G$^{2}$TR: Generalized Grounded Temporal Reasoning for Robot Instruction Following by Combining Large Pre-trained Models
作者: Riya Arora, Niveditha Narendranath, Aman Tambi, Sandeep S. Zachariah, Souvik Chakraborty, Rohan Paul
分类: cs.RO
发布日期: 2024-10-10
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
G²TR:结合预训练模型,实现机器人指令跟随中的广义时序推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人指令跟随 时序推理 空间推理 语义跟踪 预训练模型 视频语言理解
📋 核心要点
- 现有方法难以处理机器人指令跟随任务中,对过去交互行为的多跳引用和复杂场景中的物体定位问题。
- G²TR将时序推理分解为视频片段估计、空间推理和语义跟踪三个步骤,利用预训练模型提升泛化能力。
- 在机器人操作视频语言数据集上的实验表明,G²TR方法达到了70.10%的平均准确率,验证了其有效性。
📝 摘要(中文)
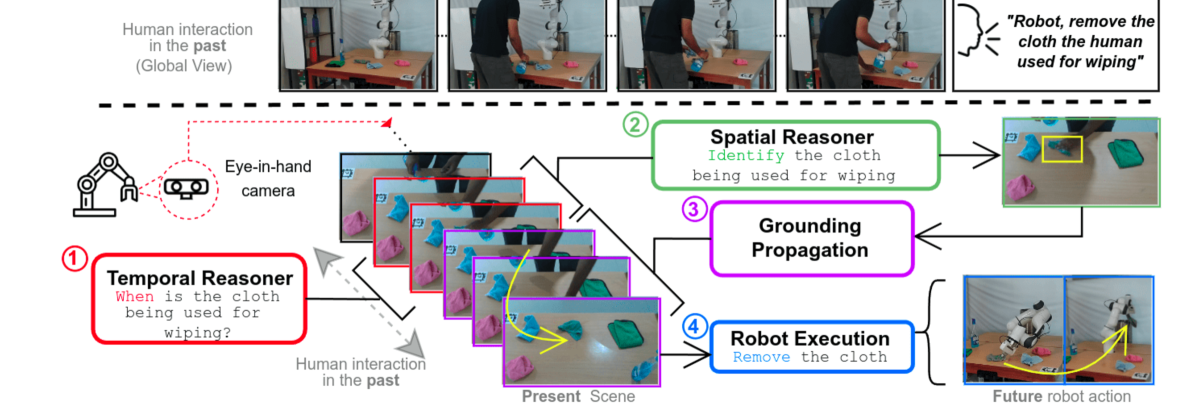
本文提出了一种广义的基于时序推理的机器人指令跟随方法(G²TR)。该方法针对机器人观察人类操作场景并接收指令(例如“用我擦桌子的布把桌子擦干净”)的情况。此类任务需要机器人识别相关的历史交互,定位当前场景中的目标物体,并根据指令执行任务。由于对过去交互的多跳引用以及视频流中物体定位空间巨大,直接将提及过去交互的语句与实际物体进行关联非常困难。本文的核心思想是将时序推理任务分解为:(i) 估计与事件引用相关的视频片段,(ii) 对交互帧进行空间推理以推断目标物体,(iii) 语义跟踪物体的位置直到当前场景,以便进行未来的机器人交互。该方法利用现有的预训练模型(具有内在的泛化能力)并将它们适当地组合用于时序定位任务。在包含空间复杂场景中丰富时序交互的机器人操作视频语言数据集上的评估显示,平均准确率达到70.10%。数据集、代码和视频可在https://reail-iitdelhi.github.io/temporalreasoning.github.io/ 获取。
🔬 方法详解
问题定义:论文旨在解决机器人指令跟随任务中,机器人如何理解并执行包含对过去事件和物体引用的指令。现有方法在处理复杂场景和多跳引用时,难以准确地将指令中的描述与实际的物体和动作关联起来,导致指令执行失败。痛点在于缺乏有效的时序推理和空间定位能力,以及对语言指令的准确理解。
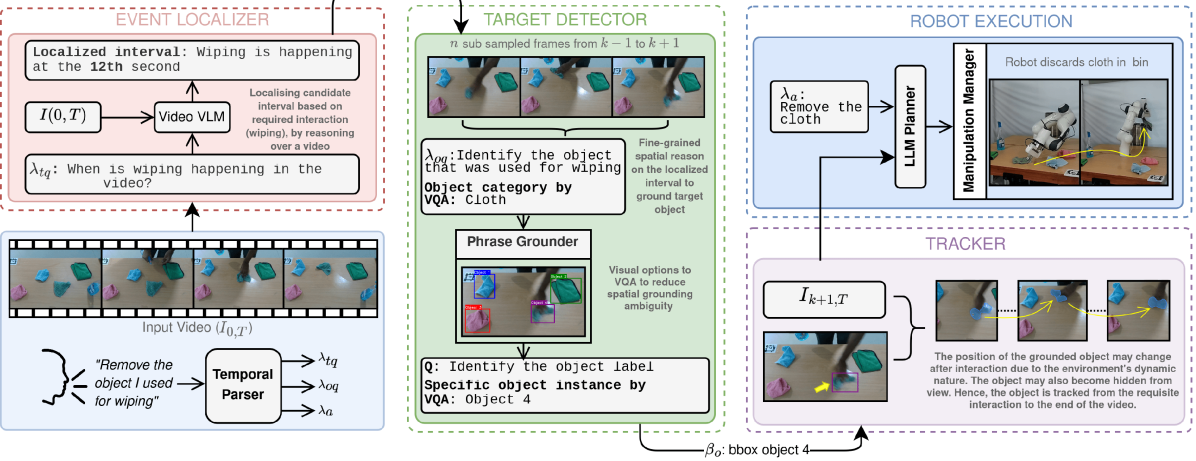
核心思路:论文的核心思路是将复杂的时序推理任务分解为三个可管理的子任务:首先,确定指令中事件引用对应的视频片段;其次,在这些片段中进行空间推理,确定指令中指代的具体物体;最后,对该物体进行语义跟踪,直至当前场景,以便机器人执行后续操作。这种分解降低了问题的复杂度,并允许利用不同的预训练模型来解决各个子任务。
技术框架:G²TR的整体框架包含以下几个主要模块:1) 视频片段估计模块:用于确定指令中事件引用对应的视频片段,可能使用时序动作分割或检索模型。2) 空间推理模块:在估计的视频片段中,通过空间关系推理,确定指令中指代的具体物体,可能使用目标检测或关系推理模型。3) 语义跟踪模块:对识别出的物体进行语义跟踪,直至当前场景,以便机器人执行后续操作,可能使用目标跟踪或状态估计模型。这些模块协同工作,实现对指令的理解和执行。
关键创新:该方法最重要的创新点在于将时序推理任务分解为多个子任务,并利用预训练模型来解决这些子任务。这种方法充分利用了预训练模型的泛化能力,避免了从头开始训练模型的需要,提高了模型的性能和效率。此外,将时序推理、空间推理和语义跟踪相结合,使得机器人能够更好地理解和执行复杂的指令。
