ImagineNav: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination
作者: Xinxin Zhao, Wenzhe Cai, Likun Tang, Teng Wang
分类: cs.RO
发布日期: 2024-10-13
备注: 17 pages, 9 figures
💡 一句话要点
ImagineNav:通过场景想象提示视觉-语言模型作为具身导航器
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉导航 视觉-语言模型 具身智能 场景想象 机器人
📋 核心要点
- 现有方法依赖LLM进行导航规划,但LLM难以有效处理空间信息,限制了导航决策的合理性。
- ImagineNav框架利用VLM的空间感知能力,通过想象未来视角图像,将导航规划转化为最佳视角选择问题。
- 实验表明,ImagineNav在开放词汇对象导航任务中表现出色,验证了其有效性和优越性。
📝 摘要(中文)
视觉导航是家庭辅助机器人的关键技能,它提供了物体搜索能力以完成长时程的日常任务。许多最近的方法使用大型语言模型(LLM)进行常识推理,以提高探索效率。然而,LLM的规划过程仅限于文本,难以仅通过文本表示空间占用和几何布局。这两者对于做出合理的导航决策至关重要。在这项工作中,我们试图释放视觉-语言模型(VLM)的空间感知和规划能力,并探索仅使用机载摄像头捕获的RGB/RGB-D流输入,VLM是否能够以无地图的方式高效地完成视觉导航任务。我们通过开发基于想象的导航框架ImagineNav来实现这一点,该框架想象未来在有价值的机器人视角的观察图像,并将复杂的导航规划过程转化为VLM更喜欢的最佳视角图像选择问题。为了生成适合想象的候选机器人视角,我们引入了Where2Imagine模块,该模块被提炼以与人类导航习惯保持一致。最后,为了达到VLM首选的视角,利用现成的点目标导航策略。在具有挑战性的开放词汇对象导航基准上的实证实验证明了我们提出的系统的优越性。
