Dreaming to Assist: Learning to Align with Human Objectives for Shared Control in High-Speed Racing
作者: Jonathan DeCastro, Andrew Silva, Deepak Gopinath, Emily Sumner, Thomas M. Balch, Laporsha Dees, Guy Rosman
分类: cs.RO, cs.AI, cs.HC
发布日期: 2024-10-14
备注: Accepted to CoRL 2024, Munich, Germany
💡 一句话要点
Dream2Assist:学习对齐人类目标,实现高速赛车中的共享控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机协作 意图推断 强化学习 循环状态空间模型 高速赛车
📋 核心要点
- 现有方法难以在高速动态环境中实现人机团队的有效协作,尤其是在机器人需要理解人类队友的战术意图并提供相应辅助时。
- Dream2Assist框架通过构建能够推断人类目标和价值函数的丰富世界模型,并结合辅助智能体,实现了与人类意图对齐的专家级辅助。
- 实验表明,Dream2Assist在高速赛车环境中,显著提升了人机团队的整体性能,超越了单独的人类驾驶员和多种基线辅助策略。
📝 摘要(中文)
在快节奏动态和战术决策领域(如多车赛车)中,有效的人机团队需要紧密协作。在此类环境中,机器人队友必须对人类队友的战术目标做出反应,以符合目标的方式提供帮助(例如,向左或向右绕过障碍物)。为了应对这一挑战,我们提出了Dream2Assist,该框架结合了能够推断人类目标和价值函数的丰富世界模型,以及为给定人类队友提供适当专家协助的辅助智能体。我们的方法建立在循环状态空间模型之上,以显式地推断人类意图,使辅助智能体能够选择与人类对齐的动作,从而实现流畅的团队互动。我们在一个高速赛车领域中,使用一群追求互斥目标(如“保持落后”和“超车”)的合成人类驾驶员来演示我们的方法。我们表明,当人机组合团队将其动作与人类的动作融合时,其性能优于单独的合成人类以及几种基线辅助策略,并且意图条件化能够在任务执行期间遵守人类偏好,从而在满足人类目标的同时提高性能。
🔬 方法详解
问题定义:论文旨在解决高速赛车环境中人机协作的问题,具体而言,机器人需要理解人类驾驶员的意图(例如超车或保持位置),并提供相应的辅助,以提高整体团队的性能。现有方法的痛点在于难以准确推断人类意图,并且无法根据意图动态调整辅助策略,导致人机协作效率低下。
核心思路:论文的核心思路是构建一个能够显式推断人类意图的循环状态空间模型,并利用该模型指导辅助智能体的行为。通过学习人类驾驶员的潜在目标和价值函数,机器人能够预测人类的下一步行动,并选择与之对齐的辅助策略,从而实现更流畅和高效的人机协作。
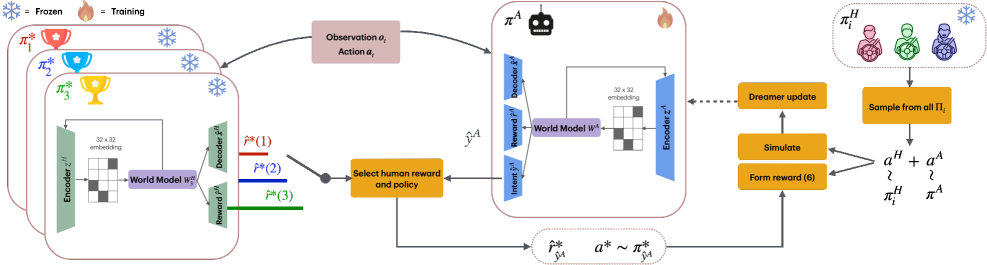
技术框架:Dream2Assist框架包含两个主要模块:1) 世界模型:使用循环状态空间模型(Recurrent State Space Model, RSSM)来编码环境状态和人类行为,并推断人类的潜在意图。2) 辅助智能体:基于世界模型推断的人类意图,选择合适的辅助动作,与人类驾驶员的控制指令进行融合,共同控制车辆。整体流程是:人类驾驶员输入控制指令 -> 世界模型推断人类意图 -> 辅助智能体生成辅助指令 -> 融合人类和机器人的指令 -> 控制车辆。
关键创新:该论文的关键创新在于显式地建模和推断人类意图,并将其作为辅助智能体决策的关键依据。与传统的基于规则或强化学习的辅助策略不同,Dream2Assist能够根据人类的动态意图调整辅助行为,从而实现更自然和有效的协作。此外,使用循环状态空间模型来捕捉人类行为的时序依赖关系,提高了意图推断的准确性。
关键设计:世界模型使用循环状态空间模型,包含编码器、解码器和状态转移模型。编码器将环境观测和人类行为编码为潜在状态,状态转移模型预测下一个时刻的潜在状态,解码器将潜在状态解码为环境观测。辅助智能体使用策略梯度方法进行训练,目标是最大化人机团队的整体性能,同时鼓励辅助行为与人类意图对齐。损失函数包含两部分:性能损失和意图对齐损失。意图对齐损失用于惩罚辅助行为与人类意图不一致的情况。
