Constrained Skill Discovery: Quadruped Locomotion with Unsupervised Reinforcement Learning
作者: Vassil Atanassov, Wanming Yu, Alexander Luis Mitchell, Mark Nicholas Finean, Ioannis Havoutis
分类: cs.RO
发布日期: 2024-10-10
💡 一句话要点
提出基于距离约束的无监督强化学习方法,实现四足机器人零样本步态控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 无监督强化学习 技能发现 运动控制 距离约束
📋 核心要点
- 现有无监督技能发现方法在状态空间覆盖方面存在不足,导致机器人学习到的行为多样性受限,难以适应复杂环境。
- 该论文提出一种新的约束技能发现方法,通过范数匹配目标来替代潜在转移最大化,从而提升状态空间覆盖率。
- 实验表明,该方法在真实ANYmal四足机器人上实现了零样本步态控制,能够精确到达笛卡尔坐标系中的目标点。
📝 摘要(中文)
本文提出了一种基于无监督强化学习的约束技能发现方法,旨在使机器人无需任务特定奖励即可获得多样且可重用的行为。该方法通过最大化技能和状态之间的互信息,并施加距离约束,来学习潜在表示。相较于之前的约束技能发现方法,本文用范数匹配目标代替了潜在转移最大化,这不仅显著丰富了状态空间覆盖,还使机器人能够学习更稳定且易于控制的运动行为。实验结果表明,所学策略能够成功部署在真实的ANYmal四足机器人上,并且仅使用内在技能发现和标准正则化奖励,机器人就能以零样本方式精确到达笛卡尔状态空间的任意点。
🔬 方法详解
问题定义:现有的无监督技能发现方法,特别是那些基于最大化潜在空间转移的方法,在四足机器人运动控制中存在状态空间覆盖不足的问题。这意味着机器人探索的行为范围有限,难以学习到足够多样和鲁棒的运动技能,从而限制了其在复杂环境中的适应能力。这些方法通常依赖于最大化相邻时间步之间的潜在状态差异,但这种方式可能导致不稳定或不自然的运动模式。
核心思路:本文的核心思路是通过引入距离约束和范数匹配目标,来鼓励机器人探索更广泛的状态空间,并学习更稳定和可控的运动技能。具体来说,作者不再直接最大化潜在状态的转移,而是设计了一个范数匹配目标,该目标鼓励学习到的潜在表示与期望的运动轨迹的范数相匹配。同时,距离约束确保了学习到的技能能够覆盖一定的状态空间范围,避免机器人陷入局部最优。
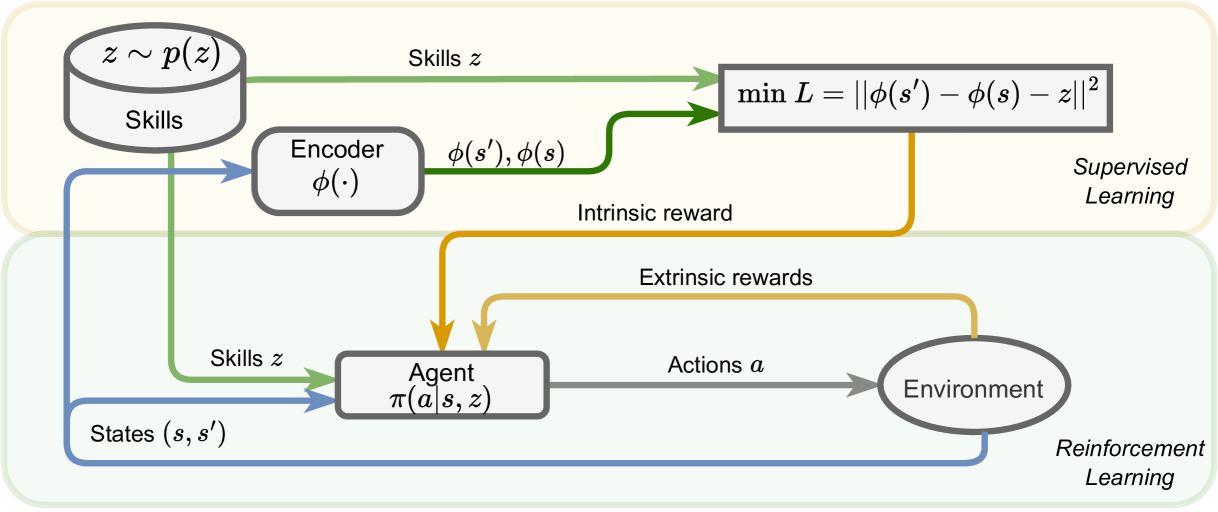
技术框架:该方法基于无监督强化学习框架,主要包含以下几个模块:1) 技能编码器:将潜在技能编码为低维向量。2) 策略网络:根据当前状态和技能向量,输出机器人的动作。3) 奖励函数:由内在奖励(最大化技能和状态之间的互信息)和距离约束组成。4) 训练过程:通过强化学习算法(如SAC),优化策略网络和技能编码器,使得机器人能够学习到多样且可控的运动技能。
关键创新:该方法最重要的创新点在于用范数匹配目标替代了传统的潜在转移最大化。这种改变避免了直接优化潜在状态转移可能导致的不稳定行为,并鼓励机器人学习更平滑和自然的运动模式。此外,距离约束的引入进一步提高了状态空间覆盖率,使得机器人能够探索更广泛的行为空间。
