Context-Aware Command Understanding for Tabletop Scenarios
作者: Paul Gajewski, Antonio Galiza Cerdeira Gonzalez, Bipin Indurkhya
分类: cs.RO, cs.AI
发布日期: 2024-10-08 (更新: 2024-10-10)
💡 一句话要点
提出一种上下文感知混合算法,用于理解桌面场景中的自然语言指令。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 自然语言理解 多模态融合 机器人控制 上下文感知 零样本学习 桌面场景
📋 核心要点
- 现有方法难以有效融合语音、手势和场景上下文等多模态信息,导致机器人难以准确理解人类指令。
- 该论文提出一种混合算法,整合多模态信息,以零样本方式提取机器人可执行的指令,无需预定义对象模型。
- 实验结果表明,该算法在不同任务中表现出强大的性能,能够有效结合语言处理与视觉基础。
📝 摘要(中文)
本文提出了一种新颖的混合算法,旨在解释桌面场景中的自然人类指令。该系统通过整合语音、手势和场景上下文等多源信息,提取机器人可执行的指令,识别相关对象和动作。该系统以零样本方式运行,不依赖于预定义的对象模型,从而能够在各种环境中实现灵活和自适应的使用。我们评估了多个深度学习模型的集成,评估了它们在真实机器人设置中部署的适用性。我们的算法在不同的任务中表现出强大的性能,将语言处理与视觉基础相结合。此外,我们发布了一个小型视频录制数据集,用于评估该系统。该数据集捕捉了真实世界的交互,其中人类用自然语言向机器人提供指令,为未来人机交互研究做出贡献。我们讨论了该系统的优势和局限性,特别关注它如何处理多模态命令解释,以及它如何集成到符号机器人框架中以实现安全和可解释的决策。
🔬 方法详解
问题定义:该论文旨在解决机器人如何在桌面场景中准确理解人类自然语言指令的问题。现有方法通常依赖于预定义的对象模型或单一模态的信息,难以处理复杂场景和多变的指令方式,导致机器人无法准确识别指令中的对象和动作,从而影响任务执行的效率和可靠性。
核心思路:论文的核心思路是利用混合算法,融合语音、手势和场景上下文等多模态信息,从而更全面地理解人类指令。通过上下文感知,系统能够消除歧义,准确识别指令中的对象和动作,并生成机器人可执行的指令。零样本学习的引入,使得系统无需预先训练特定对象模型,提高了系统的泛化能力和适应性。
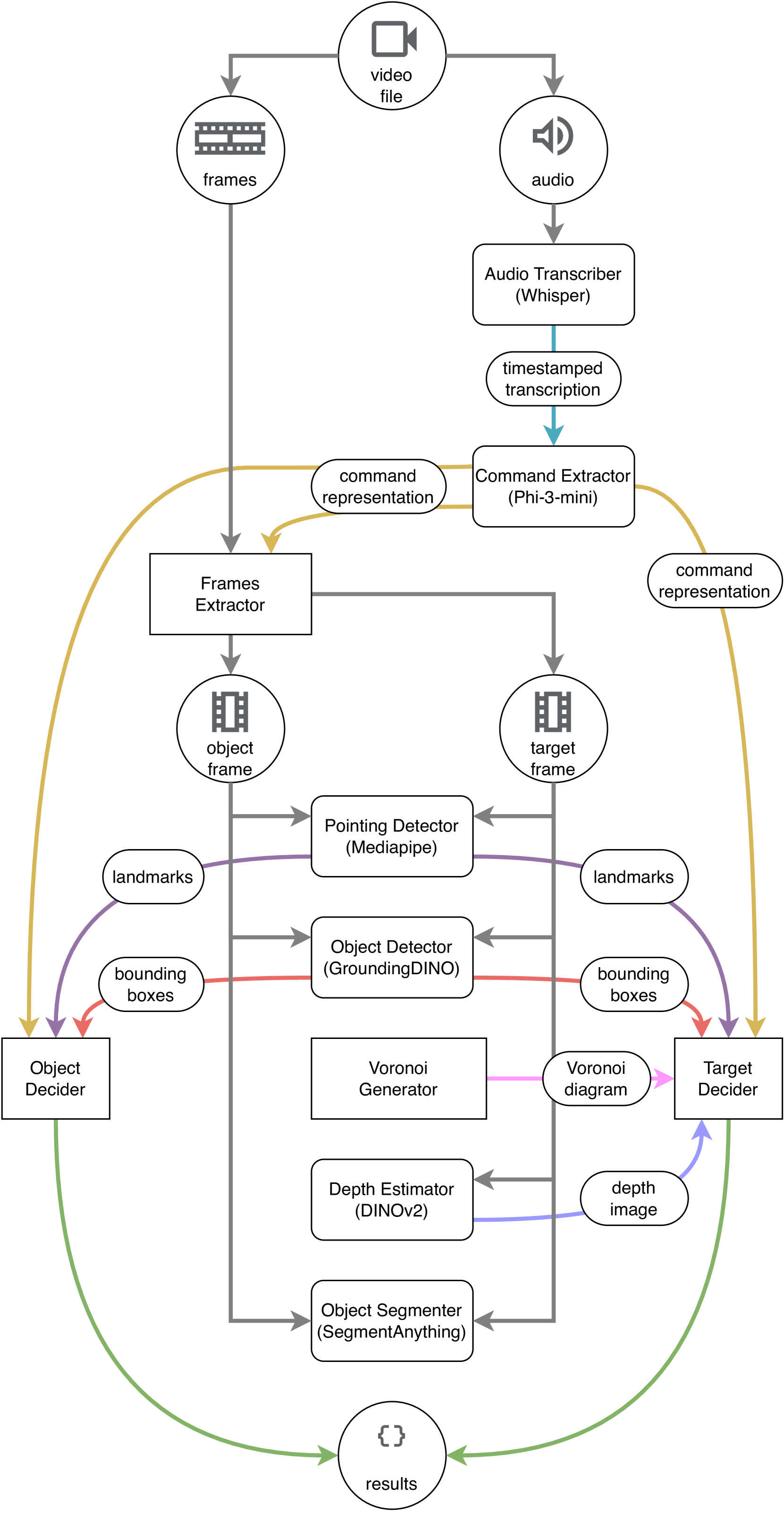
技术框架:该系统整体架构包含以下几个主要模块:1) 多模态数据采集模块,负责采集语音、手势和视觉信息;2) 特征提取模块,利用深度学习模型从不同模态的数据中提取特征;3) 上下文理解模块,融合多模态特征,利用上下文信息消除歧义,识别指令中的对象和动作;4) 指令生成模块,将识别出的对象和动作转化为机器人可执行的指令。
关键创新:该论文的关键创新在于多模态信息的融合和零样本学习的应用。通过整合语音、手势和场景上下文等多模态信息,系统能够更全面地理解人类指令,提高指令理解的准确性。零样本学习使得系统无需预先训练特定对象模型,提高了系统的泛化能力和适应性,使其能够在各种环境中灵活使用。
关键设计:论文中未明确给出关键参数设置、损失函数、网络结构等技术细节,这些信息属于未知内容。但可以推测,特征提取模块可能使用了预训练的深度学习模型,如BERT或ResNet,损失函数可能采用了交叉熵损失或对比损失,用于优化模型参数。