🔬 方法详解
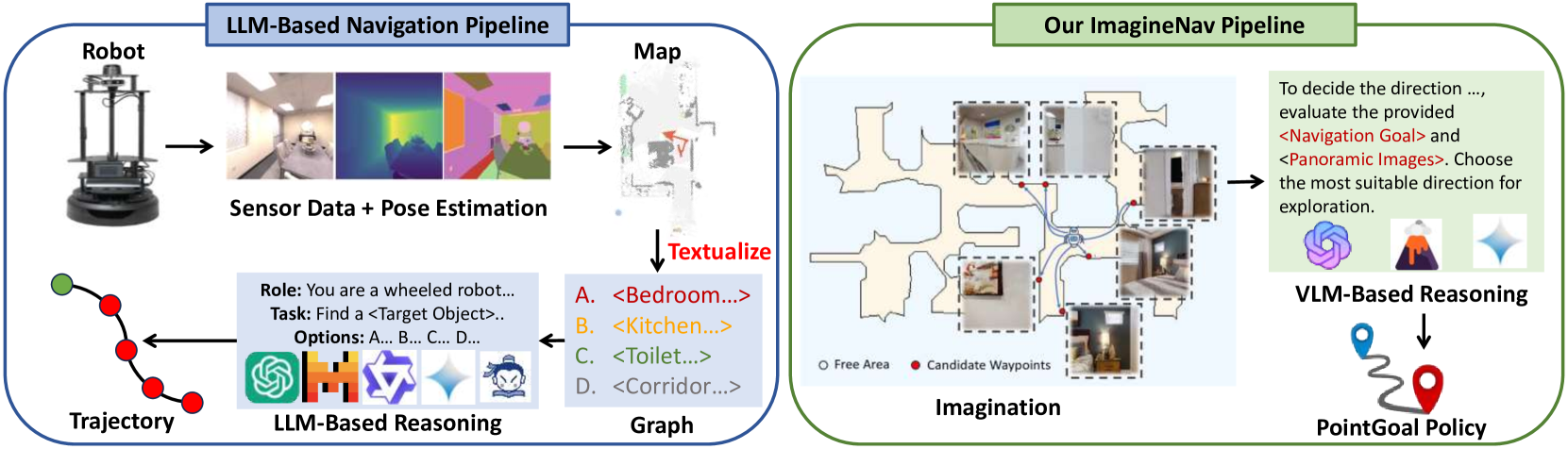
问题定义:现有基于LLM的视觉导航方法在处理空间信息方面存在局限性,难以准确表示环境的空间占用和几何布局,导致导航决策不够合理。这些方法主要依赖文本进行规划,无法充分利用视觉信息中蕴含的空间线索。
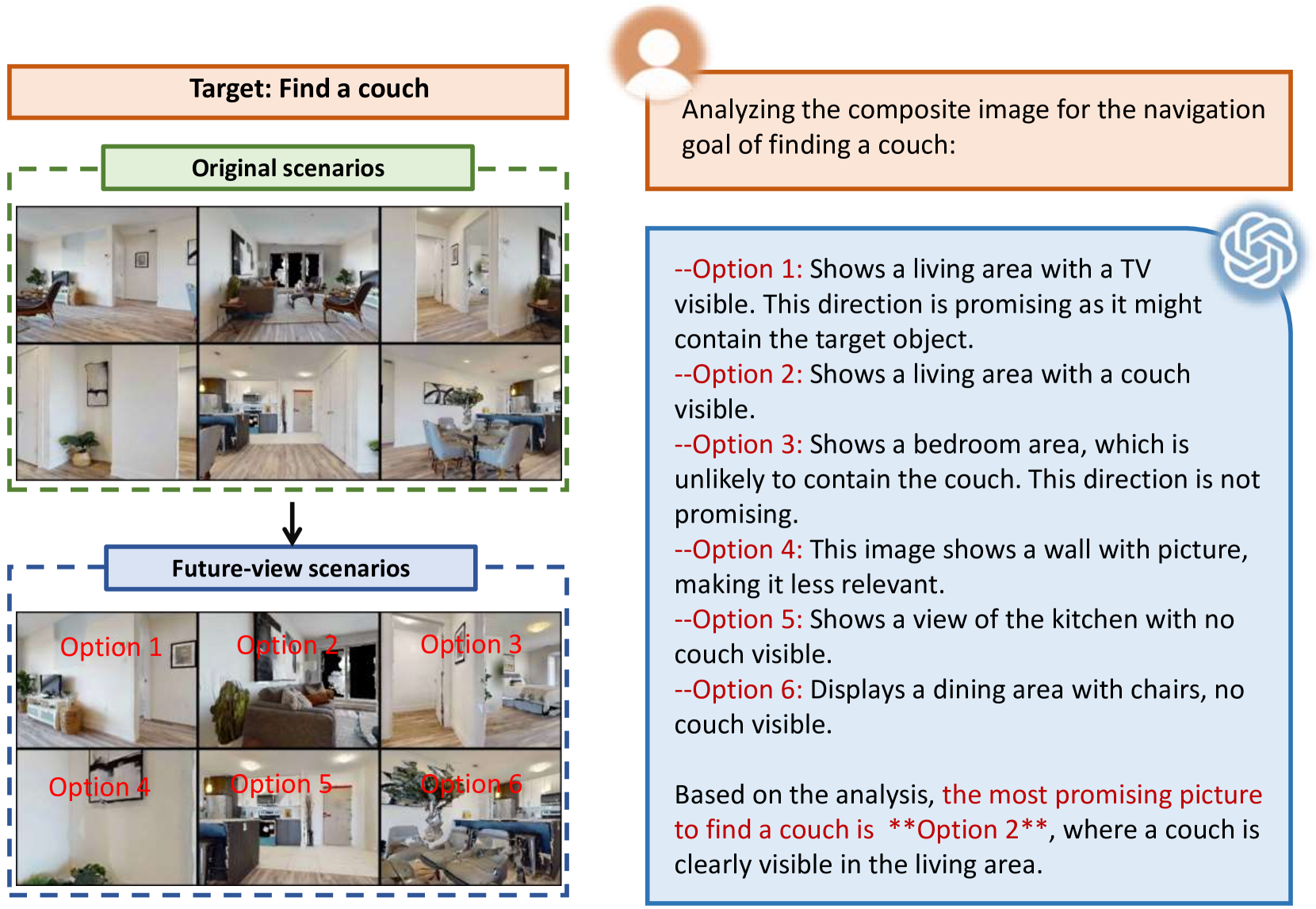
核心思路:ImagineNav的核心思路是利用视觉-语言模型(VLM)强大的视觉感知和推理能力,通过“想象”未来可能的机器人视角,将复杂的导航规划问题转化为一个更简单的最佳视角选择问题。VLM更擅长处理图像信息,因此选择最符合导航目标的“想象”视角,可以更有效地引导机器人行动。
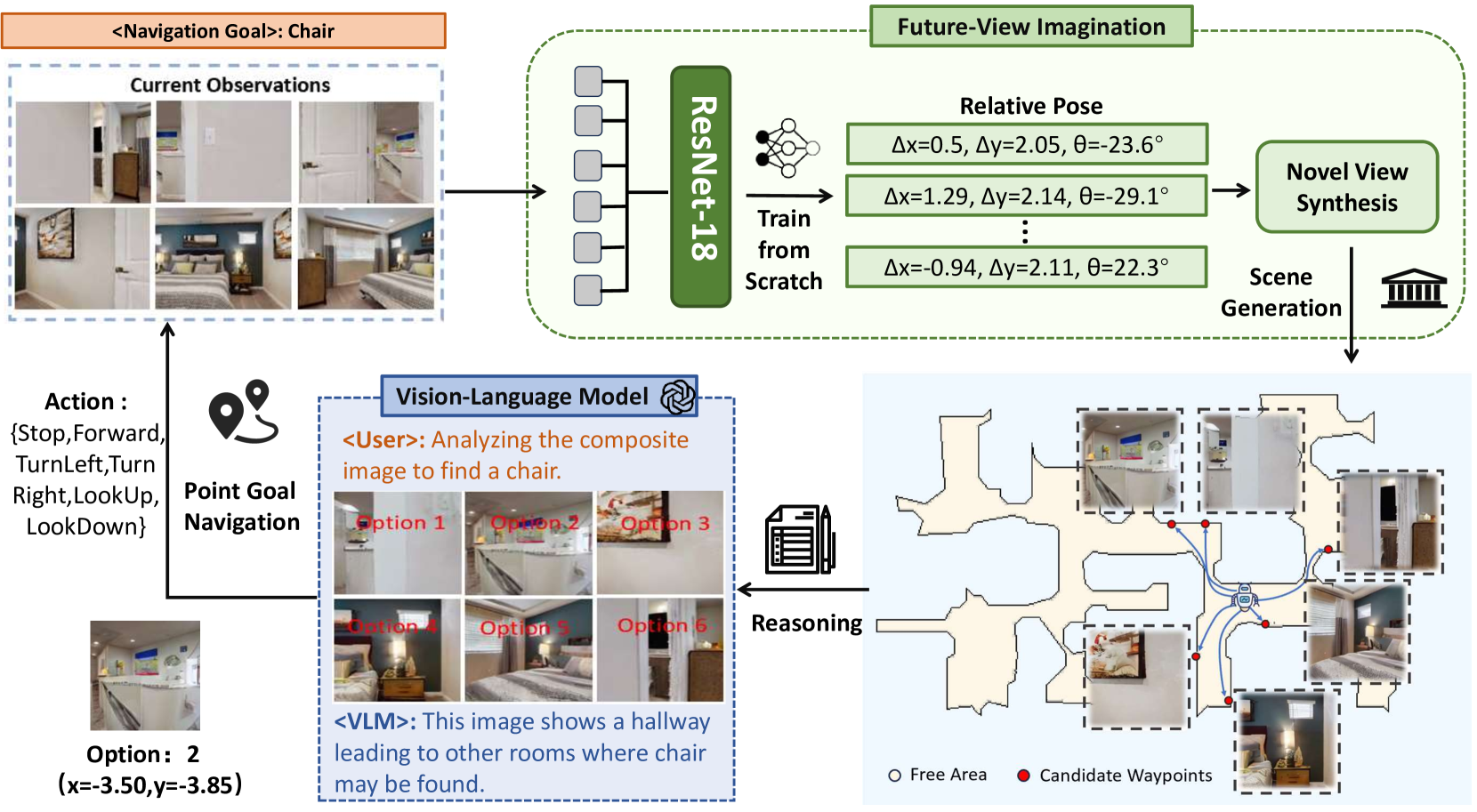
技术框架:ImagineNav框架包含以下几个主要模块:1) Where2Imagine模块:负责生成候选的机器人视角,该模块通过蒸馏学习,模仿人类的导航习惯,选择更有价值的视角进行想象。2) VLM视角选择:VLM对每个候选视角进行评估,选择最符合导航目标的视角。3) 点目标导航策略:利用现成的点目标导航策略,驱动机器人移动到VLM选择的最佳视角。整体流程是,Where2Imagine生成候选视角,VLM选择最佳视角,然后点目标导航策略执行移动,循环迭代直至到达目标。
关键创新:ImagineNav的关键创新在于将导航规划问题转化为VLM擅长的图像选择问题。通过引入“想象”的概念,充分利用了VLM的视觉感知能力,避免了直接使用LLM进行空间推理的局限性。Where2Imagine模块通过模仿人类导航习惯,提高了候选视角的质量,使得VLM能够更有效地进行选择。
关键设计:Where2Imagine模块的设计至关重要,它需要学习人类在导航过程中的视角选择偏好。具体实现方式未知,可能涉及到模仿学习或强化学习等方法。VLM的选择标准也需要仔细设计,以确保选择的视角能够有效地引导机器人到达目标。点目标导航策略的选择也需要考虑机器人的运动能力和环境的复杂性。