关键设计:该方法的关键设计包括:1) 范数匹配损失:用于鼓励学习到的潜在表示与期望的运动轨迹的范数相匹配。2) 距离约束:用于限制技能之间的距离,确保状态空间被充分覆盖。3) 互信息最大化:用于鼓励技能和状态之间的相关性,使得每个技能都对应于一种特定的行为。4) 使用SAC算法进行训练,以保证策略学习的稳定性和效率。
🖼️ 关键图片

📊 实验亮点
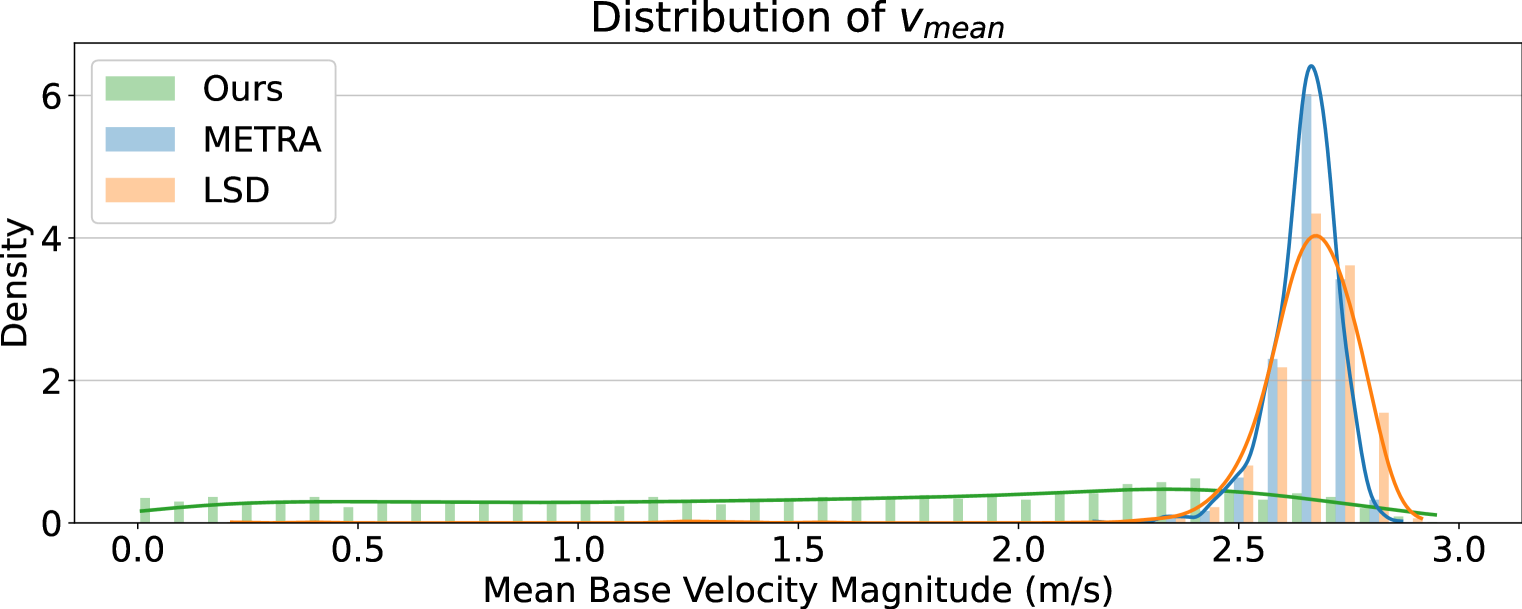
实验结果表明,该方法在真实的ANYmal四足机器人上实现了零样本步态控制,能够精确到达笛卡尔坐标系中的目标点。与基线方法相比,该方法显著提高了状态空间覆盖率,并学习到了更稳定和可控的运动技能。具体而言,机器人能够以更高的精度和更快的速度到达目标点,并且在面对外部干扰时表现出更强的鲁棒性。
🎯 应用场景
该研究成果可应用于各种四足机器人的运动控制,例如搜索救援、物流运输、地形勘探等。通过无监督学习,机器人能够自主探索并学习适应不同环境的运动技能,降低了人工设计和调试运动控制器的成本。此外,该方法还可以扩展到其他类型的机器人和运动任务中,具有广泛的应用前景。
📄 摘要(原文)
Representation learning and unsupervised skill discovery can allow robots to acquire diverse and reusable behaviors without the need for task-specific rewards. In this work, we use unsupervised reinforcement learning to learn a latent representation by maximizing the mutual information between skills and states subject to a distance constraint. Our method improves upon prior constrained skill discovery methods by replacing the latent transition maximization with a norm-matching objective. This not only results in a much a richer state space coverage compared to baseline methods, but allows the robot to learn more stable and easily controllable locomotive behaviors. We successfully deploy the learned policy on a real ANYmal quadruped robot and demonstrate that the robot can accurately reach arbitrary points of the Cartesian state space in a zero-shot manner, using only an intrinsic skill discovery and standard regularization rewards.