of these controllers with robotic hardware and the role of sensor feedback in enabling adaptive behavior. The paper also outlines future research directions, such as incorporating exteroceptive sensing, combining model-based and model-free techniques, and developing online learning capabilities. Our study aims to provide researchers and practitioners with a comprehensive understanding of the state-of-the-art in RL-based locomotion controllers, enabling them to build upon existing work and explore novel solutions for enhancing the mobility and adaptability of quadrupedal robots in real-world environments.