关键设计:论文的关键设计可能包括:1) 如何选择和组合不同的预训练模型,例如,使用哪个模型进行视频片段估计,哪个模型进行空间推理,以及哪个模型进行语义跟踪。2) 如何设计损失函数来训练各个模块,例如,使用交叉熵损失函数来训练视频片段估计模块,使用IoU损失函数来训练目标检测模块。3) 如何对各个模块的输出进行融合,例如,使用加权平均或注意力机制来融合各个模块的输出。
🖼️ 关键图片

📊 实验亮点
实验结果表明,G²TR方法在机器人操作视频语言数据集上取得了70.10%的平均准确率。这一结果表明,通过将时序推理任务分解为多个子任务,并利用预训练模型,可以有效地提高机器人指令跟随的性能。具体的基线模型和提升幅度未知,但该结果证明了G²TR方法的有效性。
🎯 应用场景
该研究成果可应用于各种机器人指令跟随场景,例如家庭服务机器人、工业机器人和医疗机器人。通过理解人类的自然语言指令,机器人可以执行更复杂的任务,例如清洁、整理和组装。该技术还可以应用于虚拟助手和智能家居系统,提升人机交互的自然性和智能化水平,具有广阔的应用前景。
📄 摘要(原文)
Consider the scenario where a human cleans a table and a robot observing the scene is instructed with the task "Remove the cloth using which I wiped the table". Instruction following with temporal reasoning requires the robot to identify the relevant past object interaction, ground the object of interest in the present scene, and execute the task according to the human's instruction. Directly grounding utterances referencing past interactions to grounded objects is challenging due to the multi-hop nature of references to past interactions and large space of object groundings in a video stream observing the robot's workspace. Our key insight is to factor the temporal reasoning task as (i) estimating the video interval associated with event reference, (ii) performing spatial reasoning over the interaction frames to infer the intended object (iii) semantically track the object's location till the current scene to enable future robot interactions. Our approach leverages existing large pre-trained models (which possess inherent generalization capabilities) and combines them appropriately for temporal grounding tasks. Evaluation on a video-language corpus acquired with a robot manipulator displaying rich temporal interactions in spatially-complex scenes displays an average accuracy of 70.10%. The dataset, code, and videos are available at https://reail-iitdelhi.github.io/temporalreasoning.github.io/ .