Safe Reinforcement Learning Filter for Multicopter Collision-Free Tracking under disturbances
作者: Qihan Qi, Xinsong Yang, Gang Xia
分类: cs.RO
发布日期: 2024-10-09
💡 一句话要点
提出安全强化学习滤波器,解决多旋翼飞行器在扰动下无碰撞轨迹跟踪问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全控制 控制障碍函数 多旋翼飞行器 轨迹跟踪 鲁棒控制 无人机
📋 核心要点
- 现有强化学习方法在多旋翼飞行器轨迹跟踪中难以保证安全性,尤其是在存在未知扰动时,容易发生碰撞。
- 论文提出安全强化学习滤波器,利用鲁棒控制障碍函数确保系统状态在安全集内,将不安全的强化学习控制输入转化为安全的。
- 仿真和真实实验表明,该方法在存在输入扰动和饱和的情况下,能够有效实现多旋翼飞行器的无碰撞轨迹跟踪。
📝 摘要(中文)
本文提出了一种安全强化学习滤波器(SRLF),以实现多旋翼飞行器在输入扰动下的无碰撞轨迹跟踪。引入了一种新颖的鲁棒控制障碍函数(RCBF)及其分析技术,以避免在跟踪过程中与未知扰动发生碰撞。为了确保系统状态保持在安全集内,RCBF增益在控制动作中设计。引入安全滤波器将不安全的强化学习(RL)控制输入转换为安全的控制输入,从而允许RL训练在不显式考虑安全约束的情况下进行。SRLF通过求解一个二次规划(QP)问题获得严格保证的安全控制动作,该问题结合了RCBF的前向不变性和输入饱和约束。多旋翼飞行器的仿真和真实实验都证明了SRLF在输入扰动和饱和情况下实现无碰撞跟踪的有效性和优异性能。
🔬 方法详解
问题定义:多旋翼飞行器在复杂环境中进行轨迹跟踪时,面临着输入扰动和饱和的挑战,传统的强化学习方法难以保证飞行器的安全性,容易发生碰撞。现有方法通常需要显式地将安全约束纳入强化学习训练过程中,增加了训练的复杂性,且难以应对未知的扰动。
核心思路:论文的核心思路是将强化学习控制输入视为一个潜在的不安全动作,然后通过一个安全滤波器将其修正为安全的控制动作。该安全滤波器基于鲁棒控制障碍函数(RCBF)设计,确保系统状态始终保持在安全集内,从而避免碰撞。这样,强化学习训练可以在不显式考虑安全约束的情况下进行,简化了训练过程。
技术框架:整体框架包含两个主要部分:强化学习控制器和安全滤波器。强化学习控制器负责生成期望的控制输入,安全滤波器则负责将该输入修正为安全的控制输入。安全滤波器通过求解一个二次规划(QP)问题来实现,该QP问题以最小化修正量为目标,同时满足RCBF的前向不变性约束和输入饱和约束。RCBF的设计保证了系统状态始终在安全集内。
关键创新:最重要的技术创新点在于提出了基于鲁棒控制障碍函数(RCBF)的安全滤波器。与传统的控制障碍函数相比,RCBF能够处理未知的输入扰动,保证在扰动存在的情况下系统状态仍然保持在安全集内。此外,该方法将安全约束与强化学习训练解耦,简化了训练过程。
关键设计:RCBF的设计是关键。论文详细分析了RCBF的前向不变性条件,并基于此设计了RCBF的增益。安全滤波器通过求解一个二次规划问题来实现,该QP问题的目标函数是最小化修正量,约束条件包括RCBF的前向不变性约束和输入饱和约束。强化学习控制器的具体结构和训练方法可以根据具体应用场景选择。
🖼️ 关键图片


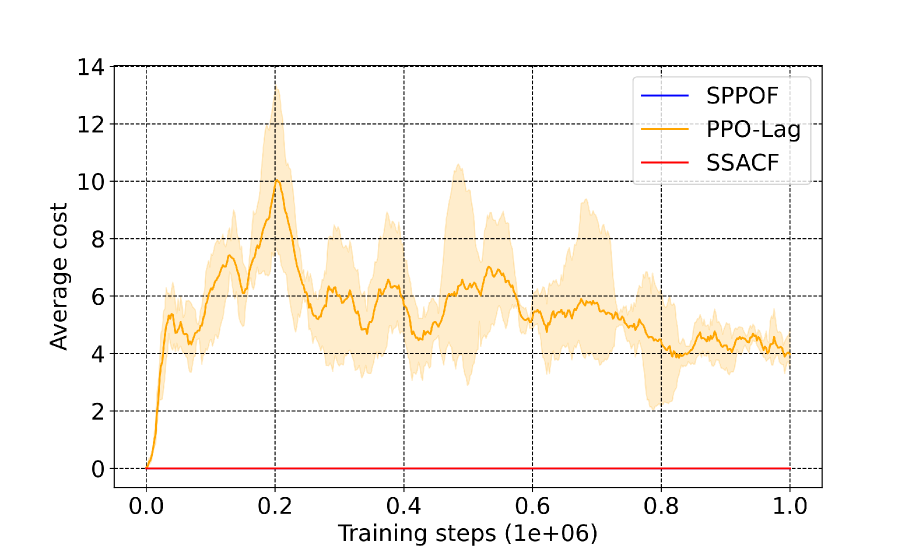
📊 实验亮点
论文通过仿真和真实实验验证了SRLF的有效性。实验结果表明,在存在输入扰动和饱和的情况下,SRLF能够保证多旋翼飞行器安全地跟踪目标轨迹,避免碰撞。与没有安全滤波器的强化学习控制相比,SRLF显著提高了系统的安全性,且性能损失较小。具体性能数据未知,但实验结果表明SRLF在实际应用中具有良好的效果。
🎯 应用场景
该研究成果可应用于无人机物流、无人机巡检、无人机测绘等领域。通过安全强化学习滤波器,可以提高无人机在复杂环境下的自主飞行能力和安全性,降低碰撞风险,提升任务完成效率。未来,该技术有望推广到其他机器人系统,如自动驾驶汽车、移动机器人等。
📄 摘要(原文)
This paper proposes a safe reinforcement learning filter (SRLF) to realize multicopter collision-free trajectory tracking with input disturbance. A novel robust control barrier function (RCBF) with its analysis techniques is introduced to avoid collisions with unknown disturbances during tracking. To ensure the system state remains within the safe set, the RCBF gain is designed in control action. A safety filter is introduced to transform unsafe reinforcement learning (RL) control inputs into safe ones, allowing RL training to proceed without explicitly considering safety constraints. The SRLF obtains rigorous guaranteed safe control action by solving a quadratic programming (QP) problem that incorporates forward invariance of RCBF and input saturation constraints. Both simulation and real-world experiments on multicopters demonstrate the effectiveness and excellent performance of SRLF in achieving collision-free tracking under input disturbances and saturation.