🖼️ 关键图片

📊 实验亮点
论文发布了一个小型视频录制数据集,用于评估系统性能,该数据集捕捉了真实世界人机交互场景,其中人类用自然语言向机器人提供指令。虽然论文中没有给出具体的性能数据和对比基线,但强调了该算法在不同任务中表现出强大的性能,能够有效结合语言处理与视觉基础。
🎯 应用场景
该研究成果可应用于各种人机协作场景,例如智能家居、工业机器人、医疗辅助等。通过自然语言指令,用户可以方便地控制机器人完成各种任务,提高工作效率和生活质量。该技术还有助于开发更智能、更人性化的机器人,促进人机和谐共处。
📄 摘要(原文)
This paper presents a novel hybrid algorithm designed to interpret natural human commands in tabletop scenarios. By integrating multiple sources of information, including speech, gestures, and scene context, the system extracts actionable instructions for a robot, identifying relevant objects and actions. The system operates in a zero-shot fashion, without reliance on predefined object models, enabling flexible and adaptive use in various environments. We assess the integration of multiple deep learning models, evaluating their suitability for deployment in real-world robotic setups. Our algorithm performs robustly across different tasks, combining language processing with visual grounding. In addition, we release a small dataset of video recordings used to evaluate the system. This dataset captures real-world interactions in which a human provides instructions in natural language to a robot, a contribution to future research on human-robot interaction. We discuss the strengths and limitations of the system, with particular focus on how it handles multimodal command interpretation, and its ability to be integrated into symbolic robotic frameworks for safe and explainable decision-making.