Disturbance Observer-based Control Barrier Functions with Residual Model Learning for Safe Reinforcement Learning
作者: Dvij Kalaria, Qin Lin, John M. Dolan
分类: cs.RO
发布日期: 2024-10-09
💡 一句话要点
提出基于扰动观测器和残差模型学习的控制屏障函数安全强化学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 控制屏障函数 扰动观测器 残差模型学习 机器人控制 模型不确定性 外部扰动
📋 核心要点
- 现有强化学习方法在真实系统上训练存在安全风险,而仿真训练则面临着“仿真-现实”差距的挑战。
- 该论文提出了一种基于扰动观测器和残差模型学习的控制屏障函数方法,以提高强化学习的安全性。
- 在Safety-gym和物理F1/10赛车实验中,该方法优于仅使用残差模型学习或扰动观测器的现有技术。
📝 摘要(中文)
强化学习(RL)智能体需要在环境中探索以学习最优行为并获得最大奖励。然而,直接在真实系统上训练RL可能存在风险,而基于仿真的训练又面临着从仿真到现实的差距问题。最近的方法利用安全滤波器,例如控制屏障函数(CBF),来惩罚RL训练期间的不安全行为。但是,CBF的强大安全保证依赖于精确的动态模型。在实践中,不确定性总是存在,包括来自动态误差的内部扰动和诸如风之类的外部扰动。在这项工作中,我们提出了一种新的基于扰动抑制的安全强化学习框架,该框架允许使用假定的但不一定精确的标称动态模型的几乎无模型的RL。我们在Safety-gym基准测试中针对Point和Car机器人展示了我们的结果,在所有任务中,我们都可以胜过仅使用残差模型学习或扰动观测器(DOB)的最新方法。我们进一步使用物理F1/10赛车验证了我们框架的有效性。
🔬 方法详解
问题定义:强化学习在实际应用中,尤其是在机器人控制领域,面临着安全挑战。传统的控制屏障函数(CBF)依赖于精确的系统动态模型,但在实际环境中,模型不确定性(内部扰动)和外部扰动普遍存在,导致CBF失效,无法保证安全。现有方法如残差模型学习或扰动观测器(DOB)虽然能缓解部分问题,但仍存在局限性,无法同时有效处理模型不确定性和外部扰动。
核心思路:该论文的核心思路是将扰动观测器(DOB)和残差模型学习相结合,并融入控制屏障函数(CBF)框架中。DOB用于估计和补偿外部扰动,残差模型学习用于补偿模型不确定性,CBF则作为安全约束,确保在学习过程中智能体的行为保持安全。通过这种方式,即使在模型不精确和存在扰动的情况下,也能保证强化学习的安全性。
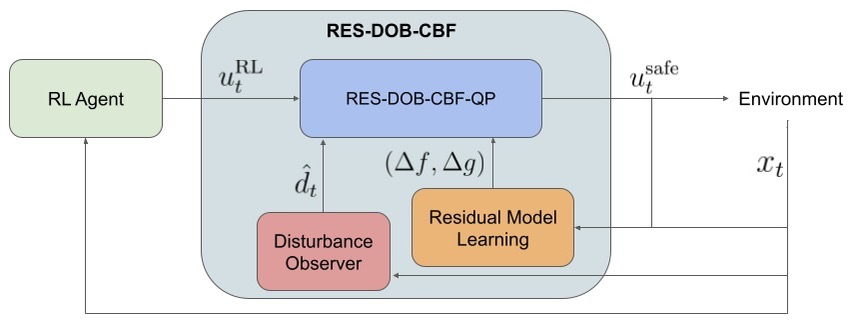
技术框架:该框架包含以下几个主要模块:1) 强化学习智能体:负责学习最优策略;2) 扰动观测器(DOB):用于估计和补偿外部扰动;3) 残差模型学习:用于学习模型不确定性;4) 控制屏障函数(CBF):作为安全约束,限制智能体的行为,防止进入不安全状态。整体流程是:智能体根据当前状态选择动作,DOB估计外部扰动并进行补偿,残差模型学习补偿模型不确定性,CBF检查动作是否安全,如果不安全则进行修正,最终执行修正后的安全动作。
关键创新:该论文的关键创新在于将扰动观测器、残差模型学习和控制屏障函数有效地结合在一起,形成一个完整的安全强化学习框架。与现有方法相比,该方法能够同时处理模型不确定性和外部扰动,从而提高了强化学习的鲁棒性和安全性。此外,该方法允许使用一个不一定精确的标称动态模型,降低了对模型精确度的要求。
关键设计:论文中,扰动观测器采用经典的设计,用于估计外部扰动。残差模型学习通过神经网络学习标称模型与真实模型之间的残差。控制屏障函数的设计需要根据具体的安全约束进行调整,例如,保持与障碍物的距离。损失函数包括强化学习的奖励函数和CBF相关的惩罚项,用于平衡性能和安全性。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在Safety-gym基准测试中,针对Point和Car机器人,在多个任务上均优于仅使用残差模型学习或扰动观测器的现有方法。此外,在物理F1/10赛车上的实验验证了该框架在真实环境中的有效性,证明了其良好的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、无人机等领域,尤其是在安全至关重要的场景中。例如,在自动驾驶中,可以利用该框架保证车辆在复杂环境下的行驶安全;在机器人控制中,可以保证机器人在执行任务时避免碰撞和损坏。该研究有助于推动强化学习在实际应用中的落地。
📄 摘要(原文)
Reinforcement learning (RL) agents need to explore their environment to learn optimal behaviors and achieve maximum rewards. However, exploration can be risky when training RL directly on real systems, while simulation-based training introduces the tricky issue of the sim-to-real gap. Recent approaches have leveraged safety filters, such as control barrier functions (CBFs), to penalize unsafe actions during RL training. However, the strong safety guarantees of CBFs rely on a precise dynamic model. In practice, uncertainties always exist, including internal disturbances from the errors of dynamics and external disturbances such as wind. In this work, we propose a new safe RL framework based on disturbance rejection-guarded learning, which allows for an almost model-free RL with an assumed but not necessarily precise nominal dynamic model. We demonstrate our results on the Safety-gym benchmark for Point and Car robots on all tasks where we can outperform state-of-the-art approaches that use only residual model learning or a disturbance observer (DOB). We further validate the efficacy of our framework using a physical F1/10 racing car. Videos: https://sites.google.com/view/res-dob-cbf-rl