Exploring Spatial Representation to Enhance LLM Reasoning in Aerial Vision-Language Navigation
作者: Yunpeng Gao, Zhigang Wang, Pengfei Han, Linglin Jing, Dong Wang, Bin Zhao
分类: cs.RO, cs.AI
发布日期: 2024-10-11 (更新: 2025-08-11)
💡 一句话要点
提出STMR表征,增强LLM在无人机视觉语言导航中的空间推理能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 视觉语言导航 大型语言模型 空间推理 语义拓扑度量表示
📋 核心要点
- 无人机视觉语言导航任务面临复杂空间关系的挑战,现有方法难以有效利用空间信息。
- 论文提出语义-拓扑-度量表示(STMR),将语义信息和空间拓扑结构融入LLM的输入,提升空间推理能力。
- 实验结果表明,该方法在真实和模拟环境中均表现出色,显著提升了导航成功率,尤其在简单任务上提升明显。
📝 摘要(中文)
本文提出了一种用于无人机视觉语言导航(VLN)的免训练、零样本框架,该框架利用大型语言模型(LLM)作为智能体进行动作预测。核心在于开发了一种新颖的语义-拓扑-度量表示(STMR),以增强LLM的空间推理能力。具体而言,该方法提取指令相关的语义掩码,并将其投影到自上而下的地图上,该地图呈现周围地标的空间和拓扑信息,并在导航过程中不断增长。在每一步,从增长的自上而下地图中提取以无人机为中心的局部地图,并将其转换为具有距离度量的矩阵表示,作为文本提示输入LLM,以响应给定的指令进行动作预测。在真实和模拟环境中进行的实验证明了该方法的有效性和鲁棒性,在简单和复杂的导航任务上,绝对成功率分别比当前最先进的方法提高了26.8%和5.8%。数据集和代码即将发布。
🔬 方法详解
问题定义:无人机视觉语言导航(Aerial VLN)任务旨在使无人机能够根据自然语言指令和视觉线索在户外环境中导航。现有的方法在处理复杂空间关系时存在不足,难以充分利用场景中的空间信息进行推理和决策。这限制了无人机在复杂环境中的导航性能。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和推理能力,并结合一种新颖的空间表示方法,即语义-拓扑-度量表示(STMR),来增强LLM在空间推理方面的能力。通过将视觉信息转化为LLM易于理解的文本提示,从而实现更准确的动作预测。
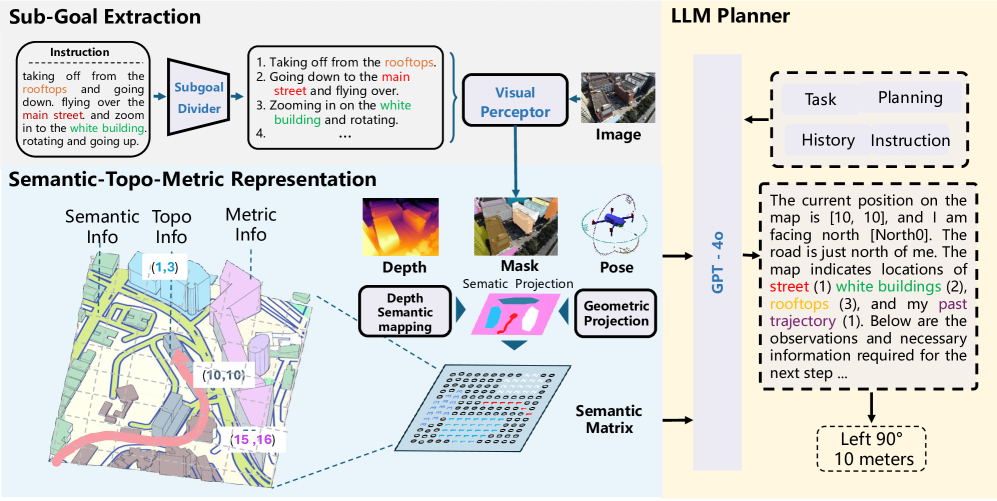
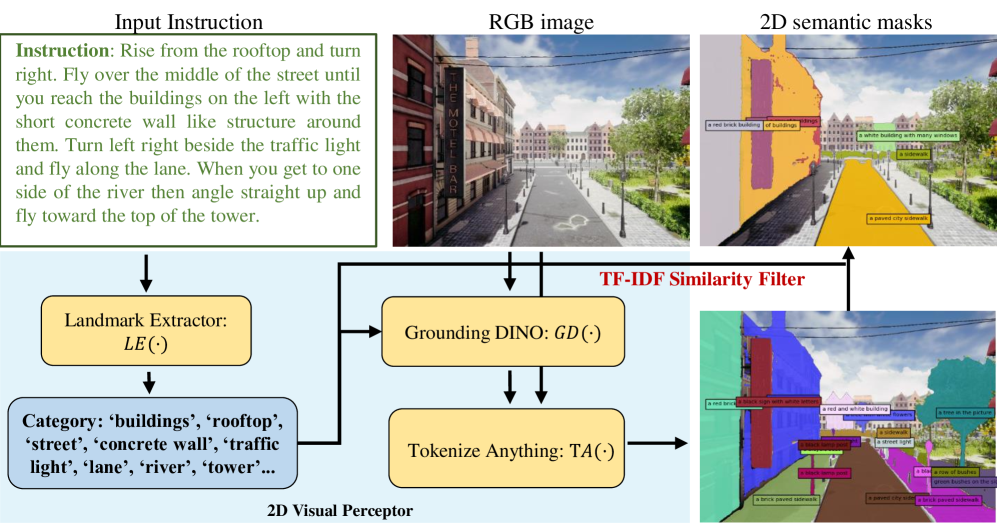
技术框架:整体框架包含以下几个主要步骤:1) 语义掩码提取:从视觉输入中提取与指令相关的语义掩码。2) 自上而下地图构建:将语义掩码投影到自上而下的地图上,构建包含空间和拓扑信息的环境表示。3) 局部地图提取与转换:从自上而下的地图中提取以无人机为中心的局部地图,并将其转换为包含距离度量的矩阵表示。4) LLM动作预测:将矩阵表示作为文本提示输入LLM,LLM根据指令和环境信息预测下一步的动作。
关键创新:最重要的技术创新点在于提出的语义-拓扑-度量表示(STMR)。STMR将视觉信息中的语义、拓扑和度量信息融合在一起,形成一种结构化的空间表示,能够有效地传递给LLM,从而增强LLM的空间推理能力。与现有方法相比,STMR能够更全面地捕捉环境中的空间关系,并将其转化为LLM可以理解的形式。