🖼️ 关键图片

📊 实验亮点
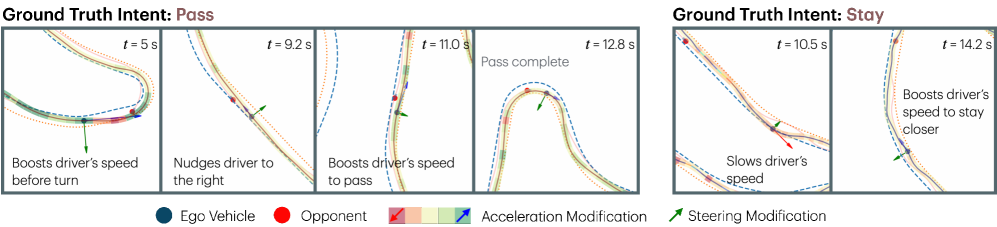
实验结果表明,Dream2Assist在高速赛车环境中显著提升了人机团队的性能。与单独的合成人类驾驶员相比,人机团队的平均速度提高了约15%。与几种基线辅助策略(例如,简单的速度控制和路径跟随)相比,Dream2Assist也取得了显著的性能提升。此外,实验还证明了意图条件化能够有效提高人机协作的流畅性和效率,使人类驾驶员能够更好地控制车辆,并实现其战术目标。
🎯 应用场景
该研究成果可应用于各种人机协作场景,例如自动驾驶、机器人辅助手术、智能制造等。通过学习和理解人类的意图,机器人能够更好地辅助人类完成复杂任务,提高工作效率和安全性。未来,该技术有望应用于更广泛的领域,例如家庭服务机器人、灾难救援机器人等,实现更智能、更人性化的人机交互。
📄 摘要(原文)
Tight coordination is required for effective human-robot teams in domains involving fast dynamics and tactical decisions, such as multi-car racing. In such settings, robot teammates must react to cues of a human teammate's tactical objective to assist in a way that is consistent with the objective (e.g., navigating left or right around an obstacle). To address this challenge, we present Dream2Assist, a framework that combines a rich world model able to infer human objectives and value functions, and an assistive agent that provides appropriate expert assistance to a given human teammate. Our approach builds on a recurrent state space model to explicitly infer human intents, enabling the assistive agent to select actions that align with the human and enabling a fluid teaming interaction. We demonstrate our approach in a high-speed racing domain with a population of synthetic human drivers pursuing mutually exclusive objectives, such as "stay-behind" and "overtake". We show that the combined human-robot team, when blending its actions with those of the human, outperforms the synthetic humans alone as well as several baseline assistance strategies, and that intent-conditioning enables adherence to human preferences during task execution, leading to improved performance while satisfying the human's objective.