🖼️ 关键图片
📊 实验亮点
论文在开放词汇对象导航基准上进行了实验,结果表明ImagineNav显著优于现有方法。具体的性能数据未知,但摘要中明确指出该系统表现出了“优越性”。通过想象未来视角,ImagineNav能够更有效地进行导航规划,从而提高了导航效率和成功率。
🎯 应用场景
ImagineNav具有广泛的应用前景,可用于家庭服务机器人、仓库物流机器人、自动驾驶等领域。它可以帮助机器人在复杂环境中自主导航,完成物体搜索、路径规划等任务。该研究的突破在于利用VLM的空间感知能力,有望提升机器人的智能化水平和自主性。
📄 摘要(原文)
Visual navigation is an essential skill for home-assistance robots, providing the object-searching ability to accomplish long-horizon daily tasks. Many recent approaches use Large Language Models (LLMs) for commonsense inference to improve exploration efficiency. However, the planning process of LLMs is limited within texts and it is difficult to represent the spatial occupancy and geometry layout only by texts. Both are important for making rational navigation decisions. In this work, we seek to unleash the spatial perception and planning ability of Vision-Language Models (VLMs), and explore whether the VLM, with only on-board camera captured RGB/RGB-D stream inputs, can efficiently finish the visual navigation tasks in a mapless manner. We achieve this by developing the imagination-powered navigation framework ImagineNav, which imagines the future observation images at valuable robot views and translates the complex navigation planning process into a rather simple best-view image selection problem for VLM. To generate appropriate candidate robot views for imagination, we introduce the Where2Imagine module, which is distilled to align with human navigation habits. Finally, to reach the VLM preferred views, an off-the-shelf point-goal navigation policy is utilized. Empirical experiments on the challenging open-vocabulary object navigation benchmarks demonstrates the superiority of our proposed system.