关键设计:STMR的关键设计包括:1) 语义掩码的提取方法:具体采用何种方法提取语义掩码(例如,使用预训练的分割模型)。2) 自上而下地图的构建方式:如何将语义掩码投影到地图上,以及如何更新地图。3) 局部地图的提取策略:如何确定局部地图的大小和范围。4) 矩阵表示的编码方式:如何将局部地图编码为包含距离度量的矩阵,以及如何将该矩阵作为文本提示输入LLM。这些细节在论文中可能并未详细阐述,需要进一步查阅论文原文或相关代码。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在真实和模拟环境中均取得了显著的性能提升。在简单导航任务上,绝对成功率比当前最先进的方法提高了26.8%;在复杂导航任务上,绝对成功率提高了5.8%。这些结果证明了该方法在无人机视觉语言导航任务中的有效性和鲁棒性。
🎯 应用场景
该研究成果可应用于多种场景,例如:无人机物流配送、环境监测、灾害救援、农业巡检等。通过结合自然语言指令和视觉信息,无人机可以自主地在复杂环境中导航,完成各种任务。该研究还有助于提升无人机在户外环境中的自主性和智能化水平,为无人机技术的进一步发展奠定基础。
📄 摘要(原文)
Aerial Vision-and-Language Navigation (VLN) is a novel task enabling Unmanned Aerial Vehicles (UAVs) to navigate in outdoor environments through natural language instructions and visual cues. However, it remains challenging due to the complex spatial relationships in aerial scenes.In this paper, we propose a training-free, zero-shot framework for aerial VLN tasks, where the large language model (LLM) is leveraged as the agent for action prediction. Specifically, we develop a novel Semantic-Topo-Metric Representation (STMR) to enhance the spatial reasoning capabilities of LLMs. This is achieved by extracting and projecting instruction-related semantic masks onto a top-down map, which presents spatial and topological information about surrounding landmarks and grows during the navigation process. At each step, a local map centered at the UAV is extracted from the growing top-down map, and transformed into a ma trix representation with distance metrics, serving as the text prompt to LLM for action prediction in response to the given instruction. Experiments conducted in real and simulation environments have proved the effectiveness and robustness of our method, achieving absolute success rate improvements of 26.8% and 5.8% over current state-of-the-art methods on simple and complex navigation tasks, respectively. The dataset and code will be released soon.