FRASA: An End-to-End Reinforcement Learning Agent for Fall Recovery and Stand Up of Humanoid Robots
作者: Clément Gaspard, Marc Duclusaud, Grégoire Passault, Mélodie Daniel, Olivier Ly
分类: cs.RO
发布日期: 2024-10-11 (更新: 2025-11-04)
💡 一句话要点
提出FRASA,用于人形机器人跌倒恢复和站立的端到端强化学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 跌倒恢复 运动控制 Cross-Q算法
📋 核心要点
- 传统人形机器人跌倒恢复方法依赖人工调整或缺乏适应性,难以应对复杂环境。
- FRASA采用深度强化学习,通过Cross-Q算法加速训练,实现统一的跌倒恢复和站立策略。
- 实验表明,FRASA在Sigmaban机器人上优于RoboCup冠军队伍使用的KFB方法,展现更强鲁棒性。
📝 摘要(中文)
人形机器人在动态环境中实现稳定运动和从跌倒中恢复面临重大挑战。 传统的模型预测控制(MPC)和基于关键帧(KFB)的例程,要么需要大量的精细调整,要么缺乏实时适应性。 本文介绍了一种深度强化学习(DRL)智能体FRASA,它将跌倒恢复和站立策略集成到一个统一的框架中。 FRASA利用Cross-Q算法,显著减少了训练时间,并提供了一种通用的恢复策略,可以适应不可预测的扰动。 在Sigmaban人形机器人上的对比测试表明,FRASA的性能优于Rhoban团队在RoboCup 2023(KidSize League世界冠军)中部署的KFB方法。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂动态环境中跌倒后快速、稳定站立的问题。现有方法,如MPC和KFB,存在需要大量人工调参或难以适应未知扰动的局限性,导致泛化能力不足。
核心思路:论文的核心在于利用深度强化学习(DRL)直接从环境中学习跌倒恢复和站立策略,避免了人工设计规则的复杂性。通过奖励函数引导机器人学习最优的动作序列,使其能够适应各种跌倒姿态和外部干扰。
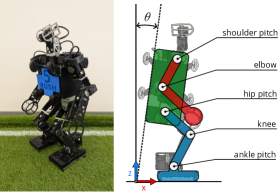
技术框架:FRASA是一个端到端的强化学习智能体,主要包含以下几个部分:1) 状态空间定义:描述机器人当前的状态,包括关节角度、角速度、姿态等信息。2) 动作空间定义:机器人可以执行的动作,例如关节力矩控制。3) 奖励函数设计:用于评估机器人行为的优劣,鼓励快速站立和保持平衡。4) 强化学习算法:使用Cross-Q算法进行训练,加速收敛并提高稳定性。5) 神经网络结构:用于近似Q函数,将状态映射到动作价值。
关键创新:FRASA的关键创新在于将跌倒恢复和站立问题建模为一个统一的强化学习任务,并利用Cross-Q算法加速训练。与传统的基于规则或优化的方法相比,FRASA能够自动学习适应复杂环境的策略,具有更强的泛化能力和鲁棒性。
关键设计:论文中Cross-Q算法的选择是关键设计之一,它通过同时训练多个Q函数来减少过估计,提高训练的稳定性。奖励函数的设计也至关重要,需要仔细平衡各项指标,例如站立速度、平衡性和能量消耗。此外,神经网络的结构和参数也需要根据具体任务进行调整,以获得最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FRASA在跌倒恢复和站立任务中显著优于RoboCup 2023 KidSize League冠军队伍Rhoban Team使用的KFB方法。具体而言,FRASA能够更快地站立,并且对外部扰动的鲁棒性更强。这些结果验证了FRASA的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种人形机器人平台,提升其在复杂环境中的自主性和适应性。例如,在搜救、巡检、医疗等领域,机器人能够更好地应对突发情况,完成任务。此外,该方法也可推广到其他类型的机器人,如四足机器人和轮式机器人,提高其运动控制能力。
📄 摘要(原文)
Humanoid robotics faces significant challenges in achieving stable locomotion and recovering from falls in dynamic environments. Traditional methods, such as Model Predictive Control (MPC) and Key Frame Based (KFB) routines, either require extensive fine-tuning or lack real-time adaptability. This paper introduces FRASA, a Deep Reinforcement Learning (DRL) agent that integrates fall recovery and stand up strategies into a unified framework. Leveraging the Cross-Q algorithm, FRASA significantly reduces training time and offers a versatile recovery strategy that adapts to unpredictable disturbances. Comparative tests on Sigmaban humanoid robots demonstrate FRASA superior performance against the KFB method deployed in the RoboCup 2023 by the Rhoban Team, world champion of the KidSize League.